当前位置:网站首页>Source code analysis of zeromq lockless queue
Source code analysis of zeromq lockless queue
2022-06-25 14:53:00 【Mr . Solitary patient】
Preface
When I first learned about lockless queues , I found a lot of information on the Internet , But most of them start to talk about the implementation of lockless queues from the beginning , It confused me , What exactly is an unlocked queue , What is the intention of designing this thing ? Next, I will give you a good analysis of lockless queues .
What is a lockless queue
Lockless queue just as its name implies , No lock + queue , Queues have the following operational models :
(1) Single producer, single consumer

(2) Multiple producers and single consumers 
(3) Single producer and multiple consumers

(4) Many producers, many consumers

We need to use locks when we implement the producer consumer model , To ensure synchronization and mutual exclusion between threads
Mutually exclusive : You need to lock the shared queue
Sync :(1) The queue is empty and the consumer thread needs to read data , At this point, the consumer thread should be blocked
(2) The queue is full, but the producer thread still has to add data to the queue , At this point, the producer thread needs to be blocked
The intention of designing lockless queue is to realize the problem of producers and consumers without locks
Usage scenarios of lockless queues
Lockless queues apply to 1s Mass data (1s 10w+) The occasion of entering the queue , If the amount of data is small (1s Hundreds of thousands ) In this case, there is no need to use a lockless queue , Because the time of locking can be ignored .
zeromq The design idea of no lock in (zeromq The lockless queue in supports only single producer and single consumer )
stay zeromq in , Producers can produce at will , However, there are limitations for consumers to read , The idea of lock free implementation is when consumers read data , If the element in the queue is empty , Then return to false Instead of blocking the program with a lock , After that, the application layer is used by the programmer according to the returned false Let consumers wait for a while ( It can be sleep Or lock it ), Start running again , Therefore, the lock free queue only does not need to be locked when operating on shared variables .
zromq Implementation of queues
zeromq in yqueue.hpp Is the implementation of the queue , Let's take a look at the interfaces inside 
Queue chunk Mechanism

yqueue By multiple chunk constitute , Every chunk All by N Elements make up , The advantage of this is that every time malloc A batch of elements will be allocated in batch when , Reduce the allocation and release of memory ,chunk And chunk The data structure of is a two-way linked list , Easy to add and find .

The actual position is shown in the figure :
Gray indicates the block filled with data , White represents the block without filling data
back_pos Point to the last block with data
end_pos Point to back_pos The last one of them

