当前位置:网站首页>【Transform】【实践】使用Pytorch的torch.nn.MultiheadAttention来实现self-attention
【Transform】【实践】使用Pytorch的torch.nn.MultiheadAttention来实现self-attention
2022-07-03 14:53:00 【Hali_Botebie】
Self-Attention的结构图
本文侧重于Pytorch中对self-attention的具体实践,具体原理不作大量说明,self-attention的具体结构请参照下图。
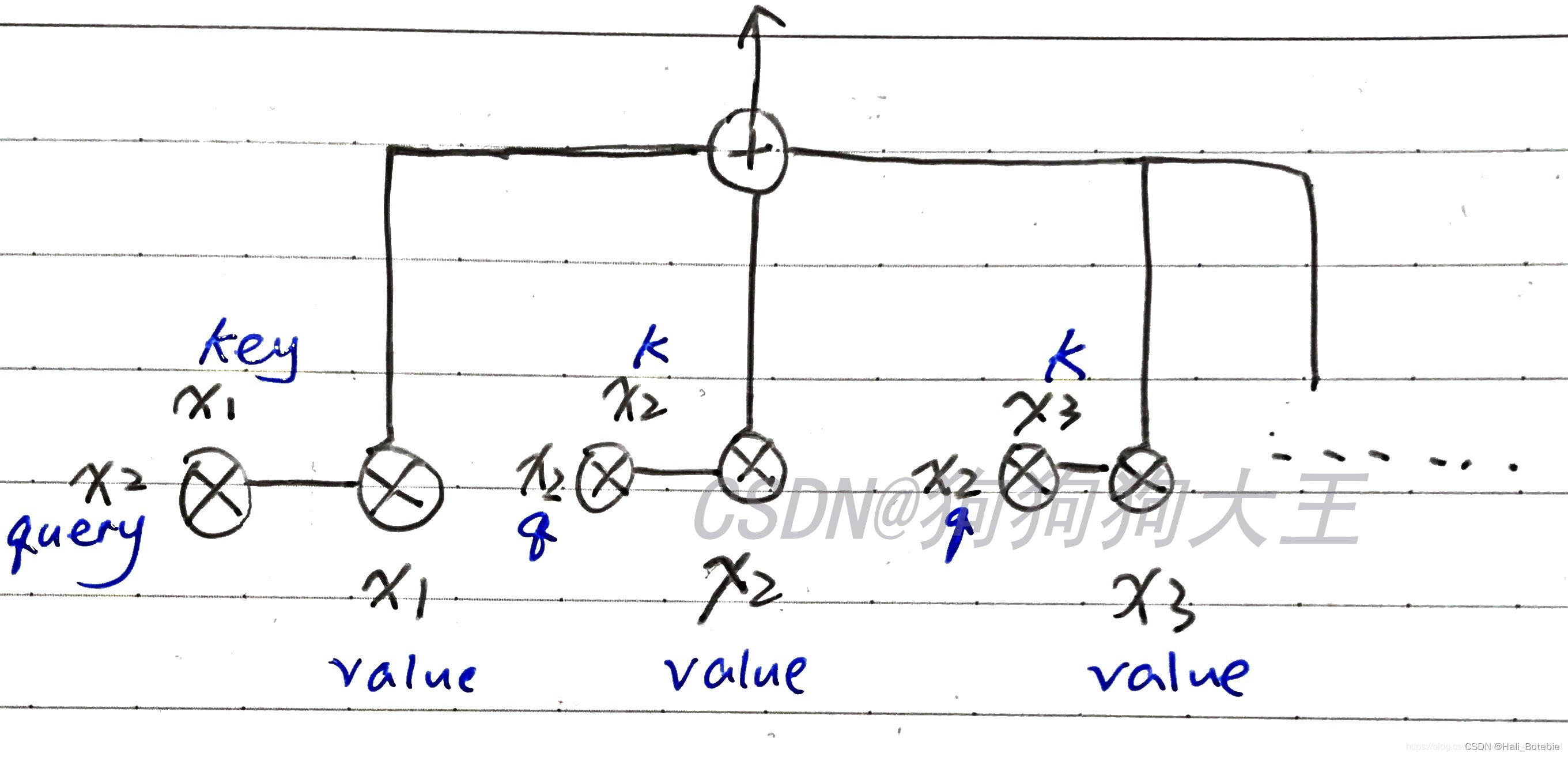
(图中为输出第二项attention output的情况,k与q为key、query的缩写)
本文中将使用Pytorch的torch.nn.MultiheadAttention来实现self-attention.
