当前位置:网站首页>【论文阅读|深读】Role2Vec:Role-Based Graph Embeddings
【论文阅读|深读】Role2Vec:Role-Based Graph Embeddings
2022-06-30 03:33:00 【海轰Pro】
目录

前言
Hello!
非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~
自我介绍 ଘ(੭ˊᵕˋ)੭
昵称:海轰
标签:程序猿|C++选手|学生
简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金,有幸在竞赛中拿过一些国奖、省奖…已保研。
学习经验:扎实基础 + 多做笔记 + 多敲代码 + 多思考 + 学好英语!
唯有努力
知其然 知其所以然!
本文仅记录自己感兴趣的内容
Abstract
随机游走是许多现有的节点嵌入和网络表示学习方法的核心
传统的随机游走的限制:
- 由这些方法产生的嵌入捕获顶点之间的邻近性(社区),而不是结构相似性(角色)
- 此外,嵌入无法转移到新的节点和图,因为它们与节点标识绑定在一起
为了克服这些限制,我们引入了Role2Vec框架,该框架基于所提出的属性随机游走的概念来学习基于角色的结构化嵌入
值得注意的是,该框架可作为泛化任何基于行走的方法的基础
- Role2Vec框架通过学习捕获图中结构角色的归纳函数,使这些方法能够得到更广泛的应用
- 此外,当每个顶点被映射到它自己的唯一标识它的函数时,原始方法被恢复为框架的特殊情况
1 INTRODUCTION
受词嵌入模型(如skip-gram模型[6]、[7])成功的启发,最近的一些作品将词嵌入模型扩展到学习图(节点)嵌入[8]、[9]、[10]、[11]
这些工作的主要目标是建立将每个输入顶点与其上下文联系起来的条件概率模型
上下文是与输入顶点相关的其他顶点的集合
许多现有的节点嵌入方法使用随机游走(基于节点id)来生成上下文顶点[8]、[9]、[10]、[12]。
例如,DeepWalk[8]从每个顶点开始随机漫步,收集顶点序列(类似于语言中的句子)
然后,使用跳跃图模型通过最大化每个输入顶点与其周围环境之间的条件概率来拟合嵌入
因此,在跳过图模型中,顶点身份被用作单词,嵌入被绑定到顶点id
在语言中,具有相似含义的单词被假定包围在相似的上下文[13]中
因此,在语言模型中,单词的上下文被定义为周围的单词[6],[7]
然而,这个想法并不能直接转化为图表
因为语言中的单词没有与特定文档或语料库绑定的正式定义,通过遍历获得的顶点id是任意的,并且只在特定的图中有意义
在另一个图中就不起作用了
因此,这些基于行走的方法有三个主要缺点
- 首先,这些嵌入方法本质上是转导的,本质上处理孤立的图,不能推广到看不见的节点,也不能跨网络转移,它们不适用于跨网络分类[14]、[15]和图相似性/比较[16]、[17]等基于图的迁移学习任务
- 其次,使用这种传统的随机游走定义,在嵌入中没有集成顶点属性/特征的通用方法
- 最后,这些方法无法学习捕获结构角色的结构节点嵌入
结构角色发现[18]的目的是将具有结构相似的邻域(连接/子图模式)的节点嵌入在一起,同时允许节点在图中很远,甚至在完全不同的图中[19]
节点角色的示例包括充当枢纽、星形边、近边和连接图中不同区域的桥梁的节点
直观地说
- 如果两个顶点在结构上相似,不需要用边连接,也不属于同一个社区,甚至不属于同一个图[18],那么它们就属于同一个角色
- 图中的角色表示一般的结构功能,与顶点id无关,因此可以跨网络转移
虽然最近许多流行的嵌入方法是基于传统的带id的随机游动
- 但这些方法无法学习保留结构相似性概念的基于结构角色的嵌入
