当前位置:网站首页>08 spark 集群搭建
08 spark 集群搭建
2022-08-01 16:20:00 【蓝风9】
前言
呵呵 最近有一系列环境搭建的相关需求
记录一下
spark 三个节点 : 192.168.110.150, 192.168.110.151, 192.168.110.152
150 为 master, 151 为 slave01, 152 为 slave02
三台机器都做了 trusted shell
spark 版本是 spark-3.2.1-bin-hadoop2.7
spark 集群搭建
spark 三个节点 : 192.168.110.150, 192.168.110.151, 192.168.110.152
1. 基础环境准备
192.168.110.150, 192.168.110.151, 192.168.110.152 上面安装 jdk, 上传 spark 的安装包
安装包来自于 Downloads | Apache Spark
2. spark 配置调整
复制如下 三个配置文件, 进行调整, 调整了之后 scp 到 slave01, slave02 上面
[email protected]:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7# cp conf/spark-defaults.conf.template conf/spark-defaults.conf
[email protected]:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7# cp conf/spark-env.sh.template conf/spark-env.sh
[email protected]:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7# cp conf/workers.template conf/workers
更新 workers
# A Spark Worker will be started on each of the machines listed below.
slave01
slave02
更新 spark-defaults.conf
spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
更新 spark-env.sh
export JAVA_HOME=/usr/local/ProgramFiles/jdk1.8.0_291
export HADOOP_HOME=/usr/local/ProgramFiles/hadoop-2.10.1
export HADOOP_CONF_DIR=/usr/local/ProgramFiles/hadoop-2.10.1/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/usr/local/ProgramFiles/hadoop-2.10.1/bin/hadoop classpath)
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
3. 启动集群
master 所在的机器执行 start-all.sh
[email protected]:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7# ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave01: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave01.out
slave02: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave02.out
