https://www.bilibili.com/video/BV1Tk4y1U7ts/?spm_id_from=333.788.recommend_more_video.14


Heat map .

The above thermodynamic diagram has great limitations , Because he is just a causality Result .

Handle as shown in the figure above unit as well as channel The semantics of , So we can use the activation of neurons ( That is to say, give a picture , Look at those neurons being activated ), Then use these activated neurons , To provide an explanation . With the activation of neurons and semantic properties, we provide conversational.



The above explicability is to train a model , And then analyze it , But the next direction is how to build an interpretable model .
Transformer There is a very important self attention Mechanism . He can turn feature The relationship between them is clearly reflected ; In this case feature It can be a little longer when added to the constraint level ( Improve accuracy ).
As shown in the figure on the right self attention After using the mechanism of , This makes the model itself highly interpretable , Because it highlights those feature Was highlighted , Then you can project it directly onto the picture , Then find the area where it really highlights , In this way, the model itself is interpretable .
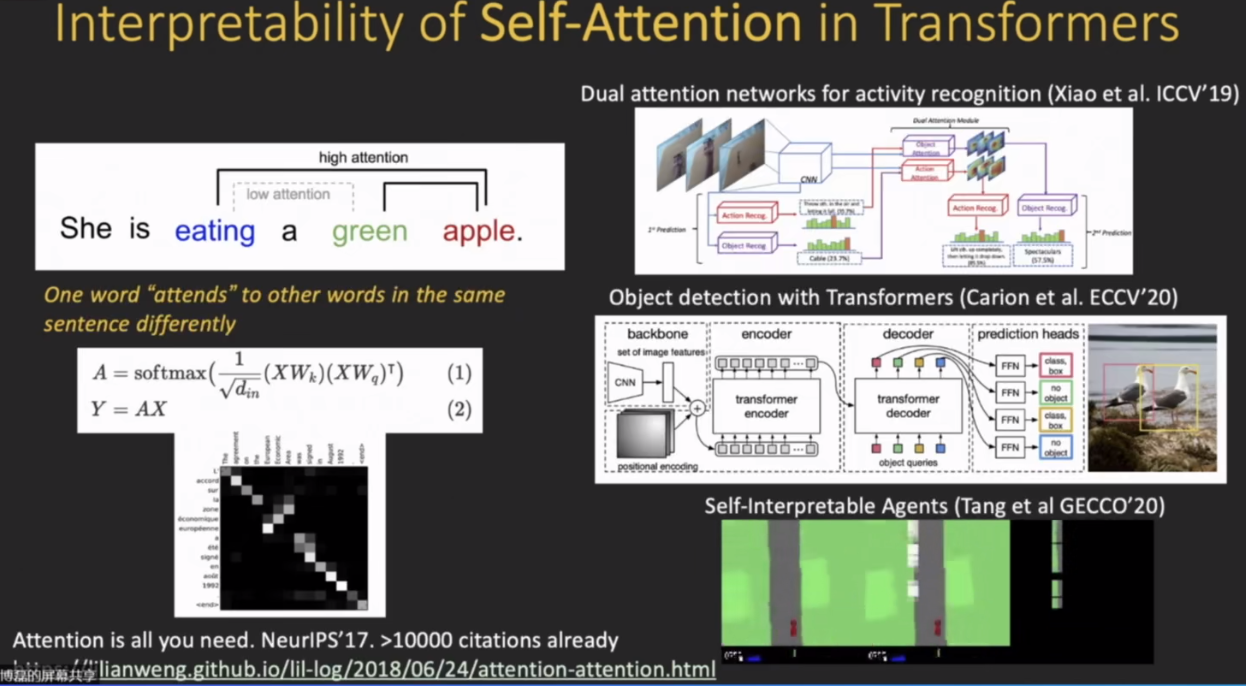












Model explicability is a very big problem topic, We need to apply this idea of explicability to different applications , For example, to explain The prediction of the model Or right Perform an interpretable analysis against the robustness of the sample , And interpretable analysis of the bias and fairness of the model ; In addition, generating models is also an important direction ,.




![[C language practice - exchange the values of two variables]](/img/e1/44b7e31d69fd5351d017b47374277b.png)