- 相反,它们学习了基于邻近的嵌入,这种嵌入保留了图[11]中节点之间的接近和接近的概念。
- 因此,这些方法保证将图中接近的节点嵌入到一起(社区[23]的一个属性),因为它们在随机游走中出现在彼此附近,而不是基于[18]中提出的结构相似性概念将节点嵌入到一起的结构角色
- 此外,基于行走的嵌入方法从根本上也与节点身份绑定,因此不能在网络中归纳或转移。
然而,角色表示一般的结构功能,自然地归纳和可转移,因为它们可以在任何图上导出,独立于顶点id
因此,共享类似角色嵌入的两个节点可以位于不同的社区,甚至完全位于不同的图中
这与传统的基于行走的方法形成了对比
- 在传统的方法中,不同图/组件中的节点显然不能一起出现在相同的随机行走中
- 因此,尽管不同图中的节点可能在结构上相似,因此执行相同的结构角色(功能),但使用这些先前的方法永远不会分配类似的嵌入
在这项工作中,我们提出了Role2Vec框架,作为推广许多使用随机游动的现有方法的基础
特别地,我们引入了带有属性的随机游走的概念
它不与顶点一致性绑定,而是基于一个函数 Φ : x → w \Phi:x\rightarrow w Φ:x→w
它将顶点属性向量映射到一个角色(类型、标签、属性值)
这样,如果两个顶点在结构上相似,它们就属于同一个角色
因此,Role2Vec的目标是建立将每个顶点角色与其上下文角色联系起来的条件概率模型
Role2Vec框架为任何被它推广的方法提供了许多重要的优势:
首先,提出的框架是自然归纳的,因为学习的嵌入推广到新的节点和跨图,因此可以用于迁移学习任务。
其次,它们能够捕获结构相似性(角色)
第三,提出的框架是固有的空间高效,因为嵌入是为角色学习的(与顶点相反),因此比现有方法需要更少的空间。
第四,提出的框架自然支持带有输入属性的图(如果可用)。此外,任何使用Role2Vec框架泛化的方法都保证至少执行得和原始方法一样好,因为当函数 Φ \Phi Φ将每个节点映射到一个唯一的角色时,它被恢复为框架的一个特殊情况。
最后,Role2Vec被证明是有效的,平均提高了17.8%的AUC,同时在不同领域的各种图上比现有的最先进的方法平均减少了853倍的空间。
以前的工作主要集中在节点级别[8],[9],[10],[12],[24]的学习嵌入
本文提出了一个在角色级别学习嵌入的框架
- 与节点级嵌入相比,角色嵌入在跨网络迁移学习任务中总是可迁移的,例如跨网络链路预测和节点分类[24]
- 角色嵌入对于基于图的异常检测、图摘要/压缩、图相似度查询(寻找结构相似的节点)、意义构建和网络探索性分析、网络可视化以及[18]、[19]等任务也特别有用
- 此外,角色嵌入使用的空间也大大减少(当 M < N v M < N_v M<Nv时),因此对于需要实时性能的应用程序以及涉及大规模(流)图数据的应用程序也很有用
2 FRAMEWORK
G = ( V , E ) G=(V, E) G=(V,E)
N v = ∣ V ∣ N_v=|V| Nv=∣V∣:图G的顶点数量
N e = ∣ E ∣ N_e=|E| Ne=∣E∣:图G的边的数量
Γ i \Gamma_i Γi:顶点 v i v_i vi的邻域
d i = ∣ Γ i ∣ d_i = |\Gamma_i| di=∣Γi∣:顶点 v i v_i vi的度
X X X:一个属性/特征矩阵 X X X,其中每个 x i x_i xi是顶点 v i v_i vi的 k k k维向量(由属性向量构成的矩阵)
M M M:角色数量
W W W:角色集,其中 w ∈ W w \in W w∈W是分配给一个或多个节点的角色
α k \alpha_k αk:角色 w k w_k wk的 D D D维嵌入向量

