当前位置:网站首页>Decision tree and random forest
Decision tree and random forest
2022-07-05 19:06:00 【Bayesian grandson】
Decision trees and random forests
List of articles
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import tree # Import decision tree
from sklearn.datasets import load_iris # Import datasets Create array
One 、 A summary of knowledge ( One )
The origin of decision tree thinking is very simple , The conditional branch structure in programming is if-then structure , The earliest decision tree is a kind of classification learning method using this kind of structure to segment data .
Information entropy : H = − ( p 1 l o g p 1 + p 2 l o g p 2 + . . . p 3 l o g p 3 ) H = -(p_1logp_1+p_2logp_2+...p_3logp_3) H=−(p1logp1+p2logp2+...p3logp3)
H be called Information entropy , Unit is The bit .
32 Teams ,log32=5 The bit ;64 Teams ,log64=6 The bit
When this 32 When teams have the same chance to win , The corresponding entropy of information is equal to 5 The bit
One of the bases of decision tree Division : Information gain
features A On the training data set D Information gain of g(D,A), Defined as a set D The entropy of information H(D) With the characteristics of A Given the conditions D Entropy of information condition H(D|A) The difference between the ,
That is, the formula is : g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
notes : The information gain represents the known characteristic X The information that makes the class Y The degree to which the uncertainty of information is reduced
Two 、 Algorithm used in decision tree
ID3— Information gain The biggest rule
C4.5— Information gain ratio The biggest rule
CART— Back to the tree : Squared error Minimum
Classification tree : The gini coefficient The minimum rule stay sklearn We can choose the principle of division
3、 ... and 、sklearn Decision tree API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
Decision tree classifier
criterion: The default is ’gini’ coefficient , You can also choose the entropy of the information gain ’entropy’
max_depth: The depth of the tree
random_state: Random number seed
method:
decision_path: Return to the path of the decision tree
Four 、 Case of decision tree
《 Titanic passenger survival classification model 》
1、pd Reading data
2、 Select influential features , Handling missing values
3、 Carry out feature Engineering ,pd Conversion dictionary , feature extraction
x_train.to_dict(orient=“records”)
4、 Decision tree estimator process
titan= pd.read_csv('./Titanic_Data-master/train.csv')
PassengerId Passenger number
Survived Is it alive
Pclass Class of tickets
Name Name of passenger
Sex Passenger gender
SibSp Number of relatives ( Brother and sister 、 Even number )