spare_chunk The pointer , Used to save the released chunk The pointer , When it is necessary to reallocate chunk When , We'll look at
here , Assign... From here chunk. Here we use the atomic cas Operate to complete , Using the locality principle of the operating system , It means short
The amount of data in the queue in time is a process of horizontal fluctuation .
Other functions and stl in queue The name of the function of is the same as the function of , It is easy to understand , I won't give you too much introduction here .
Lockless queue ypipe The implementation of the
Before that, let's talk about cas(compare and set) operation
cas stay zeromq Is implemented by assembly
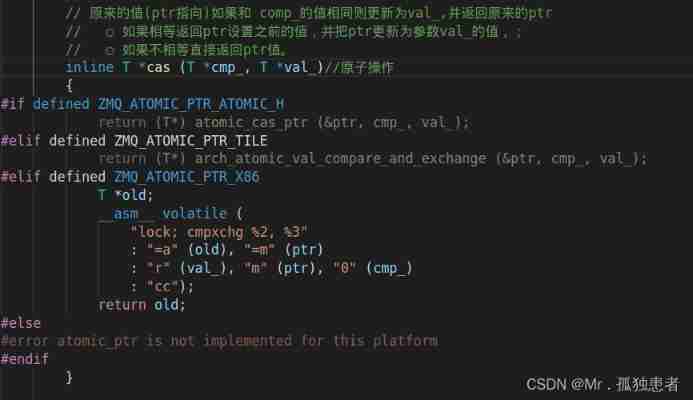
Its content is converted to c The language is like this :
int compare_and_swap (int* c, int com_, int val_)
{
int old_reg_val = *c;
if (old_reg_val == com_)
*c = val_;
return old_reg_val;
}
That is to say , Have a look c The value in is not cmp_, If so , Then assign a value to it val_, And back to c The value of the original , If they are not equal, return directly c Value .
ypipe
Now almost everything CPU All instructions support CAS Atomic operation of ,X86 The next correspondence is CMPXCHG Assembly instruction . With this atomic operation , We can use it to achieve all kinds of lock free (lock free) Data structure of .
The main variable
T *w : Point to the location of the next element that can be written
T *r: Point to the first element that can be read
T *f: Point to the first element of the pre write
atomic_ptr_t c; Point to the starting point of each round of refresh , Normal reading and writing c The value of is always equal to w Of , But when there is no data in the queue, it is called once read after c The value of will become NULL, This means that the read thread must be in a blocking state , So back false Tell the programmer that the reader thread needs to be awakened .
flush()
inline bool flush(
{
// If there are no un-flushed items, do nothing.
if (w == f) // No need to refresh , That is, no new elements have been added
return true;
// Try to set 'c' to 'f'.
// read If there is no data to read, then c The value of will be set to NULL
if (c.cas(w, f) != w) // Try to c Set to f, That is, prepare to update w The location of
{
// Normal reading and writing c The value of is always equal to w Of , But when there is no data in the queue, it is called once read after c The value of will become NULL,
// This means that the read thread must be in a blocking state , So back false Tell the programmer that the reader thread needs to be awakened .
// Compare-and-swap was unseccessful because 'c' is NULL.
// This means that the reader is asleep. Therefore we don't
// care about thread-safeness and update c in non-atomic
// manner. We'll return false to let the caller know
// that reader is sleeping.
c.set(f); // Update to a new f Location
w = f;
return false; // Threads see flush return false Then a message will be sent to the reader thread , This requires writing business to deal with
}
else // There is still data to be read at the reader
{
// Under normal circumstances, it is only necessary to w Updated to f Indicates that the pre write is complete
// Reader is alive. Nothing special to do now. Just move
// the 'first un-flushed item' pointer to 'f'.
w = f; // to update f The location of
return true;
}
}
check_read()
// There are two points , One is to check whether there is data readable , One is prefetching
inline bool check_read()
{
// queue.front() = r Indicates that the data has been read
if (&queue.front() != r && r) // Determine whether to call... In the previous few times read Function has prefetched data return true;
return true;
// There's no prefetched value, so let us prefetch more values.
// Prefetching is to simply retrieve the
// pointer from c in atomic fashion. If there are no
// items to prefetch, set c to NULL (using compare-and-swap).
// Two cases
// 1. If c Values and queue.front() equal , return c Value and will c Value is set to NULL, No data is readable at this time
// 2. If c Values and queue.front() Unequal , return c value , At this time, there may be data that can be read
r = c.cas(&queue.front(), NULL); // Try prefetching data
// If there are no elements prefetched, exit.
// During pipe's lifetime r should never be NULL, however,
// it can happen during pipe shutdown when items are being deallocated.
if (&queue.front() == r || !r) // Determine whether the data is successfully prefetched
return false;
// There was at least one value prefetched.
return true;
}
Change process
If it is difficult to understand the code, just look at the data according to the figure below .