我们的框架不需要任何输入属性,因为我们总是可以根据输入/输出/总/加权度、egonet、motif/graphlet计数等获得结构特征。
嵌入方法的目标是通过学习将每个图元素映射到隐维空间的模型来派生特定图元素的有用特征(例如,顶点,边)
虽然该方法仍然适用于任何图元素,但本文重点关注顶点嵌入
为了实现这一点,一个可能的嵌入定义包含三个通用组件:
- 上下文函数,它指定了一组其他的顶点,称为上下文 c i c_i ci对于任何给定的顶点 v i v_i vi,这样上下文顶点围绕和/或拓扑上与给定顶点相关。每个顶点都与两个潜在向量相关联,一个嵌入向量 α i ∈ R D \alpha_i \in R^D αi∈RD和一个上下文向量 β i ∈ R D \beta_i \in R^D βi∈RD
- 条件分布,它指定用于组合嵌入向量和上下文向量的统计分布。更具体地说,一个顶点的条件分布结合了它的嵌入和它周围顶点的上下文向量。
- 模型参数(例如,嵌入向量和上下文向量)以及如何在条件分布中共享这些参数。因此,一种嵌入方法将每个顶点与其上下文关联的条件概率建模如下:

其中 c i c_i ci是顶点 v i v_i vi的上下文顶点集合, x i x_i xi是它的属性向量, P P P是条件分布
我们的目标是建模 P [ x c i ∣ x i ] = ∏ j ∈ c i P ( x j ∣ x i ) P[x_{c_i} | x_i] = \prod_{j\in c_i} P(x_j|x_i) P[xci∣xi]=∏j∈ciP(xj∣xi)
假设上下文顶点是有条件独立的
最常用的条件分布是分类分布
在这种情况下,使用两个潜在向量(即嵌入向量和上下文向量)参数化的softmax函数
因此,对于每个输入上下文顶点对 ( v i , v j ) (v_i, v_j) (vi,vj)

对于稀疏图, ∑ v k ∈ V e α i ⋅ β k \sum_{v_k \in V}e^{\alpha_i\cdot\beta_k} ∑vk∈Veαi⋅βk中的求和包含许多零项,因此可以通过对这些零项进行次采样来近似(使用类似于语言模型[6]的负采样)
最后,嵌入方法的目标函数为每个顶点的似然值对数之和,即:

显然,有一类可能的嵌入方法,其中三个组件(上面讨论的)中的每一个都被认为是具有各种替代方案的建模选择
最近的工作提出了随机游走来采样/收集上下文顶点 c i c_i ci[8],[9]
注意,对于这些基于随机游走的嵌入方法, x i x_i xi只是顶点 v i v_i vi的指示向量,没有属性
2.1 Mapping Vertices to Vertex-Roles 顶点映射到顶点角色
给定:
- 有(无)向图 G = ( V , E ) G = (V, E) G=(V,E)
- N v × K N_v \times K Nv×K矩阵 X X X的属性(如果可用) 和/或 结构特征(可以从G单独计算)
Role2Vec框架从定位顶点集合开始
与集合中任意两个之间的距离(接近程度)无关
它们被放置在与所有其他顶点集合相似的位置
因此,如果两个顶点在结构特征(和/或输入属性)方面相似,它们就属于同一个集合
在这项工作中,矩阵 X X X由基于graphlets/network motif[25]的结构特征组成
这些特征已知用于捕获节点[19]的基于角色的结构属性
我们通过学习(或手动定义)一个函数来实现这一点
该函数将 N v N_v Nv个顶点映射到集合 W = { w 1 , . . . , w M } W=\{w_1,...,w_M\} W={ w1,...,wM},其中顶点角色数量 M , M ≤ N v M,M \leq N_v M,M≤Nv

