当前位置:网站首页>Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving 论文阅读
Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving 论文阅读
2022-06-10 12:28:00 【感天动地大白狗】
1 速读
1.1 论文试图解决什么问题?这是否是一个新的问题?
动态自动驾驶场景下的3D语义目标追踪
1.2 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
以后在动态SLAM汇总处整理;
1.3 文章的贡献是什么?
①轻量的3D box推断方法,结合2D box和视点筛选方法viewpoint classification;
②结合语义和特征信息的BA方法;
1.4 文章解决方案的关键是什么
引入一个viewpoint classification方法直接从2D框得到粗糙初始位姿,然后在后端中优化完成动态追踪;
1.5 实验如何设计?实验结果足够论证其效果吗?
①展示了几个具体场景下的实验结果;
②和ORBSLAM2比较ego motion效果:误差选用RPE和ATE的RMSE;
静态场景和ORBSLAM2差不多,动态场景效果很好;
③和3DOP比较multi object tracking效果;
列出了算法在不同阈值设定下True Positive和平均定位误差两个维度上的比较;
列出了和3DOP在鸟瞰图以及3Dbox的Average precision比较;
1.6 数据集是什么?
KITTI和Cityscapes
1.7 还会存在什么问题
1.大型车辆的数据没有建模;
2.object的重识别(作者在conclution中也提到,提高目标的时间相关性质)
3.相机位姿首先是使用静态部分计算的并没有结合动态部分,会有问题
2 主要内容

上图:相机的3D轨迹和历史object轨迹,可以看出来
①object只在画面内时存在感知行为;
②车辆侧面的动态轨迹都很短,大概是因为与侧边车辆不断超越与被超越导致object一直被新建;
下图:从左到右为stereo特征匹配;画面边缘的车辆(忽然闯入或即将被超越)可以完成跟踪;通过object BA恢复的对象稀疏特征;动态运动跟踪;
可以看出:
①大客车没有被跟踪;
②最后一张图边缘的银色车辆也没有被跟踪,对边缘车辆感知的效果需要check
2.1 系统框架