所谓的multihead-attention 是对KQV的并行计算。原始的attention 是直接计算“词向量长度(维度)的向量”,而Multi是先将“词向量长度(维度)的向量”通过linear 层,分位h 个head 计算attention,然后将这些attention 连接在一起后,再经过一个linear 层输出。可以看出,linear 层的输入和输出维度都是“词向量长度(维度)”。

从图片中可以看出V K Q 是固定的单个值,而Linear层有3个,Scaled Dot-Product Attention 有3个,即3个多头;最后cancat在一起,然后Linear层转换变成一个和单头一样的输出值;类似于集成;多头和单头的区别在于复制多个单头,但权重系数肯定是不一样的;类比于一个神经网络模型与多个一样的神经网络模型,但由于初始化不一样,会导致权重不一样,然后结果集成;(初步理解)
多头函数看出:multihead-attention 函数输入为由原来的Q,K,V变成了 Q W , K W , V W Q^W,K^W,V^W QW,KW,VW;即3个W都不相同;将Q,K,V由原来的512维度变成了64维度(因为采取了8个多头);然后再拼接在一起变成512维,通过线性转换;得到最终的多头注意力值;
个人最终认为:多头的本质是多个独立的attention计算,作为一个集成的作用,防止过拟合;从attention is all your need论文中输入序列是完全一样的;相同的Q,K,V,通过线性转换,每个注意力机制函数只负责最终输出序列中一个子空间,即1/8,而且互相独立;
微观下的多头Attention可以表示为:

KQV

forward输入中的query、key、value
首先,前三个输入是最重要的部分query、key、value。由图1可知,我们self-attention的这三样东西其实是一样的,它们的形状都是:(L,N,E) 。
L:输入sequence的长度(例如一个句子的长度)
N:批大小(例如一个批的句子个数)
E:词向量长度
forward的输出
输出的内容很少只有两项:
attn_output
即通过self-attention之后,从每一个词语位置输出来的attention。其形状为(L,N,E),是和输入的query它们形状一样的。因为毕竟只是给value乘了一个weight。attn_output_weights
即attention weights,形状是(N,L,L),因为每一个单词和任意另一个单词之间都会产生一个weight,所以每一句句子的weight数量是L*L
实例化一个nn.MultiheadAttention
这里对MultiheadAttention进行一个实例化并传入一些参数,实例化之后我们得到的东西我们就可以向它传入input了。
实例化时的代码:
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
其中,embed_dim是每一个单词本来的词向量长度;num_heads是我们MultiheadAttention的head的数量。
(关于embedding 是什么?可以看另一篇博客,nn.Embedding具有一个权重(.weight),形状是(num_words, embedding_dim)。Embedding的输入形状N×W,N是batch size,W是序列的长度,输出的形状是N×W×embedding_dim。例如只有一个样本,一个句子的长度一共有10个词,每个词用256维向量表征,对应的权重就是一个10×256的矩阵,输出形状为 1 × 10 × 256,则embed_dim是每一个单词本来的词向量长度是256 )
pytorch的MultiheadAttention应该使用的是Narrow self-attention机制,即,把embedding分割成num_heads份,每一份分别拿来做一下attention。
(例如,embed_dim 是256,num_heads是8,则会分成8份,每一份的维度是32)
也就是说:
- 单词1的第一份、单词2的第一份、单词3的第一份…会当成一个sequence,做一次我们图1所示的self-attention。
- 然后,单词1的第二份、单词2的第二份、单词3的第二份…也会做一次
- 直到单词1的第num_heads份、单词2的第num_heads份、单词3的第num_heads份…也做完self-attention
从每一份我们都会得到一个(L,N,E/num_heads)形状的输出,我们把这些全部concat在一起,会得到一个(L,N,E)的张量。
(例如。每一份self attention 得到一个10 × 1 × 32,concat 后得到 10×1×256 的张量)
这时候,我们拿一个矩阵,把这个张量的维度变回(L,N,E)即可输出。
进行forward操作
我们把我们刚才实例化好的multihead_attn拿来进行forward操作(即输入input得到output):
attn_output, attn_output_weights = multihead_attn(query, key, value)
关于mask
mask可以理解成遮罩、面具,作用是帮助我们“遮挡”掉我们不需要的东西,即让被遮挡的东西不影响我们的attention过程。
在forward的时候,有两个mask参数可以设置:
key_padding_mask
每一个batch的每一个句子的长度一般是不可能完全相同的,所以我们会使用padding把一些空缺补上。而这里的这个key_padding_mask是用来“遮挡”这些padding的。
这个mask是二元(binary)的,也就是说,它是一个矩阵和我们key的大小是一样的,里面的值是1或0,我们先取得key中有padding的位置,然后把mask里相应位置的数字设置为1,这样attention就会把key相应的部分变为"-inf". (为什么变为-inf我们稍后再说)attn_mask
这个mask经常是用来遮挡“正确答案”的:
假如你想要用这个模型每次预测下一个单词,我们每一个位置的attention输出是怎么得来的?是不是要看一遍整个序列,然后每一个单词都计算一个attention weight?那也就是说,你在预测第5个词的时候,你其实会看到整个序列,这样的话你在预测之前不就已经知道第5个单词是什么了,这就是作弊了。
我们不想让模型作弊,因为在真实使用这个模型去预测的时候,我们是没有整个序列的信息的。那么怎么办?那就让第5个单词的attention weight=0吧,即声明:我不想看这个单词,我的注意力一点也别分给它。
如何让这个weight=0:
我们先想象一下,我们目前拥有的attention scores是什么样的?(注:attention_score是attention_weight的初始样子,经过softmax之后会变成attention_weight.