因此, Φ \Phi Φ是一个基于 N v × K N_v \times K Nv×K属性矩阵 X X X将顶点映射到顶点角色的函数
显然,函数 Φ \Phi Φ是建模选择[27],可以自动学习,也可以由用户手动定义
我们探讨两个一般的映射函数类
1)第一类映射函数
简单函数,如下

其中
- x = [ x 1 x 2 ⋯ x k ] x = [x_1 x_2 \cdots x_k] x=[x1x2⋯xk]是一个属性向量
- ∘ \circ ∘是一个二元运算符,如连接、和等
直观地说,给定一组结构特征(例如,3或4节点的graphlet计数[25])
并假设在Eq.(5)中使用连接作为二元运算符
那么如果两个节点具有相同的结构特征,则它们属于同一个角色
为了使不同的映射函数更有用,我们可以首先对特征 应用特征转换技术。
例如,我们可以在使用等式(5)之前对每个特性执行log binning。这有两个主要后果:
首先,它允许节点处于相同的角色,即使它们没有相同的特性值。因此,在结构属性方面足够相似的节点属于相同的角色
其次,log bin和其他特征转换技术可以用来控制角色的数量(例如,通过改变log bin中的bin大小等)
Logarithmic binning将第一个 σ N v \sigma N_v σNv节点属性值最小的节点分配为0(其中 0 < σ < 1 0 < \sigma < 1 0<σ<1)
然后将剩余未分配节点中属性值最小的 σ \sigma σ部分分配为1,依此类推
2)第二类映射函数
这类函数是通过优化目标函数来学习的。
这包括基于 N v × K N_v \times K Nv×K矩阵 X X X的低秩分解的映射函数,其形式为 X ≈ F ( U V T ) X\approx F(UV^T) X≈F(UVT)
- 因子矩阵为 U ∈ R N v × r U \in R^{N_v \times r} U∈RNv×r和 V ∈ R K × r V \in R^{K \times r} V∈RK×r,
- 其中 r > 0 r > 0 r>0是秩
- f f f是线性或非线性函数
更正式定义

- 式中D为损失
- C为约束(如非负性约束 U ≥ 0 , V ≥ 0 U \geq 0, V \geq 0 U≥0,V≥0)和
- R ( U , V ) R(U,V) R(U,V)是正则化的惩罚
然后,我们将 U ∈ R N v × r U \in R^{N_v \times r} U∈RNv×r划分为 M M M个不相交的节点集(对于每一个顶点角色) { V 1 , . . . , V M } \{V_1, ..., V_M\} { V1,...,VM}
其中 V j V_j Vj是通过求解k-means目标映射到顶点角色 w j ∈ W w_j \in W wj∈W的顶点集合

注意
- 任何其他的集群方法都可以用来将节点分配给角色,k-means只是作为一个例子
- 这些方法的一个关键优点是,我们可以简单地包含所有这些属性,而不需要选择适当的子集来使用
- 因此,这些方法对于选择不同的结构特性/属性集更加可靠
2.2 Attributed Random Walks 属性随机游走
最近,随机漫步在学习网络嵌入[8],[9]中受到了很多关注,特别是在生成上下文顶点方面
考虑一个长度为 L L L的随机漫步
- 从输入图G的顶点 v 0 v_0 v0开始
- 如果在时刻 t t t我们在顶点 v t v_t vt
- 那么在时刻 t + 1 t+1 t+1,我们以 1 / d v t 1/d_{vt} 1/dvt的概率移动到 v t v_t vt的一个邻居
因此,由此产生的随机选择的顶点指标序列 ( v t : t = 0 , 1 , . . . , L − 1 ) (v_t:t=0,1,...,L-1) (vt:t=0,1,...,L−1)遵循马尔可夫链
然而,这些方法的一个关键限制是,基于随机游动学习的嵌入基本上与顶点 i d id id绑定
在这项工作中,我们引入了一个属性(基于特征)随机游走的概念,以克服这些限制。
此外,我们从理论上证明了在 M < N v M < N_v M<Nv的情况下,基于所提出的带属性游走概念的广义方法更节省空间,而且通常更精确
因为前面的方法作为框架的特殊情况出现在 M → N v M\rightarrow N_v M→Nv
形式上,由节点(结构)特征值/类型/标签/属性组成的遍历定义如下:
Definition 1 (Attributed walk)
设 x i x_i xi是顶点 v i v_i vi的 k k k维向量
一个带属性的步长 L L L是一个相邻顶点角色的序列为:

- 由随机选取的指标序列 ( v t : t = 0 , 1 , . . . , L − 1 ) (v_t:t=0,1,...,L-1) (vt:t=0,1,...,L−1)由从 v 0 v_0 v0开始的长度为 L L L的随机游走和一个函数 Φ : x → w \Phi:x \rightarrow w Φ:x→w将输入矢量映射到顶点角色 Φ ( x ) \Phi(x) Φ(x)
- 序列 Φ ( x v 0 ) , . . . , Φ ( x v t ) , . . . , Φ ( x v L − 1 ) \Phi(x_{v_0}),...,\Phi(x_{v_t}),...,\Phi(x_{v_{L-1}}) Φ(xv0),...,Φ(xvt),...,Φ(xvL−1)是在遍历过程中发生的节点角色,称为带属性的(或基于特性的)随机遍历
值得注意的是,所提出的带属性遍历的概念可以以多种方式使用,并自然地产生了具有许多重要属性的新嵌入方法。
例如,不使用映射函数(可以认为是用恒等函数替换 Φ \Phi Φ)
我们可以简单地使用一个或多个特性来为每个不同的特性派生基于特性的遍历
Role2vec框架使用顶点映射函数和带属性的随机游动来学习嵌入
因此,我们的目标是模拟条件概率,将每个顶点角色与其上下文的角色联系起来,

因此,嵌入结构(即嵌入向量和上下文向量)在具有相同顶点角色的顶点之间共享
具体来说,我们学习了每个顶点集合 V j V_j Vj的 α j ∈ R D \alpha_j \in R^D αj∈RD和 β j ∈ R D \beta_j \in R^D βj∈RD,它们被映射到顶点角色 w j w_j wj
注意role2vec学习了聚合网络的嵌入,其中单个顶点之间的详细关系被聚合为顶点-角色之间的总关系
从Role2Vec框架推广的任何方法中学到的角色嵌入也被分配到节点(或边),因此代表了一类结构节点嵌入
2.3 Generalizing Embedding Methods
本节使用基于带属性遍历概念的Role2Vec框架泛化一类基于遍历的嵌入方法。
为了简单起见,我们主要关注基于SkipGram模型的方法,如DeepWalk、Node2Vec和许多其他方法。
然而,很容易利用Role2Vec框架以某种方式泛化其他使用传统遍历(带id)的技术类,例如[28]、[29]。
算法1显示了一种使用属性遍历的通用嵌入方法

