当前位置:网站首页>简单的爬虫框架:解析51job页面岗位信息
简单的爬虫框架:解析51job页面岗位信息
2022-06-12 14:52:00 【苏木George】
爬虫介绍:
什么是爬虫
爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。
爬虫框架
####文件目录
- datas目录:下存放原始数据
- handle_data目录:下存放经过清洗后的数据
- spider目录:存放爬虫相关的文件
- my_spider:爬虫源文件
- pipo_line:xml解析源文件
- utils:工具文件
- file_tools:文件相关的处理方法
- producter_51job:根据配置文件产生url
- spider:配置文件
- run.py:开始文件
- start.py :爬虫的总流程调用

相关知识背景
用到的包或库
requests:
Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库。
它比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。
一句话—Python实现的简单易用的HTTP库。
def getHtml(url):
"""
:param url: 想要爬取的网址地址
:return: 源文件和编码格式
"""
# 让机器访问网址,模拟浏览器访问,具体请求头,可以在谷歌浏览器F12进入检查模式可以查看
# 一下就是各种机型访问网站的的标志
agents = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
]
# 模拟一个请求头,由下面的字典组成,random.choice()就是从agents中随机取出一个来,以达到不同人访问的目的
# 当然除了这个方法以外还可以减慢访问的速度,因为人在访问时不可能一直点一直点,没有那么快的访问速度,所以每访问一次最好可以间隔一段时间
# 还有一个问题及时由于我们访问的ip一直是一个也可能导致会被网站察觉到,所以我们可以使用代理服务器的方式。
hs = {"User-Agent" : random.choice(agents)}
# 利用request库发出一个get请求
response = requests.get(url,headers =hs)
# 解决乱码问题
# 修改编码格式
response.encoding = response.apparent_encoding
return response.text,response.encoding
lxml:
1. etree.parse() 读取xml文件,结果为**xml对象**(不是字符串) 2. etree.HTML(string_html) 将字符串形势的html文件转换为xml对象 3. etree.tostring(htmlelement, encoding="utf-8").decode("utf-8") etree.tostring(html,encoding="utf-8", pretty_print=True).decode()
选择器
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
csv:一种类似于excel表的文件,用,代替了表格
def save_csv(filepath,data,encoding='utf-8'): """ :param filepath: 文件最后保存的路径 :param data: 51job的工作信息的字典的列表 :param encoding: 编码格式,默认utf-8, :return: """ with open(filepath,'a+') as fp: # 获取表头列表 headers = data and list(data[0].keys()) print(headers) # 定义writer writer = csv.DictWriter(fp,fieldnames=headers) # 如果程序没有指向表头,依旧以为程序为空,没有表头,则添加表头,否则不添加表头 if fp.tell() == 0: writer.writeheader() # print(data) # for i in range(0,len(data)): # print(list(data[i].values())) #writer() # 可以直接写入字典类型的数据,但是数据的keys必须和表头的keys相等,否则会出错。 writer.writerows(data)re:正则表表达式
具体可以另一边博客正则表达式
源码部分
job51_spider.py
""" @Author:sumu @Date:2020-01-06 14:26 @Email:[email protected] """
import random
import requests
def getHtml(url):
""" :param url: 想要爬取的网址地址 :return: 源文件和编码格式 """
# 让机器访问网址,模拟浏览器访问,具体请求头,可以在谷歌浏览器F12进入检查模式可以查看
# 一下就是各种机型访问网站的的标志
agents = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
]
# 模拟一个请求头,由下面的字典组成,random.choice()就是从agents中随机取出一个来,以达到不同人访问的目的
# 当然除了这个方法以外还可以减慢访问的速度,因为人在访问时不可能一直点一直点,没有那么快的访问速度,所以每访问一次最好可以间隔一段时间
# 还有一个问题及时由于我们访问的ip一直是一个也可能导致会被网站察觉到,所以我们可以使用代理服务器的方式。
hs = {
"User-Agent" : random.choice(agents)}
# 利用request库发出一个get请求
response = requests.get(url,headers =hs)
# 解决乱码问题
# 修改编码格式
response.encoding = response.apparent_encoding
return response.text,response.encoding
job51_line.py
""" @Author:sumu @Date:2020-01-06 14:35 @Email:[email protected] """
from lxml.html import etree
import re
from utils.file_tools import *
import datetime
def read_data(page_count,filepath="./datas/job_python/"):
""" :param page_count: 需要爬取的页数 :param filepath: 源文件存放的路径 :return: 无返回值,在函数的最后将解析后的数据存储文件中 """
parser = etree.HTMLParser(encoding='utf-8')
for i in range(1,page_count):
