当前位置:网站首页>[PyTorchVideo Tutorial 01] Quickly implement video action recognition
[PyTorchVideo Tutorial 01] Quickly implement video action recognition
2022-07-30 19:21:00 【CV-Yang Fan】
1 PyTorchVideo介绍
PyTorchVideo是Facebook2021年4月份发布,Mainly for video deep learning applications.
b站:https://www.bilibili.com/video/BV1QT411j7M3
1.1 参考资料:
pytorchvideo官网:https://pytorchvideo.org/
pytorchvideo Github:https://github.com/facebookresearch/pytorchvideo
Tutorials:https://pytorchvideo.org/docs/tutorial_torchhub_inference
深入浅出PyTorch:8.3 PyTorchVideo简介
PyTorchVideo: Deep Learning for Video,你想要的它都有:https://zhuanlan.zhihu.com/p/390909705
PyTorchVideo: A Deep Learning Library for Video Understanding:https://arxiv.org/pdf/2111.09887.pdf
1.2 介绍
近几年来,随着传播媒介和视频平台的发展,视频正在取代图片成为下一代的主流媒体,这也使得有关视频的深度学习模型正在获得越来越多的关注.
然而,有关视频的深度学习模型仍然有着许多缺点:
- 计算资源耗费更多,并且没有高质量的 model zoo,不能像图片一样进行迁移学习和论文复现.
- 数据集处理较麻烦,但没有一个很好的视频处理工具.
- 随着多模态越来越流行,亟需一个工具来处理其他模态.
除此之外,There are also issues such as deployment optimization,为了解决这些问题,Meta推出了PyTorchVideo深度学习库(Contains components such asFigure 1所示).PyTorchVideo 是一个专注于视频理解工作的深度学习库.PytorchVideo 提供了加速视频理解研究所需的可重用、模块化和高效的组件.PyTorchVideo 是使用PyTorch开发的,支持不同的深度学习视频组件,如视频模型、视频数据集和视频特定转换.
Put one before the text beginsdemo,PyTorchVideoDeploy optimization mods through the model(accelerator)It is the first to realize real-time video action recognition on the mobile terminal(基于X3D模型),It is no longer a dream to run video models on the mobile terminal in the future.
PyTorchVideo Real-time video action recognition for mobile
PyTorchVideo A deep learning library for video understanding
3 GPU平台
极链AI:https://cloud.videojj.com/auth/register?inviter=18452&activityChannel=student_invite
镜像快速搭建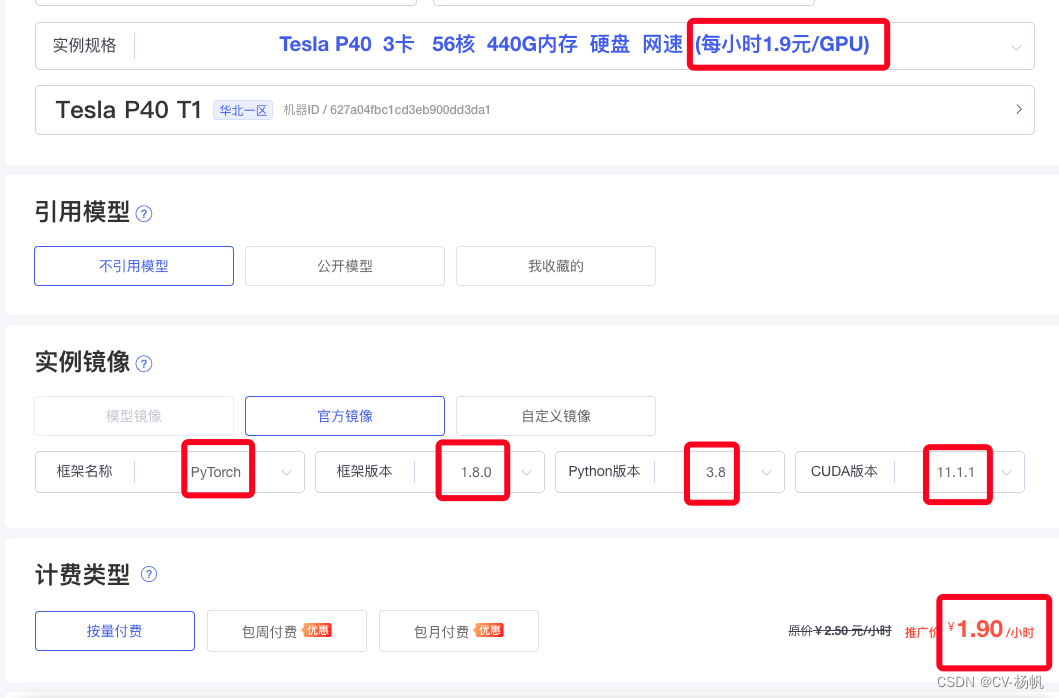
4 安装pytorchvideo
cd /home
pip install pytorchvideo
wget https://dl.fbaipublicfiles.com/pyslowfast/dataset/class_names/kinetics_classnames.json
wget https://dl.fbaipublicfiles.com/pytorchvideo/projects/archery.mp4
如果archery.mp4无法下载,可以先下载好,然后上传,I have uploaded the video resources to Alibaba Cloud Disk:
https://www.aliyundrive.com/s/xjzfmH3uoFB
我在csdnVideo resources are also uploaded:archery.mp4 行为识别 pytorchvideo demo演示视频(行为识别)
5 demo演示
A video needs to be prepared in advance
开始搭建(使用Notebook,Mainly look at the intermediate steps)
import torch
import json
from torchvision.transforms import Compose, Lambda
from torchvision.transforms._transforms_video import (
CenterCropVideo,
NormalizeVideo,
)
from pytorchvideo.data.encoded_video import EncodedVideo
from pytorchvideo.transforms import (
ApplyTransformToKey,
ShortSideScale,
UniformTemporalSubsample,
UniformCropVideo
)
from typing import Dict
# Device on which to run the model
# Set to cuda to load on GPU
device = "cpu"
# Pick a pretrained model and load the pretrained weights
model_name = "slowfast_r50"
model = torch.hub.load("facebookresearch/pytorchvideo", model=model_name, pretrained=True)
# Set to eval mode and move to desired device
model = model.to(device)
model = model.eval()
with open("kinetics_classnames.json", "r") as f:
kinetics_classnames = json.load(f)
# Create an id to label name mapping
kinetics_id_to_classname = {
}
for k, v in kinetics_classnames.items():
kinetics_id_to_classname[v] = str(k).replace('"', "")
####################
# SlowFast transform
####################
side_size = 256
mean = [0.45, 0.45, 0.45]
std = [0.225, 0.225, 0.225]
crop_size = 256
num_frames = 32
sampling_rate = 2
frames_per_second = 30
alpha = 4
class PackPathway(torch.nn.Module):
""" Transform for converting video frames as a list of tensors. """
def __init__(self):
super().__init__()
def forward(self, frames: torch.Tensor):
fast_pathway = frames
# Perform temporal sampling from the fast pathway.
slow_pathway = torch.index_select(
frames,
1,
torch.linspace(
0, frames.shape[1] - 1, frames.shape[1] // alpha
).long(),
)
frame_list = [slow_pathway, fast_pathway]
return frame_list
transform = ApplyTransformToKey(
key="video",
transform=Compose(
[
UniformTemporalSubsample(num_frames),
Lambda(lambda x: x/255.0),
NormalizeVideo(mean, std),
ShortSideScale(
size=side_size
),
CenterCropVideo(crop_size),
PackPathway()
]
),
)
# The duration of the input clip is also specific to the model.
clip_duration = (num_frames * sampling_rate)/frames_per_second
# Load the example video
video_path = "archery.mp4"
# Select the duration of the clip to load by specifying the start and end duration
# The start_sec should correspond to where the action occurs in the video
start_sec = 0
end_sec = start_sec + clip_duration
# Initialize an EncodedVideo helper class
video = EncodedVideo.from_path(video_path)
# Load the desired clip
video_data = video.get_clip(start_sec=start_sec, end_sec=end_sec)
# Apply a transform to normalize the video input
video_data = transform(video_data)
# Move the inputs to the desired device
inputs = video_data["video"]
inputs = [i.to(device)[None, ...] for i in inputs]
# Pass the input clip through the model
preds = model(inputs)
# Get the predicted classes
post_act = torch.nn.Softmax(dim=1)
preds = post_act(preds)
pred_classes = preds.topk(k=5).indices
# Map the predicted classes to the label names
pred_class_names = [kinetics_id_to_classname[int(i)] for i in pred_classes[0]]
print("Predicted labels: %s" % ", ".join(pred_class_names))
处理结果:
Predicted labels: archery, throwing axe, playing paintball, disc golfing, riding or walking with horse

