当前位置:网站首页>Redis advanced knowledge points (can be learned, reviewed and interviewed)
Redis advanced knowledge points (can be learned, reviewed and interviewed)
2022-06-10 01:48:00 【Hua Weiyun】
Preface :
This paper refers to and Redis Related courses , Mainly explained Redis Some questions often asked in the interview , Such as Redis Master-slave ,Redis sentry , Very detailed , Suitable for Xiaobai and the big guy who reviews
If there are any inaccuracies or areas for improvement in the article , Please don't hesitate to give advice .
Thank you first 
Redis Cluster pattern
Redis There are three cluster models , Namely : A master-slave mode 、 Sentinel mode 、Cluster Pattern .Rdis In the beginning, we used master-slave mode to cluster , if master Downtime requires manual configuration slave To master; Later, for High availability Put forward sentinel mode , In this mode There's a sentry watching master and slave, if master Downtime can automatically change slave To master, But it also has a problem , Just can't dynamically expand ; So in 3.x Put forward cluster Cluster pattern .
Redis Master slave architecture
Redis The master-slave mode supports the high concurrency of the client . The master-slave mode is the simplest of the three modes , In master-slave replication , Databases are divided into primary databases (master) And from the database (slave). among , The master node is mainly responsible for writing data , And the master node needs to write data to other slave nodes , The slave node is responsible for reading , All read requests go from the node .
The master-slave mode needs attention :
1. The replicated data flow is unidirectional , It can only be copied from the master node to the slave node .
2. Lord (master) The database can be read and written , When the read-write operation causes data changes, it will automatically synchronize the data to the slave database
3. from (slave) Databases are generally read-only , And receive the data synchronized from the main database
4. One master You can have multiple slave, But one slave There's only one master
5.slave Hang up It doesn't affect anything else slave Reading and master Reading and writing , The data will be transferred from master Sync up
6.master After hanging up , No effect slave The reading of , but redis No more write Services ,master After restart redis take Re provide external write Services
7.master After hanging up , Not in slave Re select one of the nodes master

hypothesis A,B For two Redis Example , If you want to let B As A The slave node , Need to be in B Execute commands on nodes :slaveof A Of IP A The port of (port)

Full amount of synchronization (sync)
Generally used in the first replication scenario ,Redis In the early days, only full replication was supported , It will send all the data of the master node to the slave node at one time , When the amount of data is large , It will cause a lot of overhead to the master-slave node and the network .
The basis of judgment :
Replication Id: abbreviation replid, Is the tag of the dataset ,id Consistent means the same data set . every last master There's only one replid,slave Will inherit master Node replid.
offset: Offset , As recorded in repl_baklog The data in increases gradually .slave When the synchronization is completed, the current synchronization will also be recorded offset. If slave Of offset Less than master Of offset, explain slave The data lag behind master, You need to update .
therefore slave Do data synchronization , You have to go to master Declare your own replication id and offset,master To determine which data needs to be synchronized .
because slave It was also a master, Have their own replid and offset, When you first become slave, And master When establishing a connection , Sent replid and offset It's your own. replid and offset.
master Judge and find slave Sent to replid Inconsistent with your own , It shows that this is a new slave, You know you need to do full synchronization .
master I will take my own replid and offset All sent to this slave,slave Save this information . in the future slave Of replid Just like master It's the same
therefore ,master The basis for judging whether a node is synchronized for the first time , Just look at replid Is it consistent .
The complete process is described as follows :
- slave The node requests incremental synchronization
- master Node judgment replid, Find inconsistencies , Reject incremental synchronization
- master Complete memory data Generate RDB, send out RDB To slave
- slave Clear local data , load master Of RDB
- master take RDB Commands during are recorded in repl_baklog, And continue to log Send the command in to slave
- slave Execute the received command , Keep up with master Synchronization between