Parch Number of relatives ( Parents 、 Number of children )
Ticket Ticket No
Fare Ticket price
Cabin cabin
Embarked Log in to the port
print(titan.head(5))
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
print(titan.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
print(titan.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
1. Data cleaning
# Use the average age to fill in the nan value
titan['Age'].fillna(titan['Age'].mean(), inplace=True)
# Fill in the average ticket price of nan value
titan['Fare'].fillna(titan['Fare'].mean(), inplace=True)
print(titan['Embarked'].value_counts())
# Use the port with the most logins to fill in the nan value
titan['Embarked'].fillna('S', inplace=True)
S 644
C 168
Q 77
Name: Embarked, dtype: int64
2. Feature Engineering
# feature selection
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
x = titan[features] # train features
y= titan['Survived'] # train labels
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
dict=DictVectorizer(sparse=False) # one-hot code ( For category variables )
# Carry out feature Engineering ,pd Convert to dictionary , feature extraction x_train_dict(orient = "records")
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
x_test = dict.transform(x_test.to_dict(orient="records"))
print(dict.get_feature_names_out())
print("*"*50)
# Or use this method to view the feature name
print(dict.feature_names_)
['Age' 'Embarked=C' 'Embarked=Q' 'Embarked=S' 'Fare' 'Parch' 'Pclass'
'Sex=female' 'Sex=male' 'SibSp']
**************************************************
['Age', 'Embarked=C', 'Embarked=Q', 'Embarked=S', 'Fare', 'Parch', 'Pclass', 'Sex=female', 'Sex=male', 'SibSp']
3. Call decision tree API
# Use decision tree to predict
dec = DecisionTreeClassifier()
j = dec.fit(x_train, y_train)
# Prediction accuracy
print(" The accuracy of the prediction :", dec.score(x_test, y_test))
The accuracy of the prediction : 0.7847533632286996
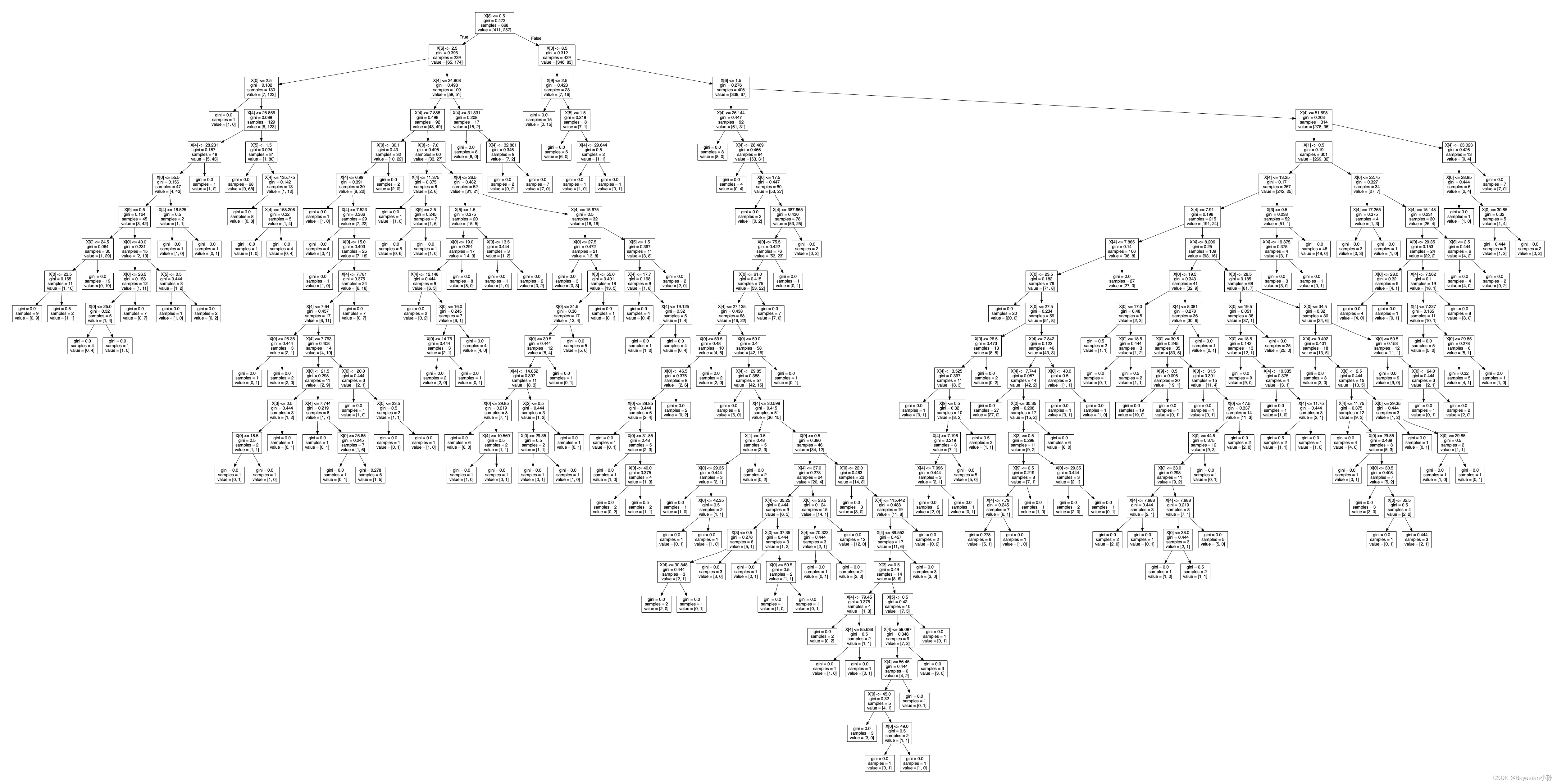
dot_data = tree.export_graphviz(j, out_file=None) # With DOT Format export decision tree
graph = graphviz.Source(dot_data)
graph.render("./output_tree") # Use garDphviDz Save decision tree PDF Save to the current folder directory , File name "output_tree"
'output_tree.pdf'
5、 ... and 、 Integrated learning methods - Random forests
1. A summary of knowledge ( Two )
Integrated learning Solve the single prediction problem by establishing a combination of several models . It works by generating multiple classifiers / Model , Learn and make predictions independently . These forecasts are combined into single forecasts , Therefore, it is better than any single classification to make prediction .