三个模块:
①2D目标检测+viewpoint classification,其中viewpoint classification的功能是对原网络加了一层FC完成的根据2D框边界和3D box顶点粗略估计物体位姿;
②特征提取和匹配模块,将3D框投影至画面得到mask,进行ORB特征匹配和基于mask的object匹配;
③紧耦合优化方法融合语义信息和特征信息,结合运动学模型得到object运动估计;
2.2 Viewpoint Classification and 3D Box Inference
基于2D bounding box做3D bounding box及其位姿的初始计算(因为2D的检测相对直接3D会更准确)
网络会输出对车辆水平方向(8个,下图中左边)和垂直方向(2个,下图中右边)的viewpoints,两个方向共组成16种情况,表示相机对车辆的大致观测角度;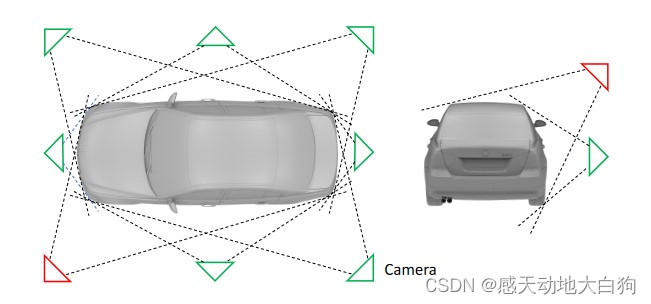
假定(个人推测):
①检测的2D box是刚好包住3D bounding box在画面上的投影区域的,这时顶点会在2D box上;
②车辆的长宽高固定;
③车辆只有水平旋转;
此时会有四个等式表示bounding box上顶点的投影关系:
{ u m i n = π ( p + R θ C 1 d ) u , u m a x = π ( p + R θ C 2 d ) u , v m i n = π ( p + R θ C 3 d ) v , v m a x = π ( p + R θ C 4 d ) v , \left\{ \begin{aligned} u_{min} = \pi(p+R_\theta C_1d)_u, u_{max} = \pi(p+R_\theta C_2d)_u,\\ v_{min} = \pi(p+R_\theta C_3d)_v, v_{max} = \pi(p+R_\theta C_4d)_v, \end{aligned} \right. { umin=π(p+RθC1d)u,umax=π(p+RθC2d)u,vmin=π(p+RθC3d)v,vmax=π(p+RθC4d)v,由此可以解出用四自由度表示的位姿(空间位置3维+水平旋转1维,不考虑车另外两个方向的旋转,妙啊,可是如何解决路面变化导致的车辆另两个方向的旋转呢?)
2.3 Feature Extraction and Matching
区域生成:
①将3D bounding box到stereo图像中生成mask区域;
②存在重叠部分根据深度判断哪个是invisible;
③不够恢复3D bounding box(突然闯入画面中或即将被超越的车辆看不到所需的4个顶点),直接将左目中提取的投影到右目;
匹配:
①左右目提取ORB特征点;
②帧间object匹配使用2D框similarity score voting(中心距离+形状相似性,但是我实在理解不了怎么用2D框做动态下的object匹配的);
③背景+匹配object间的特征匹配;
2.4 Ego-motion and Object Tracking
某一时刻下的观测关系如下
语义观测: s k t = { b k l t , b k r t , l k , C k 1 : 4 t } s_k^t = \{b_{kl}^t,b_{kr}^t,l_k,C_{k\ 1:4}^t\} skt={ bklt,bkrt,lk,Ck 1:4t}(2Dbox的两个顶点+object标签+计算顶点的矩阵);
S = { s k } k = 1 : K t , s k = { s k t } t = 0 : T \mathcal{S}=\{s_k\}_{k=1:K_t},s_k=\{s_k^t\}_{t=0:T} S={ sk}k=1:Kt,sk={ skt}t=0:T 第k个物体在时刻t的观测;
特征点观测: n z k t = { n z k l t , n z k r t } ^nz_k^t = \{^nz_{kl}^t,{^nz_{kr}^t}\} nzkt={ nzklt,nzkrt}(第k个物体的第n个特征点在时刻t的左右目观测);
Z = { z k } k = 0 : K t , z k = { n z k } n = 0 : N k , n z k = { n z k t } t = 0 : T \mathcal{Z} = \{z_k\}_{k=0:K_t},z_k=\{^nz_k\}_{n=0:N_k},^nz_k=\{^nz_k^t\}_{t=0:T} Z={ zk}k=0:Kt,zk={ nzk}n=0:Nk,nzk={ nzkt}t=0:T 第k个物体的第n个点在时刻t的观测;
相机位姿: w x c t = { w p c t , w R c t } ^wx_c^t = \{^wp_c^t,{^wR_c^t}\} wxct={ wpct,wRct};
相机运动: w X c = { w x c t } t = 0 : T ^w\mathcal{X}_c=\{^wx_c^t\}_{t=0:T} wXc={ wxct}t=0:T; 相机在时刻t的位姿;
object位姿: w x o k t = { w p o k t , d k , w θ o k t , v o k t , δ o k t } ^wx_{ok}^t = \{^wp_{ok}^t,d_k,^w\theta_{ok}^t,v_{ok}^t,\delta_{ok}^t\} wxokt={ wpokt,dk,wθokt,vokt,δokt}(第k个物体在时刻t,位置+时不变维数d+水平角度θ+速度v+车轮转向角度δ);不太理解这个d的意义;
object运动: w X o = { w x o k } k = 1 : K t , w x o k = { w x o k t } t = 0 : T ^w\mathcal{X}_o=\{^wx_{ok}\}_{k=1:K_t}, ^wx_{ok} = \{^wx_{ok}^t\}_{t=0:T} wXo={ wxok}k=1:Kt,wxok={ wxokt}t=0:T; 第k个物体在时刻t的位姿;
动态点位置: F = { k f } k = 0 : K t , k f = { k f n } n = 0 : N k \mathcal{F}=\{^kf\}_{k=0:Kt},{^kf=\{^kf_n\}_{n=0:N_k}} F={ kf}k=0:Kt,kf={ kfn}n=0:Nk,表示第k个object的第n个动态点;
任务:给定语义观测和特征点观测,估计相机和objec运动;
a.Ego-motion Tracking
用静态部分计算相机位姿,此时是没有考虑动态的,会有问题;
b.Semantic Object Tracking
最后误差分为:特征投影误差+2D box对3D bounding box构成的约束误差+object运动误差+维度先验误差(三维尺度误差);
①特征投影误差(匹配的object间相对于计算得到的相机位姿的误差),表示object上点投影到左右目的误差:
r Z ( n z k t , w x c t , w x o k t , k f n ) = [ π ( h − 1 ( w x c t , h ( w x o k t , k f n ) ) ) − n z k l t π ( h ( r x l , h − 1 ( w x c t , h ( w x o k t , k f n ) ) ) ) − n z k r t ) ] r_{\mathcal{Z}}(^nz_k^t,\ ^wx_c^t,\ ^wx_{ok}^t,\ ^kf_n) = \begin{bmatrix} \pi(h^{-1}(^wx_c^t, h(^wx_{ok}^t,\ ^kf_n)))-{^nz_{kl}^t}\\ \pi(h(^rx_l, h^{-1}(^wx_c^t, h(^wx_{ok}^t,\ ^kf_n))))-{^nz_{kr}^t}) \end{bmatrix} rZ(nzkt, wxct, wxokt, kfn)=[π(h−1(wxct,h(wxokt, kfn)))−nzkltπ(h(rxl,h−1(wxct,h(wxokt, kfn))))−nzkrt)]②2D box观测误差:假定仍然符合网络给出的viewpoint结果,并且3D bounding box的顶点投影仍然在2D box上;即3D bounding box的位姿应该尽量符合给出的2D box:
r S ( s k t , w x c t , w x o k t , d k ) = [ π ( h c 1 ) u − ( b k l t ) u π ( h c 2 ) u − ( b k r t ) u π ( h c 3 ) v − ( b k l t ) v π ( h c 4 ) u − ( b k r t ) v ] r_{\mathcal{S}}(s_k^t, ^wx_c^t, ^wx_{ok}^t,d_k) = \begin{bmatrix}\pi(h_{c_1})_u-(b_{kl}^t)_u\\ \pi(h_{c_2})_u-(b_{kr}^t)_u \\ \pi(h_{c_3})_v-(b_{kl}^t)_v \\ \pi(h_{c_4})_u-(b_{kr}^t)_v \end{bmatrix} rS(skt,wxct,wxokt,dk)=⎣⎢⎢⎡π(hc1)u−(bklt)uπ(hc2)u−(bkrt)uπ(hc3)v−(bklt)vπ(hc4)u−(bkrt)v⎦⎥⎥⎤ h c i = h − 1 ( w x c t , h ( w x o k t , C i d k l ) ) h_{c_i} = h^{-1}(^wx_c^t, h(^wx_{ok}^t,C_id_k^l)) hci=h−1(wxct,h(wxokt,Cidkl))③车辆运动学模型在匀速假设下的误差:
运动学模型如下:
w x ^ o k t = [ w p o k t w θ o k t δ o k t v o k t ] = [ I 3 × 3 , o , o , Λ o , 1 , 0 , t a n ( δ ) Δ t L o , 0 , 1 , 0 0 , 0 , 0 , 1 ] [ w p o k t − 1 w θ o k t − 1 δ o k t − 1 v o k t − 1 ] , Λ = [ c o s ( θ ) Δ t s i n ( θ ) Δ t 0 ] ^w\hat{x}_{ok}^t = \begin{bmatrix} ^wp_{ok}^t \\ ^w\theta_{ok}^t \\ \delta_{ok}^t \\ v_{ok}^t \end{bmatrix} = \begin{bmatrix} I_{3\times3}, & o, & o, & \Lambda \\ o, & 1, & 0, & \frac{tan(\delta)\Delta t}{L} \\ o, & 0, & 1, & 0 \\ 0, & 0, & 0, & 1 \end{bmatrix} \begin{bmatrix} ^wp_{ok}^{t-1} \\ ^w\theta_{ok}^{t-1} \\ \delta_{ok}^{t-1} \\ v_{ok}^{t-1} \end{bmatrix},\ \Lambda = \begin{bmatrix}cos(\theta)\Delta t \\ sin(\theta)\Delta t \\ 0\end{bmatrix} wx^okt=⎣⎢⎢⎡wpoktwθoktδoktvokt⎦⎥⎥⎤=⎣⎢⎢⎡I3×3,o,o,0,o,1,0,0,o,0,1,0,ΛLtan(δ)Δt01⎦⎥⎥⎤⎣⎢⎢⎡wpokt−1wθokt−1δokt−1vokt−1⎦⎥⎥⎤, Λ=⎣⎡cos(θ)Δtsin(θ)Δt0⎦⎤根据运动学模型可以根据车辆上一帧的位置推断下一帧的位置,误差为:
r M ( w x o k t , w x p k t − 1 ) = w x o k t − w x ^ o k t r_{\mathcal{M}}(^wx_{ok}^t, {^wx_{pk}^{t-1}}) = {^wx_{ok}^t} -{^w\hat{x}_{ok}^t} rM(wxokt,wxpkt−1)=wxokt−wx^okt④维度先验误差:好像是每个物体的三维尺寸误差
r P ( d k l , d k ) r_{\mathcal{P}}(d_k^l, d_k) rP(dkl,dk)经过上述误差后,可以得到符合最大后验估计的object位姿,此时将3Dbox和恢复的点云对齐,即使得3D点云到3Dbox整体距离最小:
w x o k t = a r g m i n w x o k t ∑ n = 0 N k d ( w x o k t , k f n ) ^wx_{ok}^t = \underset{^wx_{ok}^t}{argmin}\sum_{n=0}^{N_k}d(^wx_{ok}^t, {^kf_n}) wxokt=wxoktargminn=0∑Nkd(wxokt,kfn)
3 实验
3.1 实验效果