The incremental synchronization (psync)
The incremental synchronization : It is used to deal with problems caused by network flash failure in master-slave replication Data loss scenarios , When the slave node is connected to the master node again , If conditions permit , The master node will send the lost data to the slave node . The data of reissue is far less than the total data , It can effectively avoid the high cost of full replication
Just update slave And master Some data with differences
stay Redis 2.8 after Use psync Command instead of sync Command to perform synchronous operations ,psync With full data resynchronization and Partial resynchronization mode .
repl_backlog principle
master How do I know slave What is the difference with your own data ?
This brings us to the problem of full synchronization repl_baklog The file .
This file is a fixed size array , It's just that the array is circular , in other words When the subscript reaches the end of the array , I'll come back from 0 Start reading and writing , In this way, the data in the head of the array will be overwritten .
repl_baklog We will record Redis Processed command logs and offset, Include master Current offset, and slave Already copied to offset:
slave And master Of offset Differences between , Namely salve Data that requires incremental copies 了 .
As data continues to be written ,master Of offset Gradually get bigger ,slave And keep copying , Catch up with master Of offset:
Until the array is filled :
here , If new data is written , Will overwrite the old data in the array . however , As long as the old data is green , The description is that it has been synchronized to slave The data of , It doesn't matter if it's covered . Because only the red part is not synchronized .
however , If slave There is a network jam , Lead to master Of offset Far more than slave Of offset:
If master Continue writing new data , Its offset Will overwrite the old data , Until will slave current offset Also covered :
The red part in the brown box , Is not synchronized yet , But the data that has been overwritten . If at this time slave recovery , Need to be synchronized , But I found myself offset All have no , Unable to complete incremental synchronization . Can only do full synchronization .

Master slave synchronization optimization
Master-slave synchronization can ensure the consistency of master-slave data , It's very important .
It can be optimized from the following aspects Redis The master-slave cluster :
- stay master Middle configuration repl-diskless-sync yes Enable diskless replication , Avoid disk during full synchronization IO.
- Redis Don't use too much memory on a single node , Reduce RDB Resulting in too many disks IO
- To improve properly repl_baklog Size , Find out slave Achieve fault recovery as soon as possible in case of downtime , Avoid full synchronization as much as possible
- Limit one master Upper slave Number of nodes , If it's too much slave, Then the main - from - From the chain structure , Reduce master pressure

The difference between full and incremental
Briefly describe the difference between full synchronization and incremental synchronization ?
- Full amount of synchronization :master Generate complete memory data RDB, send out RDB To slave. Subsequent commands are recorded in repl_baklog, Send one by one to slave.
- The incremental synchronization :slave Submit your own offset To master,master obtain repl_baklog In the from offset After the order to slave
When to perform full synchronization ?
- slave The node is connected for the first time master Node time
- slave Node disconnected for too long ,repl_baklog Medium offset When it has been covered
When to perform incremental synchronization ?
- slave The node is disconnected and restored , And in repl_baklog We can find offset when
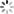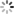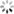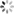

Redis sentry
sentry (sentinal) It's a distributed system , Used to deal with Each server in the master-slave structure is monitored , When there is a failure, the voting mechanism is used to select a new one master And will all slave Connect to the new master.
The role of the sentry is as follows :
- monitor :Sentinel Will keep checking your master and slave Whether it works as expected
- Automatic fault recovery : If master fault ,Sentinel It will slave Upgrade to master. When the fault instance recovers, it will be replaced with a new one master Mainly
- notice :Sentinel act as Redis The service discovery source of the client , When a cluster fails over , Will push the latest information to Redis The client of


Redis The principle of cluster monitoring
Sentinel Monitor service status based on heartbeat mechanism , every other 1 Seconds to each instance of the cluster ping command :
• Subjective offline : If a sentinel The node found that an instance did not respond within the specified time , It is considered that the example Subjective offline .
• Objective offline : If it exceeds the specified quantity (quorum) Of sentinel It is considered that the example is subjective , Then the instance Objective offline .quorum The value should preferably exceed Sentinel Half the number of instances .

