当前位置:网站首页>两招提升硬盘存储数据的写入效率
两招提升硬盘存储数据的写入效率
2022-06-23 03:41:00 【SOJSON在线】
如今存储数据的方式有很多,而硬盘因为价格和数据保护方面的优势,是大部分用户的首选。但是,硬盘和内存相比在 IO 读写上慢了好几个数量级,那为什么会更偏好硬盘呢?
首先需要提到的是,操作磁盘之所以慢主要是因为对磁盘的读写耗时。读写主要有三部分耗时:寻道时间+旋转时间+传输时间,其中寻道时间是最久的。因为寻道需要移动磁头到对应的磁道上,通过马达驱动磁臂移动,是一种机械运动因此耗时较长。同时我们对磁盘的操作通常都是随机读写,也就需要频繁移动磁头到对应的磁道,这就让耗时延长了,显得性能比较低。
这样看来如果要让磁盘读写速度变快,只要不使用随机读写,或者减少随机的次数,就可以有效提升磁盘读写速度了。那具体要如何操作呢?
顺序读写
先来聊聊第一个方法,如何使用顺序读写,而不是随机读写?上面提到寻道时间是耗时最久的,所以最直观的思路就是省去这部分时间,而顺序 IO 正好可以满足需求。
追加写就是一种典型的顺序 IO,使用这个思路优化的典型的产品就是消息队列。以热门的 Kafka 为例,Kafka 为了实现高性能 IO,用了很多优化的方法,其中就使用了顺序写这种优化方法。

Kafka 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。对于每个分区,它把从 Producer 收到的消息,顺序地写入对应的 log 文件中,一个文件写满后,才开启一个新的文件。消费的时候,也是从某个全局的位置开始,也就是某一个 log 文件中的某个位置开始,按顺序地读出消息。
减少随机次数
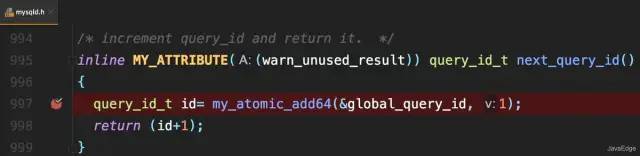
看完了顺序方式,我们再来看看减少随机写次数的方法。在很多场景中,为了方便我们后续对数据的读取和操作,我们要求写入硬盘的数据是有序的。比如在 MySQL 中,索引在 InnoDB 引擎中是以 B+ 树方式来组织的,而 MySQL 主键是聚簇索引(一种索引类型,数据与索引数据放在一起),既然数据和索引数据放在一起,那么在数据插入或者更新的时候,我们需要找到要插入的位置,再把数据写到特定的位置上,这就产生了随机的 IO。所以,如果我们每次插入、更新数据都把数据写入至 .ibd 文件的话,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高,数据库的性能和效率都会大打折扣。
为了解决写入性能问题,InnoDB 引入了 WAL 机制,更确切的说,就是 redo log。下面我再简单介绍下 Redo Log。
InnoDB redo log 是一个顺序写入的、大小固定的环形日志。主要作用有两个:
- 提高 InnoDB 存储引擎写入数据的效率
- 保证 crash-safe 能力
在这里我们只关心它是如何提高写入数据的效率的。下图是 redo log 的示意图。

从图中可以看出,red olog 的写入是顺序写入的,不需要找到某一个具体的索引位置,而是简单地从 write-pos 指针位置追加。
其次当一个写事务或者更新事务执行时,InnoDB 首先取出对应的 Page,然后进行修改。当事务提交时,将位于内存中的 redo log buffer 强制刷新至硬盘中,如果不考虑 binlog 的话,我们可以认为事务执行可以返回成功了,写入 DB 的操作由另外的线程异步进行。
再然后,可由 InnoDB 的 Master Thread 定时地将缓冲池中的脏页,也就是上面儿我们修改的页,刷新至磁盘,此时被修改数据真正的写入至 . ibd 文件。
总结
文章来自又拍云投稿
边栏推荐
- January 17, 2022: word rule II. Give you a pattern and a character
- How to implement collection sorting?
- 自媒体时代的贤内助——AI 视频云
- WordPress modifying fixed links and pseudo statics
- [tcapulusdb knowledge base] [list table] sample code for inserting data into the specified position in the list
- centos7 安装 MySQL 及配置 innodb_ruby
- redis 精讲系列介绍八 - 淘汰策略
- Talk about memory model and memory order
- [tcapulusdb knowledge base] [list table] example code of batch deleting data at specified location in the list
- How to realize data transaction
猜你喜欢
What if the self incrementing IDs of online MySQL are exhausted?

Google Earth engine (GEE) - long time series monthly VCI data extraction, analysis and area calculation (Mexico as an example)

mysql存储引擎之Myisam和Innodb的区别

【owt】owt-client-native-p2p-e2e-test vs2017构建2 :测试单元构建及运行
[OWT] OWT client native P2P E2E test vs2017 build 2: test unit construction and operation
线上MySQL的自增id用尽怎么办?
![[greed] leetcode991 Broken Calculator](/img/6e/ce552b55899c6e8d3c37f524f99f82.png)
[greed] leetcode991 Broken Calculator

redis 精讲系列介绍八 - 淘汰策略

【二分】leetcode1011. Capacity To Ship Packages Within D Days

mysql 数据恢复 (.ibdata1, bin log)
随机推荐
bubble sort
Official announcement! The Hong Kong Zhuhai Macao Bridge is finally here!
Half search method
Brief introduction to arm architecture
Goframe framework: quick creation of static file download web service
pyspark,有偿询问数据清洗和上传到数据库的问题
JS remove first character of string
The power of code refactoring: how to measure the success of refactoring
The first batch of job hunting after 00: don't misread their "different"
What about the high cost of storage system? The original computer room can save so much money!
Goframe framework: log configuration management
How to make distribution box label
【LeetCode】23. Merge K ascending linked lists
centos7 安装 MySQL 及配置 innodb_ruby
Tcapulusdb Jun · industry news collection (V)
[advanced Android] kotlin delegate attribute
Easygbs service is killed because the user redis is infected with the mining virus process. How to solve and prevent it?
What is the difference between comparator and comparable?
New configuration of Alipay
[binary tree] 993 Cousins in Binary Tree