上半部分划蓝色圈的车辆跟踪了超过200米,轨迹为右上角的紫色曲线;
下半部分为高动态场景,左边为轨迹和速度图,雷达数据只是为了可视化;
其他场景,可以看到是有针对行人的检测的,但是并没有追踪行人
3.2 ego-motion
和ORBSLAM比较,左边是RPEt和RPEr,右边是raw数据下的ATE
3.3 Object Localization Evaluation
将数据分为三个难度,比较不同IoU阈值下,平均position error和True positive两个指标纸币之间的关系,所有观测结果(TP=1)的平均误差大小分别为5.9%, 6.1% 和6.3%;
和3DOP比较,鸟瞰图和3D box的Average precision比较,做了消融实验,只选了两种阈值;
在3D+0.5阈值时略差于3DOP;
问题
1.运动学模型(kinematics model)是怎么用进来的?
在优化阶段有一个根据运动学模型推导的匀速误差
2.viewpoint classification直接分成16类合理吗?
合理,因为这里只想要从2D box快速得到3D box及其位姿,这里位姿是粗糙的会在后面优化;
边栏推荐
- SLM4054独立线性锂电池充电器的芯片的学习
- H5 pop up prompt layer - top, bottom, left and right center
- Oceanbase, phase II of the document promotion plan, invites you to jointly build documents
- GIMP - 免费开源的图像处理软件,功能强大,被称为 Photoshop 的优秀替代品
- Software project management 6.10 Cost budget
- 阿里云ECS服务器搭建Mysql数据库
- UML类图
- 【移动机器人】轮式里程计原理
- Stm32f407 learning notes (1) -exti interrupt event and NVIC register
- 大牛推荐,吊打面试官
猜你喜欢