html_tree = etree.parse(filepath+f"python_{i}.html",parser =parser)
path = "//div[@class='dw_table']/div[@class='el']"
jobs = html_tree.xpath(path)
jobs_list = []
for job in jobs:
dict_job = std_job(job)
jobs_list.append(dict_job)
# job_title = job.xpath('./p/span/a')[0].text
# job_company = job.xpath('./span/a')[0].text
# job_place = job.xpath('./span[@class="t3"]')[0].text
# job_salary = job.xpath('./span[@class="t4"]')[0].text
# job_date = job.xpath('./span[@class="t5"]')[0].text
# 加入文件到csv文件中
#保存页面中的信息到csv文件
save_csv(f"./handled_data/job_python_{str(datetime.datetime.now()).split(' ')[0]}.csv",jobs_list)
#print(f"{job_title}\t {job_company} \t {job_place}\t{job_salary}\t{job_date}")
def transfermation_k(data):#提取最大最小值,单位:千每月
""" :param data: 处理好的工资列表 :return: 最大薪资和最小薪资列表 功能:把工资列表里的暑假进行进一步的分解,分成最大值和最小值的列表,其中的空值用当前数据的平均值代替 """
regx = re.compile(r'(\d*.?\d*)-(\d*.?\d+)')
regx1 = re.compile(r'([\u4e00-\u9fa5])/([\u4e00-\u9fa5])')
number = re.findall(regx, data)
per = re.findall(regx1, data)
if len(number) == 0 or len(per) == 0:
return 0,0
number = list(number[0])
per = list(per[0])
if '千' in per and '月' in per :
# print('True')
mymax = float(number[1]) * 1000
mymin = float(number[0]) * 1000
elif '万' in per and '月' in per :
mymax = float(number[1]) * 10000
mymin = float(number[0]) * 10000
elif '万' in per and '年' in per :
mymax = round(float(number[1]) * 10000 / 12, 2)
mymin = round(float(number[0]) * 10000 / 12, 2)
elif '元' in per and '天' in per :
mymax = float(number[0])
mymin = float(number[0])
else :
mymin = 0
mymax = 0
return mymin,mymax
def std_job(job):
""" 功能:用于具体的解析工作,把html文件中的所有要用的信息通过lxml解析掉,从上一次的位置开始解析 :param job: 初步解析的工作文件 :return: 一个解析完成的字典 """
dic = {
}
# 取出id
id = job.xpath('./p/input/@value')[0]
# 取出职位名。解析式根据网页代码可得
job_title = job.xpath('./p/span/a')[0].text
# 对职位名进行分析,分成只有python或者id。出现python关键字的就是python,其余无法通过计算机判断的都归为it类
ttype = [s.lower() for s in re.findall(r'[a-zA-Z]+',job_title)]
type = 'python' if 'python' in ttype else 'it'
# 取出公司名,和公司网站
job_company_name = job.xpath('./span[@class="t2"]/a/@title')[0]
job_company_link = job.xpath('./span[@class="t2"]/a/@href')[0]
# 取出地址
job_place = job.xpath('./span[@class="t3"]')[0].text
# 将地址字符串以-为分隔符进行分割,
jj_address = job_place.split('-')
# 判断他是一个还有两个
city = jj_address if len(jj_address)==1 else jj_address[0]
#获取薪水
job_salary = job.xpath('./span[@class="t4"]')[0].text
job_salary1 =str(job_salary)
job_date = job.xpath('./span[@class="t5"]')[0].text
jjob_date = job_date.split('-')
job_date_new = "2020"+job_date if jjob_date[0] == '01' else "2019"+job_date
# 调用分解薪水的函数
mymin,mymax = transfermation_k(job_salary1)
# 最后我们所用到的数据类型,通过字典的方式封装进去
dic['id'] = id
dic['job_title'] = job_title.strip()
dic['type'] = type
dic['job_company_name'] =job_company_name
dic['job_company_link'] =job_company_link
dic['job_place'] =job_place
dic['city'] =city
dic['job_salary'] = job_salary
dic['min_salary'] = mymin
dic['max_salary'] = mymax
dic['job_date_new'] = job_date_new
print(dic)
return dic
# print(job_company_link)
#job = {"title":job_title,"company":job_company,}
#return {}
if __name__ == '__main__':