[email protected]:/usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7#
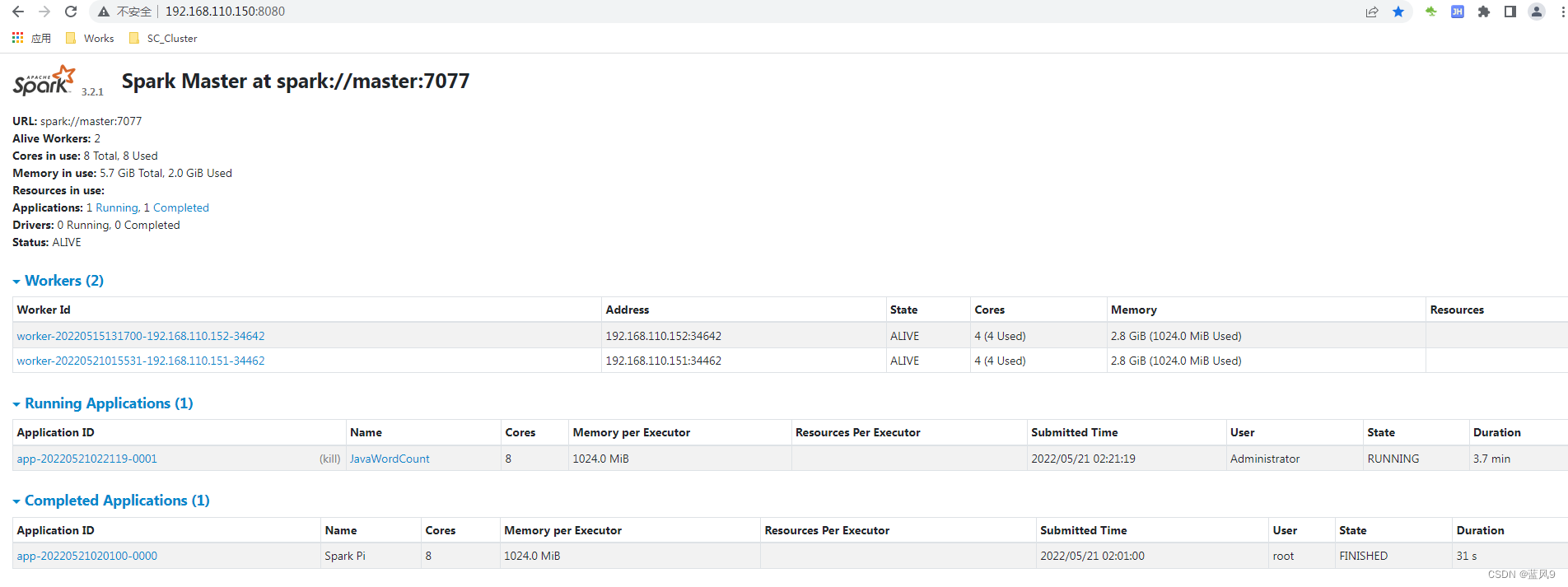
测试集群
使用 spark-submit 提交 SparkPI 迭代 1000 次
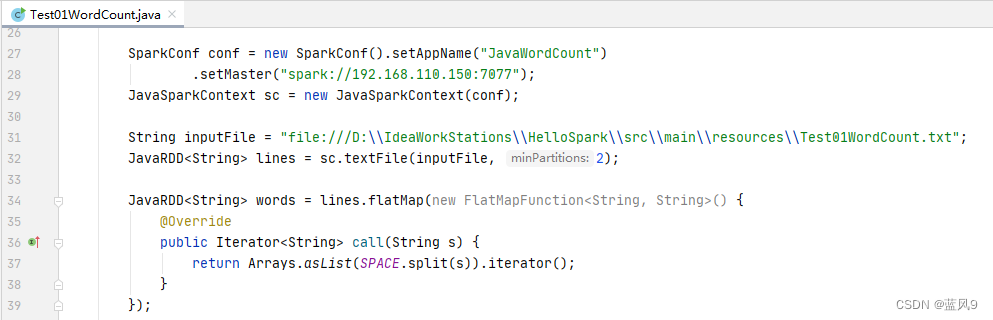
spark-submit --class org.apache.spark.examples.SparkPi /usr/local/ProgramFiles/spark-3.2.1-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.2.1.jar 1000java driver 提交 spark 任务
spark web ui 监控页面
完
边栏推荐
- 14年测试人最近的面试经历,值得借鉴√
- HashCode technology insider interview must ask
- 打破文件锁限制,以存储力量助力企业增长新动力
- LeetCode50天刷题计划(Day 8—— 盛最多水的容器(23.00-1.20)
- ODrive开发 #1 ODrive固件开发指南[通俗易懂]
- 兆骑科创科创赛事平台,创业赛事活动路演,线上直播路演
- flink-sql 可以单独配置某个算子节点的并行度吗?
- "Find nearby shops" | Geohash+MySQL realizes geographic location filtering
- 华盛顿大学、Allen AI 等联合 | RealTime QA: What's the Answer Right Now?(实时 QA:现在的答案是什么?)
- Using Canvas to achieve web page mouse signature effect
猜你喜欢






随机推荐
pynlpir更新license Error: unable to fetch newest license解决方案
美国弗吉尼亚大学、微软 | Active Data Pattern Extraction Attacks on Generative Language Models(对生成语言模型的主动数据模式提取攻击)
Why should model.eval() be added to the pytorch test?
shell 基础之函数编写
27英寸横置大屏+实体按键,全新探险者才是安全而合理的做法
Convert tensor to image in pytorch
面试必问的HashCode技术内幕
如何有效地开发 Jmix 扩展组件
Spark: Cluster Computing with Working Sets
LeetCode50天刷题计划(Day 7—— 字符串转换整数 (atoi) 12.20-15.20)
Flink - SQL can separate a certain parallelism of operator node configuration?
Eslint syntax error is solved
DOM series of touch screen events
Using Canvas to achieve web page mouse signature effect
MLX90640 红外热成像仪测温模块开发笔记(完整版)
工业制造行业的低代码开发平台思维架构图
实习日报-2022-7-30
MySQL查询上的问题
AntDB数据库亮相24届高速展,助力智慧高速创新应用
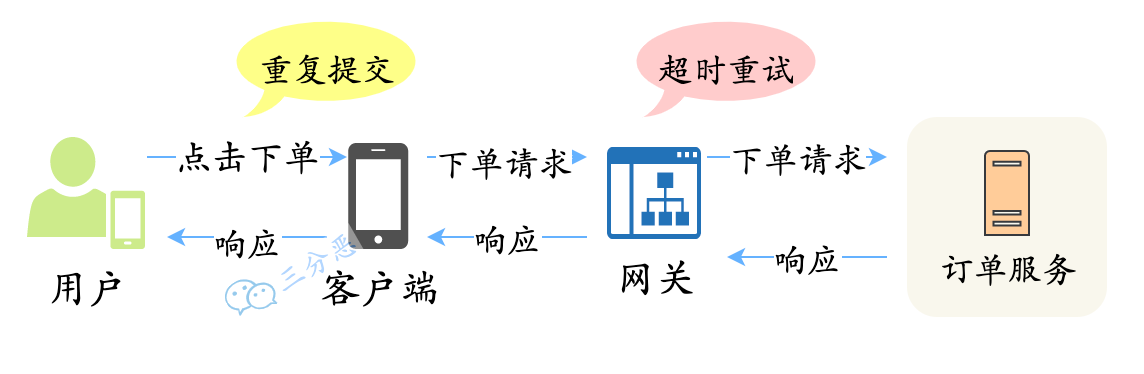
如何防止重复下单?