attention_score和weight的形状是一样的,毕竟只有一个softmax的差别)
我们之前提到,attention weights的形状是L*L,因为每个单词两两之间都有一个weight。
如下图所示,我用蓝笔圈出的部分,就是“我想要预测 x 2 x_2 x2”时,整个sequence的attention score情况。我用叉划掉的地方,是我们希望=0的位置,因为我们想让 x 2 、 x 3 、 x 4 x_2、x_3、x_4 x2、x3、x4的权值为0,即:预测 x 2 x_2 x2的时候,我们的注意力只能放在 x 1 x_1 x1上。
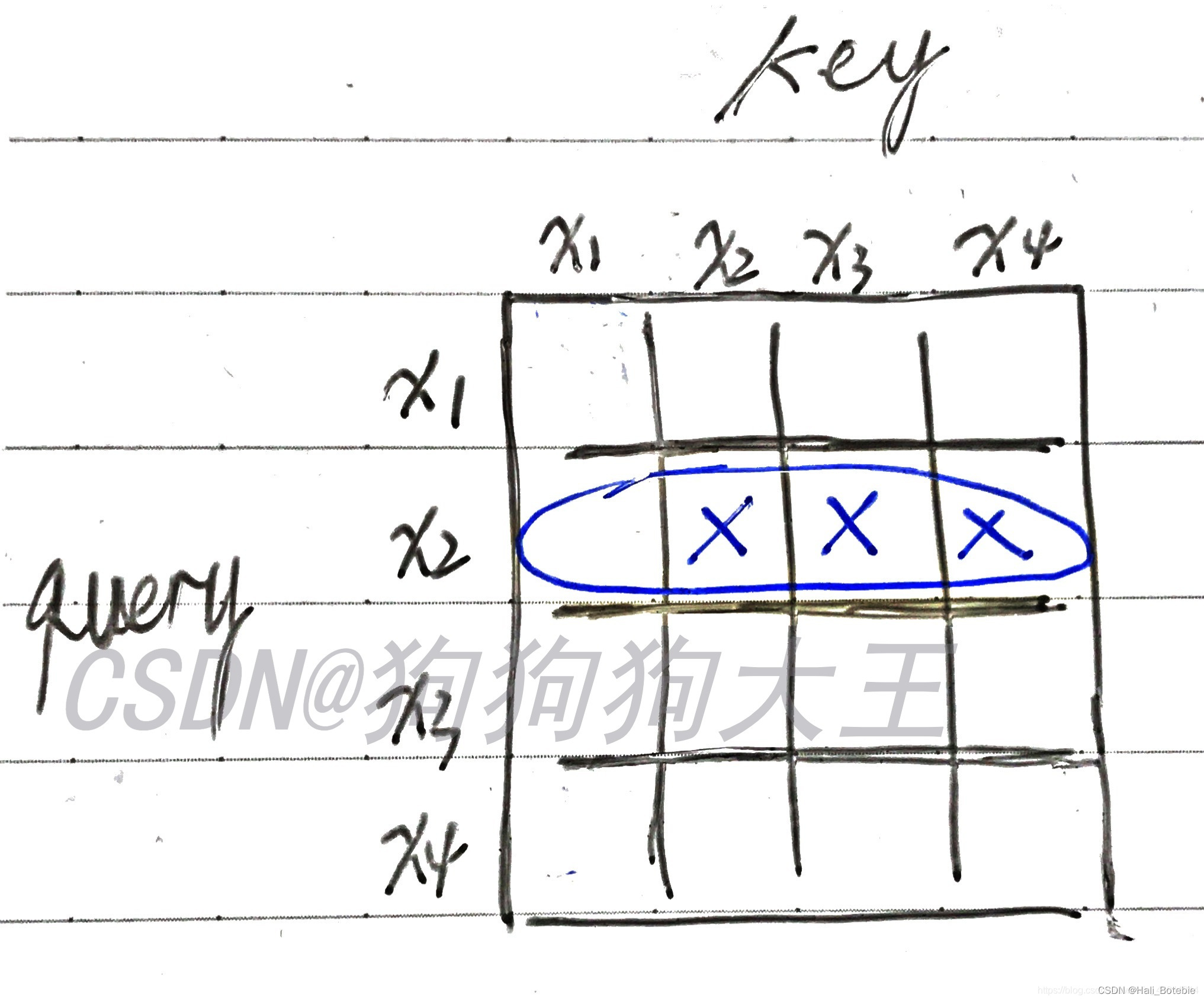
对于其他行,你可以以此类推,发现我们需要一个三角形区域的attention weight=0, 这时候我们的attn_mask这时候就出场了,把这个mask做成三角形即可。
关于mask的题外话:
有朋友好奇为什么有的地方看到的图mask了对角线有的没有,应该是因为sequence不同或者训练任务/方式不同,但本质上mask的原理是一样的。我再找一张图帮助大家理解,比如如果加上s(start)和e(end)的话就是类似这样:( 白色为mask掉的部分)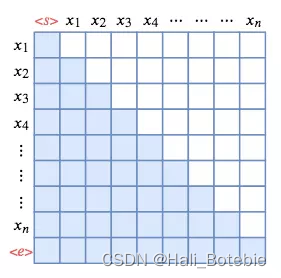
mask的值(additive mask)
现在我们来说mask的值。和key_padding_mask不同,我们的attn_mask不是binary的,而是一个“additive mask”。
什么是additive mask呢?就是我们mask上设置的值,会被加到我们原本的attention score上。我们要让三角形区域的weight=0,我们这个三角mask设置什么值好呢?答案是-inf,(这个-inf在key_padding_mask的讲解中也出现了,这里就来说说为什么要用-inf)。我们上面提到了,attention score要经过一个softmax才变成attention_weights.
我们都知道softmax的式子可以表示为
当我们attention score的值设置为-inf (可以看作这里式子里的 z j = − inf z_j=-\inf zj=−inf,于是通过softmax之后我们的attention weight就会趋近于0了,这就是为什么我们这里的两个mask都要用到-inf。
参考
超平实版Pytorch Self-Attention: 参数详解(尤其是mask)(使用nn.MultiheadAttention)
边栏推荐
猜你喜欢
How does vs+qt set the software version copyright, obtain the software version and display the version number?
![[engine development] rendering architecture and advanced graphics programming](/img/a4/3526a4e0f68e49c1aa5ce23b578781.jpg)
[engine development] rendering architecture and advanced graphics programming
![[graphics] hair simulation in tressfx](/img/41/cef55811463d3a25a29ddab5278af0.jpg)