Test lockless queue performance
void *mutexqueue_producer_thread(void *argv)
{
PRINT_THREAD_INTO();
for (int i = 0; i < s_queue_item_num; i++)
{
s_mutex.lock();
s_list.push_back(s_count_push);
s_count_push++;
s_mutex.unlock();
}
PRINT_THREAD_LEAVE();
return NULL;
}
void *mutexqueue_consumer_thread(void *argv)
{
int value = 0;
int last_value = 0;
int nodata = 0;
PRINT_THREAD_INTO();
while (true)
{
s_mutex.lock();
if (s_list.size() > 0)
{
value = s_list.front();
s_list.pop_front();
last_value =value;
s_count_pop++;
nodata = 0;
}
else
{
nodata = 1;
}
s_mutex.unlock();
if (nodata)
{
// usleep(1000);
sched_yield();
}
if (s_count_pop >= s_queue_item_num * s_producer_thread_num)
{
// printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
break;
}
else
{
// printf("s_count_pop:%d, %d, %d\n", s_count_pop, s_queue_item_num, s_producer_thread_num);
}
}
printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
PRINT_THREAD_LEAVE();
return NULL;
}
#include "ypipe.hpp"
ypipe_t<int, 10000> yqueue;
void *yqueue_producer_thread(void *argv)
{
PRINT_THREAD_INTO();
int count = 0;
for (int i = 0; i < s_queue_item_num;)
{
yqueue.write(count, false); // enqueue The order of is not guaranteed , We can only calculate enqueue The number of
count = lxx_atomic_add(&s_count_push, 1);
i++;
yqueue.flush();
}
PRINT_THREAD_LEAVE();
return NULL;
}
void *yqueue_consumer_thread(void *argv)
{
int last_value = 0;
PRINT_THREAD_INTO();
while (true)
{
int value = 0;
if (yqueue.read(&value))
{
if (s_consumer_thread_num == 1 && s_producer_thread_num == 1 && (last_value + 1) != value) // Only in the case of one in and one out can there be comparative significance
{
// printf("pid:%lu, -> value:%d, expected:%d\n", pthread_self(), value, last_value + 1);
}
lxx_atomic_add(&s_count_pop, 1);
last_value = value;
}
else
{
// printf("%s %lu no data, s_count_pop:%d\n", __FUNCTION__, pthread_self(), s_count_pop);
usleep(100);
// sched_yield();
}
if (s_count_pop >= s_queue_item_num * s_producer_thread_num)
{
// printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
break;
}
}
PRINT_THREAD_LEAVE();
return NULL;
}
std::mutex ypipe_mutex_;
std::condition_variable ypipe_cond_;
void *yqueue_producer_thread_condition(void *argv)
{
PRINT_THREAD_INTO();
int count = 0;
for (int i = 0; i < s_queue_item_num;)
{
yqueue.write(count, false); // enqueue The order of is not guaranteed , We can only calculate enqueue The number of
count = lxx_atomic_add(&s_count_push, 1);
i++;
if(!yqueue.flush()) {
// printf("notify_one\n");
std::unique_lock<std::mutex> lock(ypipe_mutex_);
ypipe_cond_.notify_one();
}
}
std::unique_lock<std::mutex> lock(ypipe_mutex_);
ypipe_cond_.notify_one();
PRINT_THREAD_LEAVE();
return NULL;
}
void *yqueue_consumer_thread_condition(void *argv)
{
int last_value = 0;
PRINT_THREAD_INTO();
while (true)
{
int value = 0;
if (yqueue.read(&value))
{
if (s_consumer_thread_num == 1 && s_producer_thread_num == 1 && (last_value + 1) != value) // Only in the case of one in and one out can there be comparative significance
{
// printf("pid:%lu, -> value:%d, expected:%d\n", pthread_self(), value, last_value + 1);
}
lxx_atomic_add(&s_count_pop, 1);
last_value = value;
}
else
{
// printf("%s %lu no data, s_count_pop:%d\n", __FUNCTION__, pthread_self(), s_count_pop);
// usleep(100);
std::unique_lock<std::mutex> lock(ypipe_mutex_);
printf("wait\n");
ypipe_cond_.wait(lock);
// sched_yield();
}
if (s_count_pop >= s_queue_item_num * s_producer_thread_num)
{
// printf("%s dequeue:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
break;
}
}
printf("%s dequeue: last_value:%d, s_count_pop:%d, %d, %d\n", __FUNCTION__, last_value, s_count_pop, s_queue_item_num, s_consumer_thread_num);
PRINT_THREAD_LEAVE();
return NULL;
}
int test_queue(thread_func_t func_push, thread_func_t func_pop, char **argv)
{
int64_t start = get_current_millisecond();
pthread_t tid_push[s_producer_thread_num] = {
0};
for (int i = 0; i < s_producer_thread_num; i++)
{
int ret = pthread_create(&tid_push[i], NULL, func_push, argv);
if (0 != ret)
{
printf("create thread failed\n");
}
}
pthread_t tid_pop[s_consumer_thread_num] = {
0};
for (int i = 0; i < s_consumer_thread_num; i++)
{
int ret = pthread_create(&tid_pop[i], NULL, func_pop, argv);
if (0 != ret)
{
printf("create thread failed\n");
}
}
for (int i = 0; i < s_producer_thread_num; i++)
{
pthread_join(tid_push[i], NULL);
}
for (int i = 0; i < s_consumer_thread_num; i++)
{
pthread_join(tid_pop[i], NULL);
}
int64_t end = get_current_millisecond();
int64_t temp = s_count_push;
int64_t ops = (temp * 1000) / (end - start);
printf("spend time : %ldms\t, push:%d, pop:%d, ops:%lu\n", (end - start), s_count_push, s_count_pop, ops);
return 0;
}
// ./test 1 1
int main(int argc, char **argv)
{
if (argc >= 4 && atoi(argv[3]) > 0)
s_queue_item_num = atoi(argv[3]);
if (argc >= 3 && atoi(argv[2]) > 0)
s_consumer_thread_num = atoi(argv[2]);
if (argc >= 2 && atoi(argv[1]) > 0)
s_producer_thread_num = atoi(argv[1]);
printf("\nthread num - producer:%d, consumer:%d, push:%d\n\n", s_producer_thread_num, s_consumer_thread_num, s_queue_item_num);
for (int i = 0; i < 1; i++)
{
s_count_push = 0;
s_count_pop = 0;
printf("\n\n--------->i:%d\n", i);
#if 1
printf("use mutexqueue ----------->\n");
test_queue(mutexqueue_producer_thread, mutexqueue_consumer_thread, NULL);
#endif
if (s_consumer_thread_num == 1 && s_producer_thread_num == 1)
{
s_count_push = 0;
s_count_pop = 0;
printf("\nuse ypipe_t ----------->\n");
test_queue(yqueue_producer_thread, yqueue_consumer_thread, NULL);
s_count_push = 0;
s_count_pop = 0;
printf("\nuse ypipe_t condition ----------->\n");
test_queue(yqueue_producer_thread_condition, yqueue_consumer_thread_condition, NULL);
}
else
{
printf("\nypipe_t only support one write one read thread, bu you write %d thread and read %d thread so no test it ----------->\n",
s_producer_thread_num, s_consumer_thread_num);
}
}
printf("finish\n");
return 0;
}
test result 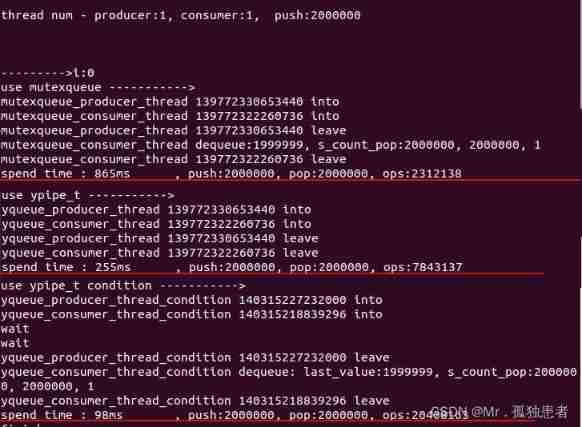
It can be seen that usleep The speed of the lockless queue is about three times faster , And use unique_lock() The processing of the unlocked queue is nearly 10 times .
If there are mistakes or deficiencies , Please leave a message to correct
边栏推荐
- 【HBZ分享】LockSupport的使用
- Get the parameters in the URL and the interchange between parameters and objects
- What moment makes you think there is a bug in the world?
- JGG | 河北大学杜会龙组综述植物泛基因组学研究
- Clipboard tutorial
- [untitled] the CMD command window displays' NPM 'which is not an internal or external command
- Disable scrolling in the iPhone web app- Disable scrolling in an iPhone web application?
- SPARQL learning notes of query, an rrdf query language
- Basic knowledge of pointer
- How to combine multiple motion graphs into a GIF? Generate GIF animation pictures in three steps
猜你喜欢