Shadergraph - 303 swaying grass

Web development

蚂蚁金服杨军:蚂蚁数据分析平台的演进及数据分析方法的应用

文档提升计划第二期|OceanBase 邀您一起进行文档共建

(十 一)const修飾成員函數

(十)空指针访问成员函数与this指针注意事项

STM32 learning notes (2) -usart (basic application 1)

JS将阿拉伯数字翻译成中文的大写数字、JS将数字转换为大写金额(整理)

What if the xshell evaluation period has expired? Follow the steps below to solve the problem!

数字经济时代,零售实体门店该何去何从
随机推荐
使用SoapUI工具生成发送短信接口代码
(十 一)const修飾成員函數
js数组去重:二维数组去重、去除相同的值、移除相同的数组
JS translates Arabic numerals into Chinese capital figures, JS converts figures into capital amounts (sorting)
Oceanbase, phase II of the document promotion plan, invites you to jointly build documents
ASP.NET 利用ImageMap控件设计导航栏
【严选】,真题解析
STM32F407时钟树与系统时钟学习笔记
ShaderGraph——301跳动的小球
软件项目管理 6.10.成本预算
Driver. JS - open source and independent interactive guidance tool library for web novices, powerful and highly customizable
(6) Classes and objects, object initialization and copy constructors (3)
excel异步导出
Web design and development, efficient web development
2022年浙江省赛
PCB学习笔记(2)-3D封装相关
js数组转json 、json转数组。数组转逗号隔开字符串、字符串转数组
Give root password for maintenace (or press Control-D to continue):解决方法
Before we learn about high-performance computing, let's take a look at its history
用C语言创建基本的栈与队列