当前位置:网站首页>scrapy基本使用
scrapy基本使用
2022-07-30 18:20:00 【冷巷(*_*)】
直接去cmd下载

下载好之后打开pycharm
在命令行里面创建新项目

这个demo01是项目的名字,这个可以随便写的。 然后回车

这样就是创建好了。可以cd到那个项目,但是这里直接在file里面打开就行了!
file-open-demo1

点ok然后点this windows,就是在当前窗口打开,关掉之后再打开还是这个项目,如果点new windows的话就是新窗口打开,重启后是之前的项目。

这个是创建一个spider,
scrapy genspider baidu baidu.com这里的第一个baidu是名字,然后跟着域名。创建完成后在spiders里面会发现多了一个baidu.py。然后我们进入这个py

name就是名字,项目名,allowed_domains呢就是域名,start_urls是开始的地方,想从哪里开始爬就从这里修改就行了,下面的parse()是解析的
# Scrapy settings for demo01 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'demo01' # 爬虫项目名
SPIDER_MODULES = ['demo01.spiders']
NEWSPIDER_MODULE = 'demo01.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozlla/5.0' # user_agent这个可以改,可以在这里设置,也可以在下面设置
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # 是否遵循robots协议,一定要设置为false
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 8 # 最大并发量,默认为16 这个要改
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1 # 下载延迟请求,每隔多长时间发送一个请求(减低数据爬取频率)
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False # 是否启用cookies,默认禁止,取消注释就是开启
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# 请求头,类似于requests.get()方法中的headers参数
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0'
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'demo01.middlewares.Demo01SpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'demo01.middlewares.Demo01DownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'demo01.pipelines.Demo01Pipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
回到baidu.py

然后在pycharm里面的终端运行项目

上面是检查你的scrapy的配置,版本之类的东西,然后

发现这个,提取出来是字典。
在这里创建一个run.py出来

输入
from scrapy import cmdline
cmdline.execute('scrapy crawl baidu'.split())然后右键运行

简单明了,颜色都不一样,直接可以看到自己想要爬取的内容。
回到刚刚的问题,

然后运行一下

接着修改

边栏推荐
- OSPF详解(4)
- 【开发者必看】【push kit】推送服务典型问题合集3
- 固定资产可视化智能管理系统
- Deepen school-enterprise cooperation and build an "overpass" for the growth of technical and skilled talents
- while,do while,for循环语句
- CCNA-网络汇总 超网(CIDR) 路由最长掩码匹配
- linux 安装mysql8.0 超详细教程(实战多次)
- [OC study notes] attribute keyword
- 【Qt Designer工具的使用】
- 信息学奥赛一本通 1966:【14NOIP普及组】比例简化 | 洛谷 P2118 [NOIP2014 普及组] 比例简化
猜你喜欢

Graphic LeetCode -- 11. Containers of most water (difficulty: medium)

OSPF详解(4)

网络基础(二)-Web服务器-简介——WampServer集成服务器软件之Apache+MySQL软件安装流程 & netstat -an之检测计算机的端口是否占用
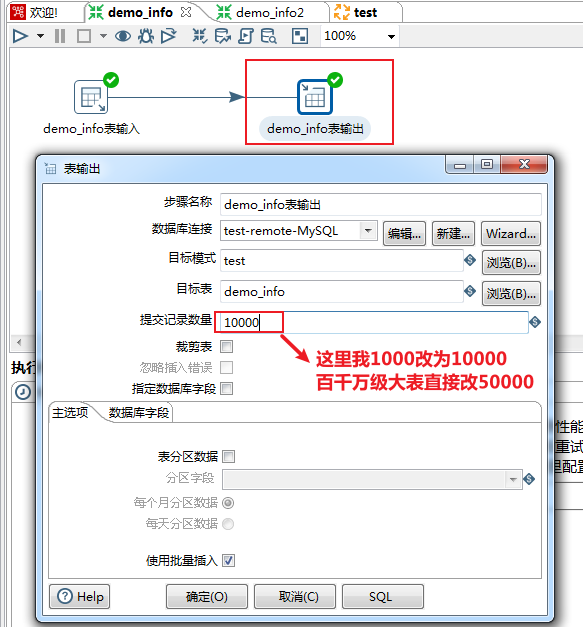
Kettle--MySQL生产数据库千万、亿级数据量迁移方案及性能优化

第十六期八股文巴拉巴拉说(MQ篇)

ESP8266-Arduino编程实例-HC-SR04超声波传感器驱动

基础架构之Redis

开源盛宴ApacheCon Asia 2022即将开幕,精彩不容错过!

Ecplise执行C语言报错:cannot open output file xxx.exe: Permission denied

莫队--优雅的暴力
随机推荐
你好好想想,你真的需要配置中心吗?
cocos creater 热更重启导致崩溃
千亿级、大规模:腾讯超大 Apache Pulsar 集群性能调优实践
CMake库搜索函数居然不搜索LD_LIBRARY_PATH
【AGC】构建服务1-云函数示例
ESP8266-Arduino programming example-BMP180 air pressure temperature sensor driver
leetcode-547:省份数量
Hangzhou electric school game 2 1001 2022 Static Query on Tree (Tree + hash table difference chain subdivision
Arranger software FL Studio Chinese version installation tutorial and switching language tutorial
Mo Team - Elegant Violence
[OC study notes] attribute keyword
BI报表与数据开发
What is an ultrasonic flaw detector used for?
智慧中控屏
Pytorch foundation -- tensorboard use (1)
自然语言处理nltk
OSPF详解(3)
深化校企合作 搭建技术技能人才成长“立交桥”
CCNA-NAT协议(理论与实验练习)
ctf.show_web5