Random forests Is a classifier that contains multiple decision trees , And the output category is determined by the mode of the output category of the individual tree .
Learning algorithms :
Build each tree according to the following algorithm :
use N To represent training use cases ( sample ) The number of ,M Indicates the number of features .
Enter the number of features m, Used to determine the decision result of a node on the decision tree ; among m It should be much less than M.
from N Training use cases ( sample ) In order to have put back the way of sampling , sampling N Time , Form a training set ( namely bootstrap sampling ), And use the use cases that are not extracted ( sample ) Make predictions , Evaluate the error .
2. Integrated learning API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’,
max_depth=None, bootstrap=True, random_state=None)
Random forest classifier
n_estimators:integer,optional(default = 10) The number of trees in the forest
criteria:string, Optional (default =“gini”) The measurement method of segmentation features
max_depth:integer or None, Optional ( Default = nothing ) The maximum depth of the tree
bootstrap:boolean,optional(default = True) Whether to use put back sampling when building trees
3. The case of random forest
# Random forest prediction ( Super parameter tuning )
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1)
param = {
"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]}
# Grid search and cross validation
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print(" Accuracy rate :", gc.score(x_test, y_test))
print(" View the selected parameter model :", gc.best_params_)
Accuracy rate : 0.8430493273542601
View the selected parameter model : {'max_depth': 8, 'n_estimators': 120}
边栏推荐
- Is the performance evaluation of suppliers in the fastener industry cumbersome? Choose the right tool to easily counter attack!
- Oracle Chinese sorting Oracle Chinese field sorting
- 2022全网最全的腾讯后台自动化测试与持续部署实践【万字长文】
- 从外卖点单浅谈伪需求
- 块编辑器如何选择?印象笔记 Verse、Notion、FlowUs
- 一文读懂简单查询代价估算
- Windows Oracle open remote connection Windows Server Oracle open remote connection
- CDB 实例的启动与关闭
- Go deep into the underlying C source code and explain the core design principles of redis
- 潘多拉 IOT 开发板学习(HAL 库)—— 实验8 定时器中断实验(学习笔记)
猜你喜欢

1亿单身男女撑起一个IPO,估值130亿

Icml2022 | partial and asymmetric comparative learning of out of distribution detection in long tail recognition
Tupu software digital twin | visual management system based on BIM Technology
![Cf:b. almost Terry matrix [symmetry + finding rules + structure + I am structural garbage]](/img/5d/06229ff7cfa144dbcb60ae43d5c435.png)
Cf:b. almost Terry matrix [symmetry + finding rules + structure + I am structural garbage]

开源 SPL 消灭数以万计的数据库中间表
Teach you to deal with JS reverse picture camouflage hand in hand
集合处理的利器
企业级数据安全,天翼云是这样理解的
Summary of six points of MySQL optimization
![[today in history] July 5: the mother of Google was born; Two Turing Award pioneers born on the same day](/img/7d/7a01c8c6923077d6c201bf1ae02c8c.png)
[today in history] July 5: the mother of Google was born; Two Turing Award pioneers born on the same day
随机推荐
公司破产后,黑石们来了
Applet modification style (placeholder, checkbox style)
UDF implementation of Dameng database
5. Data access - entityframework integration
EasyCVR授权到期页面无法登录,该如何解决?
Emqx 5.0 officially released: a single cluster supports 100million mqtt connections
5. 数据访问 - EntityFramework集成
Why can't Bi software do correlation analysis? Take you to analyze
cf:B. Almost Ternary Matrix【对称 + 找规律 + 构造 + 我是构造垃圾】
ROS installation error sudo: rosdep: command not found
2022最新大厂Android面试真题解析,Android开发必会技术
Simple query cost estimation
数学分析_笔记_第9章:曲线积分与曲面积分
AI open2022 | overview of recommendation systems based on heterogeneous information networks: concepts, methods, applications and resources
Technology sharing | interface testing value and system
Oracle日期格式转换 to_date,to_char,to_timetamp 相互转换
2022最新Android面试笔试,一个安卓程序员的面试心得
数据库 逻辑处理功能
视频自监督学习综述
在线协作产品哪家强?微软 Loop 、Notion、FlowUs