Cluster failover
Once found master fault ,sentinel Need to be in salve Choose one of them as the new master, The selection basis is as follows :
- First of all, I will judge slave Node and master Node disconnection time , If the specified value is exceeded (down-after-milliseconds * 10) Will exclude the slave node
- And then determine slave Node slave-priority value , The smaller, the higher the priority , If it is 0 Never participate in the election
- If slave-prority equally , Then judge slave Node offset value , The bigger the data, the newer , The higher the priority
- The last is judgment slave The operation of the node id size , The smaller, the higher the priority .
Elected a new master after , How to achieve switching ?
The process is as follows :
- sentinel Give the alternative slave1 The node sends slaveof no one command , Let the node be master
- sentinel To all the others slave send out slaveof 192.168.150.101 7002 command , Let these slave Become new master The slave node , Start with a new master Up-sync data .
- Last ,sentinel Mark the failed node as slave, When the failed node recovers, it will automatically become a new node master Of slave node


Sentry summary
Sentinel What are the three functions of ?
- monitor
- Fail over
- notice
Sentinel How to judge a redis Whether the instance is healthy ?
- every other 1 Seconds to send ping command , If there is no opposition over a certain period of time, it is considered as subjective offline
- If most sentinel They all think that the instance is subjective , It is judged that the service is offline
What are the failover steps ?
- First choose one slave As new master, perform slaveof no one( Never be a slave )
- Then let all nodes execute slaveof new master
- Modify the configuration of the failed node , add to slaveof new master

This article ends here , If there is anything unreasonable or needs to be improved, ask the boss to correct it
Thank you again for your company

边栏推荐
- NACK of webrtc's audio weak network countermeasure
- TRichView and ScaleRichView 设置默认中文
- 比你想象中更强大的 reduce 以及对敲码的思考
- The IPO meeting of xinghuan science and Technology Innovation Board: the gross profit margin remains at a high level, with Tencent and other major shareholders
- D mapping instructions in memory and executing
- What are the reasons for frequent channel drops in easycvr cascaded video convergence platform?
- 为什么芯片设计也需要「匠人精神」?
- Rhcsa day 7
- [apprendre la programmation FPGA à partir de zéro - 16]: chapitre de démarrage rapide - Étapes 2 - 4 - Verilog HDL Language Description Language Basic Syntax (both Software programmers and Hardware En
- 【程序人生】“阶段总结”-不知所措
猜你喜欢
![[Multisim Simulation] differential proportional amplifier circuit](/img/29/951bee086128c1a0a4ec33ddc82bee.png)
[Multisim Simulation] differential proportional amplifier circuit

Locust:微服务性能测试利器

51 single chip microcomputer learning record (VI) IIC, ADC part

Hoo Hufu Research Institute | houlang in the coin circle - gamefi like baokemeng: evoverses

基于OpenVINO部署的工业缺陷检测产业实践范例实战

From these papers in 2022, we can see the trend of recommended system sequence modeling

【ACL 2022】Hallucinated but Factual! Inspecting the Factuality of Hallucinations

Node red series (26): use the dashboard node to develop common table search layouts

剑指 Offer 10- II. 青蛙跳台阶问题

Leetcode 700: search in binary search tree
随机推荐
[email protected] Project training
Domain Adaptation and Graph Neural Networks
投资新手买收益率多少的理财产品合适?
NACK of webrtc's audio weak network countermeasure
[leetcode] connected to rainwater
Node red series (26): use the dashboard node to develop common table search layouts
Nodejs reported an internal error typeerror: cannot read property 'destroy' of undefined
LeetCode 98: 验证二叉搜索树
【LeetCode】64. Minimum path sum
【LeetCode】128. 最长连续序列
实验三 字符类型及其操作(新)
Why does chip design also need "Craftsmanship"?
The transfer of production lines to Vietnam may not be a good choice. Samsung mobile phones have been affected and plan to return to South Korea
iNFTnews | 元宇宙进行时:那些跑步入场的互联网大厂在如何谋篇布局?
【LeetCode】114. Expand binary tree into linked list
iNFTnews | NFT在Web3经济里的未来
What is the difference between encryptors and database encryption products?
[games101] Assignment 1 -- MVP (model, view, projection) transformation
TRichView and ScaleRichView 设置默认中文
物联网工程设计与实施