[graphics] hair simulation in tressfx
Rasterization: a practical implementation (2)
Zero copy underlying analysis

Devaxpress: range selection control rangecontrol uses
Pyqt interface production (login + jump page)

Yolov5系列(一)——网络可视化工具netron

Introduction to opengl4.0 tutorial computing shaders
![[ue4] cascading shadow CSM](/img/83/f4dfda3bd5ba0172676c450ba7693b.jpg)
[ue4] cascading shadow CSM
随机推荐
The picture quality has been improved! LR enhancement details_ Lightroom turns on AI photo detail enhancement: picture clarity increases by 30%
Amazon, express, lazada, shopee, eBay, wish, Wal Mart, Alibaba international, meikeduo and other cross-border e-commerce platforms evaluate how Ziyang account can seize traffic by using products in th
Optical cat super account password and broadband account password acquisition
表单文本框的使用(一) 选择文本
C language memory function
提高效率 Or 增加成本,开发人员应如何理解结对编程?
Open under vs2019 UI file QT designer flash back problem
QT - draw something else
Global and Chinese market of optical fiber connectors 2022-2028: Research Report on technology, participants, trends, market size and share
牛客 BM83 字符串变形(大小写转换,字符串反转,字符串替换)
Use of form text box (I) select text
Qt development - scrolling digital selector commonly used in embedded system
Centos7 deployment sentry redis (with architecture diagram, clear and easy to understand)
Zzuli:1056 lucky numbers
TPS61170QDRVRQ1
Zzuli:1045 numerical statistics
复合类型(自定义类型)
Zzuli:1041 sum of sequence 2
牛客 BM83 字符串變形(大小寫轉換,字符串反轉,字符串替換)
How to color ordinary landscape photos, PS tutorial