It's not easy to understand the data consistency of the microservice architecture for the first time after six years as a programmer

New good friend Pinia, leading the new era of state management
【Try to Hack】vulnhub DC1

Iterator failure condition

Std:: vector minutes

Build a minimalist gb28181 gatekeeper and gateway server, establish AI reasoning and 3D service scenarios, and then open source code (I)

QQ情话糖果情话内容获取并保存

多张动图怎样合成一张gif?仅需三步快速生成gif动画图片
![[untitled]](/img/7f/e2c9fbfb5eb6e7fcc6e23a46540933.jpg)
[untitled]

定位position(5种方式)
随机推荐
Qlogsystem log system configuration use
QT inline dialog
JS to verify whether the string is a regular expression
What is the difference between escape, encodeuri and encodeuricomponent?
@Font face fonts only work on their own domain - @font-face fonts only work on their own domain
Clinical Chemistry | 张建中/徐健开发幽门螺杆菌单细胞精准诊疗技术
Get the parameters in the URL and the interchange between parameters and objects
Haven't you understood the microservice data architecture transaction management +acid+ consistency +cap+base theory? After reading it, you can completely solve your doubts
2020-03-20
JS determines whether two values are equal, and compares any two values, including array objects
Time stamp calculation and audio-visual synchronization of TS stream combined video by ffmpeg protocol concat
Open a restaurant
[Ocean University of China] information sharing for the first and second examinations of postgraduate entrance examination
15 -- k points closest to the origin
H5 page graying source code, ie compatible (elegant downgrade provides download browser link)
[untitled] PTA check password
【深度学习】多任务学习 多个数据集 数据集漏标
移除区间(贪心)
Where is it safe to open an account for buying funds? Ask for guidance
QT database connection deletion