read_data(2,"../../datas/job_python/")
file_tools.py
""" @Author:sumu @Date:2020-01-06 14:27 @Email:[email protected] """
import csv
import requests
from functools import singledispatch
def read_file(filepath):
""" :param filepath: 文件的路径 :return: 文件的内容 """
with open(filepath) as fp :
content = fp.read()
return content
def read_file_layout(filepath):
""" :param filepath: 文件的路径 :return: 文件的内容 """
str = ""
fp = open(filepath)
content = fp.readlines()
for c in content:
str += c.replace('\n', '\n')
fp.close()
return str
def write_file_str(filepath,mode,content,encoding1='utf-8'):
""" :param filepath: 文件的路劲 :param mode: 打开的方式 :param content: 写入的内容 :return: 返回值 """
with open(filepath, mode,encoding=encoding1) as rwf:
rwf.write(content)
return "successful"
def write_file_list(filepath,mode,content=list):
""" :param filepath: 文件的路劲 :param mode: 打开的方式 :param content: 写入的内容 :return: 返回值 """
print("list")
with open(filepath, mode) as rwf:
for i in content:
rwf.write(str(i)+'\n')
#rwf.write(content)
return "successful"
# stu1 = [lid, k, pre_count_data[k]]
# # 打开文件,写模式为追加'a'
# out = open('../results/write_file.csv', 'a', newline='')
# # 设定写入模式
# csv_write = csv.writer(out, dialect='excel')
# # 写入具体内容
# csv_write.writerow(stu1)
def write_cvs_file(filepath,mode,t1,t2,t3,t4,t5,t6):
""" 功能:把51同城搜索只有网页的源码的数据清理之后的数据整理成表格的形式写入csv表中;进行存储,备份。 :param filepath: 文件存放的路径 :param mode: 写入方式例如;'w','a'等 :param t1: 职位列表 :param t2: 公司列表 :param t3: 地区列表 :param t4: 最小薪资列表 :param t5: 最大薪资列表 :param t6: 发布的日期 :return: """
f = open(filepath,mode,newline='', encoding='utf-8')
# 2. 基于文件对象构建 csv写入对象
print(len(t1),len(t2),len(t3),len(t4),len(t5),len(t6))
csv_writer = csv.writer(f)
for i in range(len(t1)):
csv_writer.writerow([str(t1[i]),str(t2[i]),str(t3[i]),str(t4[i]),str(t5[i]),str(t6[i])])
f.close()
def save_csv(filepath,data,encoding='utf-8'):
""" :param filepath: 文件最后保存的路径 :param data: 51job的工作信息的字典的列表 :param encoding: 编码格式,默认utf-8, :return: """
with open(filepath,'a+') as fp:
# 获取表头列表
headers = data and list(data[0].keys())
print(headers)
# 定义writer
writer = csv.DictWriter(fp,fieldnames=headers)
# 如果程序没有指向表头,依旧以为程序为空,没有表头,则添加表头,否则不添加表头
if fp.tell() == 0:
writer.writeheader()
# print(data)
# for i in range(0,len(data)):
# print(list(data[i].values()))
#writer()
# 可以直接写入字典类型的数据,但是数据的keys必须和表头的keys相等,否则会出错。
writer.writerows(data)
if __name__ == '__main__':
filepath ='../handled_data/test.csv'
data= [
{
'1':1,'3':'kjl'},
{
'1':1,'3':'kljk'}
]
save_csv(filepath,data)
pass
producter_51job_url.py
""" @Author:sumu @Date:2020-01-06 09:40 @Email:[email protected] """
from lxml.html import etree
def producter(condition,page_count):
""" :param condition: 搜索的内容 :param page_count: 页数 :return: url列表 """
query_staring = {
"condition" : condition,
"page_index" : 1
}
url_list = []
# 获取1到10页的数据,产生url
for i in range(1, page_count) :
url51job = f"https://search.51job.com/list/000000,000000,0000,00,9,99,{query_staring['condition']},2,{query_staring['page_index']}.html"
url_list.append(url51job)
return url_list
def gain_config(filepath) :
""" 功能:解析配置文件,原理是和解析xml文件类同。 :param filepath: 配置文件路径 :return: 返回默认的配置值 """
config_tree = etree.parse(filepath)