请注意,为了简单/方便,算法1中的广义嵌入方法被称为Role2Vec
然而,Role2Vec框架和带属性漫步的概念可以被其他研究人员用于推广其他使用传统漫步的重要嵌入和表示学习方法
算法1取以下输入:
- (1)图G
- (2)属性矩阵X
- (3)嵌入维度D
- (4)每个顶点的行走量R(每个顶点的重复采样次数)
- (5)行走长度L
- (6)上下文窗口大小v
在第3行中,如果 X X X不可用,我们使用图结构本身派生结构特征
然而,即使(内在/自身或结构)属性作为输入,我们也可以选择派生额外的结构特性,如in/out/total degree/graphlets[25],并将这些附加到 X X X
在这项工作中,小的诱导子图被称为graphlets/ network motifs。motif模式的计数对于捕获顶点的局部结构很有用,并且可以通过并行算法[25]快速高效地计算
由于包括图形在内的许多图形属性都呈现幂律分布[24],[25],[30],[31],[32],[33],我们使用log binning对 X X X进行预处理(第4行)
在第5行中,使用在2.1节中讨论的 Φ ( x ) \Phi(x) Φ(x)函数将顶点映射到角色。
然后,我们预先计算随机游走转移概率 π \pi π,可以是均匀的,也可以是加权的(第6行)。
第8-13行使用带属性随机游动的概念(使用别名采样[34])从每个顶点开始随机游动。最后,Role2Vec使用第14行中的随机梯度下降学习嵌入。
回想一下, N v N_v Nv为节点数, M M M为角色数, M < < N v M <<N_v M<<Nv
Role2vec具有以下属性:
- Role2vec具有空间复杂度,具有空间效率。 O ( M D + N v ) O(MD+N_v) O(MD+Nv)
此外,值得注意的是,Role2Vec学习到的嵌入(空间)的大小不依赖于图的大小(节点和/或边)
因为最后都是对角色进行随机游走、建模,所以应该是与图中角色数量 M M M有关
这是现有方法之间的根本区别,也是Role2Vec框架和提出的基于特性的行走概念的重要关键优势
学习这样的图大小独立的嵌入最近被形式化为潜在的网络总结问题[35]
当 M → N v M\rightarrow N_v M→Nv,我们将传统的随机游走恢复方法作为一种特殊情况的框架
当角色数量与顶点一样,那么就和普通随机游走的方式一样了
2.4 Inductive Learning
现在我们证明role2vec本质上是归纳的
即,可以用于导出不可见节点的嵌入
更重要的是,它可以用于更一般的基于图的迁移学习问题
注意,基于图的迁移学习比归纳学习更一般
因为它假设嵌入在一个图上学习,然后转移到另一个感兴趣的图上,其中新图中的节点可能完全不同。
给定一个图G,我们学习了基于 N v × K N_v \times K Nv×K属性/特征矩阵 X X X将节点映射到角色 W W W的函数 Φ \Phi Φ,该属性/特征矩阵 X X X包含结构图特征和任何自/内在属性(如果可用)
然后学习每个角色的嵌入,得到一个 M × D M \times D M×D嵌入矩阵
这些嵌入推广到新的节点和图如下:
给定一个新的未见过的节点 v N v + 1 v_{N_v+1} vNv+1,首先计算包含相同结构特征的k维属性向量 x N v + 1 x_{N_v+1} xNv+1
接下来,我们使用 Φ ( x N v + 1 ) \Phi(x_{N_v + 1}) Φ(xNv+1)获得 v N v + 1 v_{N_v+1} vNv+1的角色,然后获得该角色的嵌入 α k \alpha_k αk
同样的方法用于将学习到的嵌入转移到一个新的任意图 G ′ G' G′
我们的方法的一个关键优势是,推断需要 O ( K ) O(K) O(K)时间来获得以前不可见的节点的嵌入。更一般地说,代价只在函数 Φ \Phi Φ的计算中
3 TOY EXAMPLE
本节将使用一个简单的示例直观地展示Role2Vec框架的灵活性和通用性