边栏推荐
- 卫星电话是直接与卫星通信还是通过地面站?
- 延时队列优化 (2)
- MindSpore:npu 多卡训练自定义数据集如何给不同npu传递不同数据
- NXP IMX8QXP replacement DDR model operation process
- Another company interview
- Perfectly Clear QuickDesk & QuickServer图像校正优化工具
- MindSpore:ImageFolderDataset数据读取问题
- 技术很牛逼,还需要“向上管理”吗?
- Talking about Contrastive Learning (Contrastive Learning) the first bullet
- [Prometheus] An optimization record of the Prometheus federation [continued]
猜你喜欢

深入浅出边缘云 | 3. 资源配置

Basic use of scrapy

【剑指 Offe】剑指 Offer 18. 删除链表的节点

MindSpore:【JupyterLab】按照新手教程训练时报错

NXP IMX8QXP更换DDR型号操作流程
MindSpore:ImageFolderDataset数据读取问题

Alibaba Cloud Martial Arts Headline Event Sharing

The use of @ symbol in MySql

OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.解决方法

解决终极bug,项目最终能顺利部署上线。
随机推荐
【私人系列】日常PHP遇到的各种稀奇古怪的问题
The advanced version of the Niu Ke brushing series (team competition, sorting subsequences, inverting strings, deleting common characters, repairing pastures)
卫星电话是直接与卫星通信还是通过地面站?
阿里云武林头条活动分享
MindSpore:数据处理问题
ImportError:attempted relative import with no known parent package
浅聊对比学习(Contrastive Learning)第一弹
电脑死机的时候,发生了什么?
【每日一道LeetCode】——191. 位1的个数
2种手绘风格效果比较,你更喜欢哪一种呢?
VBA runtime error '-2147217900 (80040e14): Automation error
VBA 连接Access数据库和Excle
SimpleOSS third-party library libcurl and engine libcurl error solution
【PHPWord】Quick Start of PHPWord in PHPOffice Suite
LeetCode 0952.按公因数计算最大组件大小:建图 / 并查集
NXP IMX8QXP replacement DDR model operation process
Scala学习:类和对象
055 c# print
- daily a LeetCode 】 【 191. A number of 1
Tensorflow2.0 confusion matrix does not match printing accuracy