datas = config_tree.xpath('/spiders/spider[@id="job_spider"]')
print(len(datas))
condition = datas[0].xpath('./condition')[0].text
page_count = datas[0].xpath('./pageAccount')[0].text
return condition, page_count
start.py
""" @Author:sumu @Date:2020-01-06 14:24 @Email:[email protected] """
from spiders.my_spider.job51_spider import *
from utils.file_tools import *
from utils.producter_51joburl import *
from spiders.pipo_line.job51_line import *
def begin():
condition,page_count = gain_config('./spiders.cfg')
url_list = producter(condition,page_count+1)
j =1
for i in url_list:
# 1.爬取数据
data,e = getHtml(i)
# 2.保存数据
write_file_str(f'./datas/job_python/{condition+"_"+str(j)}.html','w',data)
j+=1
#print(data)
# 3. 解析数据
# 4.将解析的文件写入csv在read_data中间调用
read_data(page_count+1)
配置文件:
<spiders>
<spider id='job_spider'>
<condition>python</condition>
<pageAccount>30</pageAccount>
</spider>
<spider id='taobao_spider'>
<condition>香水</condition>
<pageAccount>100</pageAccount>\
</spider>
</spiders>
边栏推荐
- Chapter I exercises of program construction and interpretation
- selenium-webdriver之断言
- Assertion of selenium webdriver
- JUnit test suite method sorting (method 2 is not easy to use)
- Leader education was forced to be delisted: Softbank CMC suffered heavy losses only one year after listing
- Function related matters
- Jenkins' RPC test project
- Detailed explanation of factory pattern (simple factory pattern, factory method pattern, abstract factory pattern) Scala code demonstration
- 启明云端分享| 通过Matter协议实例演示开关通过matter协议来做到对灯亮灭的控制
- 数据的收集
猜你喜欢
![[wp][入门]攻防世界-game](/img/07/1ea54d14ba3caca25a68786d5be4a6.png)
[wp][入门]攻防世界-game
[wp][beginner level] attack and defense world game
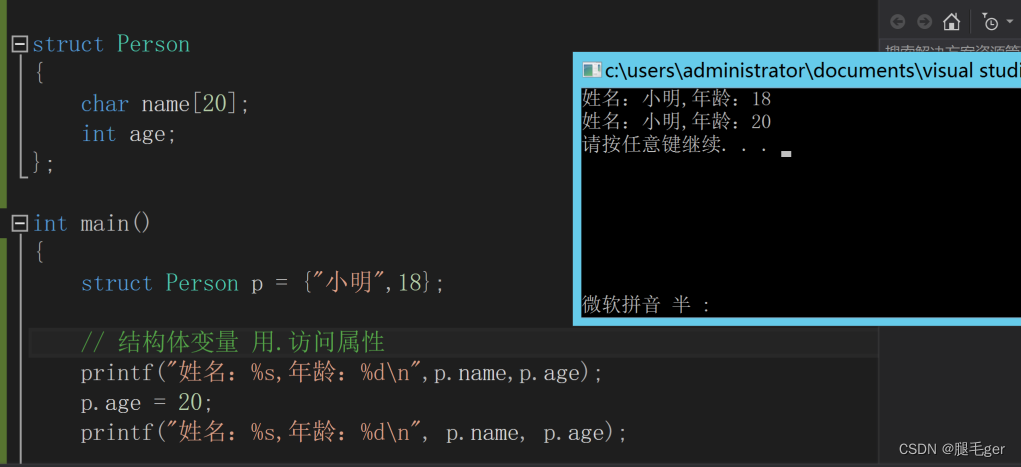
结构体示例

JUnit test suite method sorting (method 2 is not easy to use)
![[wechat applet] 2 Environmental preparation](/img/8d/7bb68ca7d10751a6e992a53c5eff4a.jpg)
[wechat applet] 2 Environmental preparation

MH32F103ARPT6软硬件兼容替代STM32F103RCT6

阿里建议所有 POJO 类属性使用包装类,但这些坑你有注意到吗?
Appnium (II) installation and basic use of mitmproxy

Writing method of JUnit multithreading

ROS初学者编写小乌龟以一定速度旋转一定角度的server
随机推荐
jenkins的RPC测试项目
About layoffs in Internet companies
Location (I) error: command erred out with exit status
JS (III) convert ES6 syntax to Es5 syntax
SQL cross database injection
NETCORE combined with cap event bus to realize distributed transaction -- Introduction (1)
MH32F103ARPT6软硬件兼容替代STM32F103RCT6
【Instant】1. Equivalent to date class 2 Represents a moment
ADB command (2) use monkey to test
Detailed explanation of factory pattern (simple factory pattern, factory method pattern, abstract factory pattern) Scala code demonstration
Appnium (I) basic use of appnium
Prompt that the program cannot access key files / directories when installing PS software. Error code: 41
[wechat applet] 2 Environmental preparation
Function related matters
C main function
Autofac Beginner (1)
junit测试套件方法整理(方法二不太好用)
JS (I) error [err\u module\u not\u found]: cannot find package 'UUID' imported
阿里、腾讯、拼多多垂范,产业互联网的新逻辑渐显
Mh32f103arpt6 hardware and software compatible alternative to stm32f103rct6