图1显示了这个具体实例中涉及的关键步骤的概述,并简要总结如下:
S1. Compute and/or Select Features/Attributes:
给定一个(非)有向图G,第一步是使用图G计算结构特征/属性。(例如graphlets[25])
在图1所示的玩具示例中,我们计算每个节点参与的三角形和2颗星的数量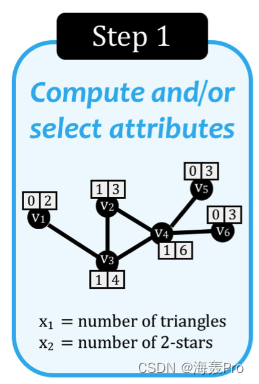
第一步就是求出每个节点的结构/特征向量
此外,Role2Vec可以自然地利用用户输入的任何属性,尽管这些不是必需的
因为Role2Vec也只使用图G计算一组初始的结构特征
S2. Transform Attributes
接下来,我们转换每个 N v N_v Nv维属性向量(对应于 X X X的列)
为了清晰起见
- x ‾ j \overline x_j xj表示 x j x_j xj的第 j j j列
- x i x_i xi表示 X X X的第 i i i行
我们的目标是将每个单独的属性向量 x j x_j xj的值映射到一个(更小的)值集(通过量化或离散化算法)
在图1中,每个属性 x ‾ j \overline x_j xj使用logarithmic binning进行变换
为了方便起见,每个初始的 x ‾ j \overline x_j xj都被转换后的属性所替换

这一步就是对每一个节点的特征向量进行一个处理(便于之后的运算)
S3. Derive Roles from Attributes & Assign
现在,角色集派生为 W = Φ ( x 1 ) ∪ Φ ( x 2 ) ∪ . . . . ∪ Φ ( x N v ) , ∣ W ∣ ≤ N v W = \Phi(x_1) \cup \Phi(x_2) \cup .... \cup \Phi(x_{N_v}),|W| \leq N_v W=Φ(x1)∪Φ(x2)∪....∪Φ(xNv),∣W∣≤Nv以及 Φ : x → w \Phi : x \rightarrow w Φ:x→w

简单的说,就是使用函数 Φ \Phi Φ把节点映射为其对应的角色 w w w
S4: Attributed Random Walks
接下来,我们使用节点角色(与传统使用的唯一节点标识符相反)生成带有属性的(基于特性的)随机游走。
属性随机漫步表示节点角色序列(如图1中的玩具示例所示),然后用于学习嵌入

对转化后的角色集合进行随机游走
原来这就是作者说的属性随机游走
S5: Compute Embeddings
最后,给定带属性的遍历,我们可以使用SkipGram或任何其他基于遍历的方法派生嵌入

得到嵌入
从总体框架的角度来看
- 图1中的步骤1-3对应于通过函数 Φ \Phi Φ将节点映射到角色的第一个主要组件
- 而步骤4-5生成表示节点角色序列的带属性随机漫步,并使用它们学习嵌入
4 THEORETICAL ANALYSIS
理论分析略(看得头疼)
5 EXPERIMENTS
数据集
- brain network (bn)
- collaboration networks (ca)
- ecology networks (eco)
- interaction networks (ia)
- web graphs (web)
- social networks (soc)
- Facebook friendship graphs (fb)
基线方法
- node2vec [9]
- DeepWalk [8]
- struc2vec [12]
- GraphSage [45]
- LINE[20]
- Spectral embedding [5]
实验对比
使用 ( α i + α j ) / 2 (\alpha_i + \alpha_j) /2 (αi+αj)/2的各种链接预测方法的AUC分数

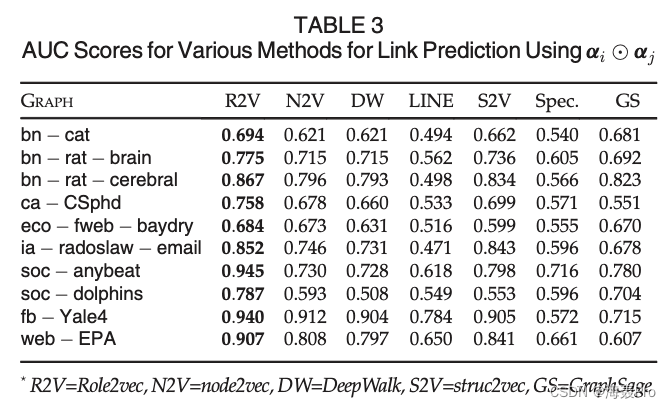
使用 α i ⊙ α j \alpha_i \odot \alpha_j αi⊙αj的各种链接预测方法的AUC分数
后面略(各实验的对比 时间紧 就不仔细看了)
6 RELATED WORK
略
7 CONCLUSION
为了学习基于角色的嵌入,我们提出了属性随机游走的概念
使用这个概念,我们提出了Role2Vec框架,通过学习函数捕捉节点的行为角色
我们的方法不是学习每个节点的单个嵌入,而是基于将特征向量映射到角色的函数学习每个角色的嵌入
结果表明,在Role2Vec框架中,当角色数量等于节点数量时,现有的许多方法实际上是一种特殊情况
最后,我们证明了该框架在预测任务中的有效性,在各种各样的图上,它被证明实现了17.8%的平均增益,同时需要比现有方法少85倍的空间
未来的工作应该系统地研究角色扮演对不同迁移学习任务的有效性及其应用
读后总结
开始的时候 很迷惑
不知道作者提出的 属性随机游走是啥意思
后面看下去 也就是慢慢看懂了
文章针对之前的随机游走办法受限于节点id的缺点
改进了一下:
- 先对节点进行属性特征/结构的表示( x i x_i xi)
- 然后为了便于运算 对 x i x_i xi进行了一些处理
- 然后使用 Φ \Phi Φ将每个节点映射到其对应的角色 w w w
- 然后对这些 w w w构成的图进行随机游走
- 得到最后的嵌入
个人疑问:
- 若两个顶点角色是一样的,那么其对应的嵌入向量还是一样的吗?
第一遍读完 感觉是相同的 之后再读的时候 再思考一下
结语
文章仅作为个人学习笔记记录,记录从0到1的一个过程
希望对您有一点点帮助,如有错误欢迎小伙伴指正

边栏推荐
- Arrangement of language resources of upgraded version
- X书6.97版本shield-unidbg调用方式
- Personal PC installation software
- unity input system 使用记录(实例版)
- C#【高级篇】 C# 多线程
- [practical skills] how to write agile development documents
- The next change direction of database - cloud native database
- [wechat applet] how did the conditional rendering list render work?
- 云原生入门+容器概念介绍
- C#【高级篇】 C# 接口(Interface)
猜你喜欢

Reasons for MySQL master-slave database synchronization failure

Implementation of property management system with ssm+ wechat applet

What are outer chain and inner chain?
![C # [advanced part] C # multithreading](/img/16/2a7c477b4cee32d9ce1e543c9d4c7e.png)
C # [advanced part] C # multithreading

Mathematical solution of Joseph Ring

1148_ Makefile learning_ Targets, variables, and wildcards in makefile

laravel9本地安裝

【笔记】2022.5.23 MySQL

TiDB 6.0:让 TSO 更高效丨TiDB Book Rush

实用调试技巧
随机推荐
云原生入门+容器概念介绍
December2020 - true questions and analysis of C language (Level 2) in the youth level examination of the Electronic Society
Laravel9 installation locale
[ten minutes] manim installation 2022
Ubuntu20.04 PostgreSQL 14 installation configuration record
Selenium environment installation, 8 elements positioning --01
1151_ Makefile learning_ Static matching pattern rules in makefile
Utilisation de foreach en Qt
C#【高级篇】 C# 泛型(Generic)【需进一步补充:泛型接口、泛型事件的实例】
Neo4j---性能优化
X Book 6.97 shield unidbg calling method
What does the hyphen mean for a block in Twig like in {% block body -%}?
[practical skills] how to write agile development documents
Personal PC installation software
Stc89c52/90c516rd/89c516rd ADC0832 ADC driver code
What are outer chain and inner chain?
1148_ Makefile learning_ Targets, variables, and wildcards in makefile
[punch in - Blue Bridge Cup] day 2 --- format output format, ASCII
Are you a "social bull" or a "social terrorist" in the interview?
Redis中的Hash设计和节省内存数据结构设计