当前位置:网站首页>Splunk Bucket 背后的秘密
Splunk Bucket 背后的秘密
2022-06-11 12:01:00 【shenghuiping2001】
最近刚好一个运维case 来看splunk 移除peer node 数据不会丢失:
1: 由于性能问题,要移除index node, 通常我们说这是一个peer:
可以参考我的blog:Splunk 移除index 节点 + 注意点_shenghuiping2001的博客-CSDN博客
先在CM. server 上执行remove 的命令后:
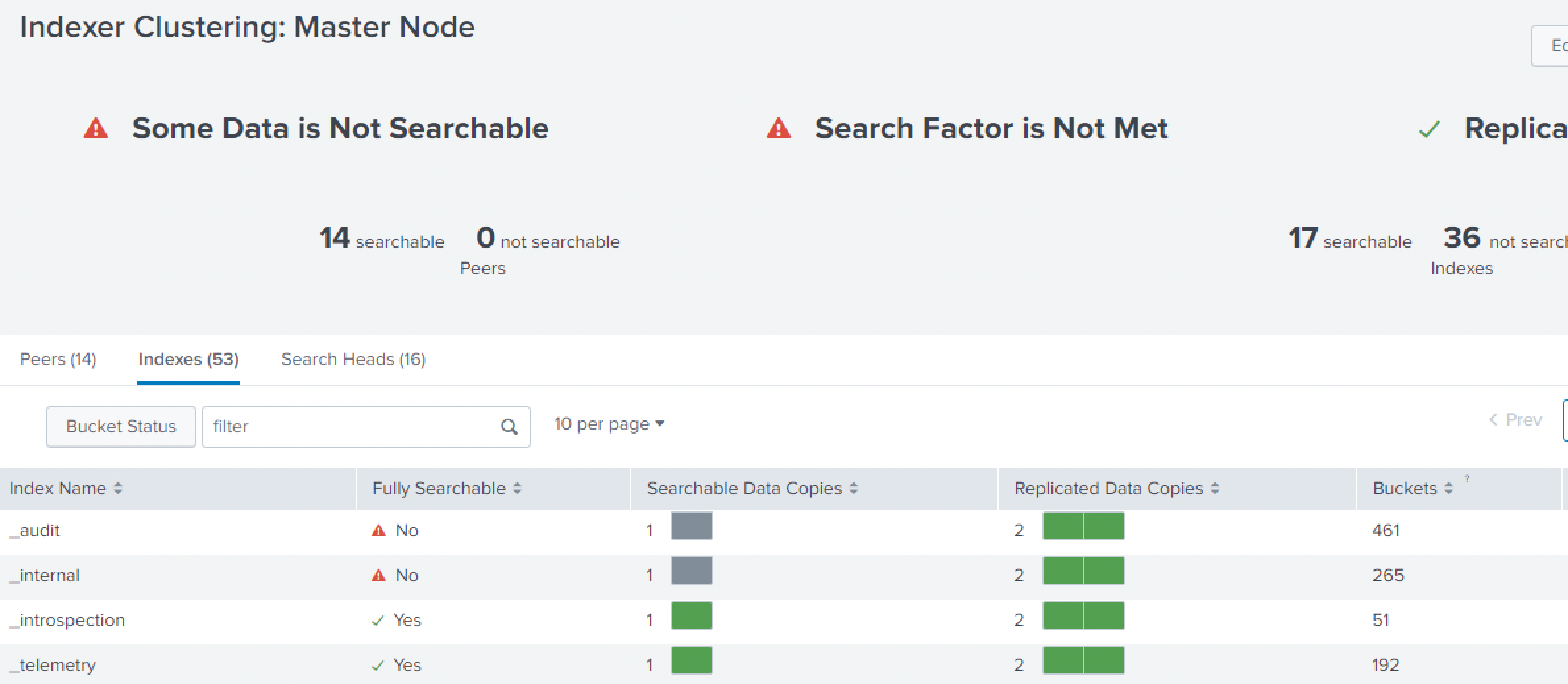
发现node peer : 15 -> 14, 少了一个,但是searchable 的变少了:

2: 但是不用担心:看上面的replicated Data copies: 2 个,还是绿色的:
检查一下上面bucket status 的: 点一下 Butcket Status:

可以看到 Fixup Tasks : pending 的数量在不断减少,稍微等一会,再看上面的searchable 的:
3: 下面再看一下process 的进程:
可以看到pendingd 的数量在不断减少,而且新的bucket 是在不同的两个新的peer 上面的copy.

4: 所以,当有两个node 同时移除的时候,而且这两个noe 都是含有同一个bucket 的话那这个bucket 就没有地方copy.
5: 最后完全OK:

6: 关于上图的: indexer with exces Buckets: (下图可以解释)
RF: 2 | ||
peer3 | ||
peer1 | peer2 |
|
bkt1 | bkt1(excess) |
|
| bkt2 | bkt2(excess) |
bkt2 | bkt1 | bkt1(excess) |
|
|
|
Case1:
Peer1: bkt1 / bkt2
Peer2: bkt2
Peer3: bkt1
Case2: when peer2 offline / maintenance:
Peer1: bkt1 / bkt2
Peer2: ---
Peer3: bkt1 / bkt2 (copy from peer2).
Case3: when peer2 recovery:
Peer1: bkt1 / bkt2
Peer2: bkt2
Peer3: bkt1 / bkt2
从上面的case 3 的时候,bkt2 就显示excess. 如果出现如下case4 的时候:
Case4: when peer3 offline / maintenance:
Peer1: bkt1 / bkt2
Peer2: bkt2 / ( bkt1 / bkt2) excess
Peer3: ---
上面的解释说明excess buket 产生的过程。
有具体案例可以私信我。
边栏推荐
- iframe 传值
- Fast build elk7.3
- 【LeetCode】1049. Weight of the last stone II (wrong question 2)
- typescript 编译选项和配置文件
- Merge two ordered arrays (C language)
- 浙大联合微软亚研院发布视频识别新方法,可对视频逐帧识别且无需,数据标记,或可用于手语翻译等
- Use compiler option '--downleveliteration' to allow iteration of iterations
- How to understand CPU load
- Études à la fin de l'enseignement 03
- JS 加法乘法错误解决 number-precision
猜你喜欢

CVPR 2022 | 文本引导的实体级别图像操作ManiTrans

How to solve the problem that high-precision positioning technologies such as ultra wideband UWB, Bluetooth AOA and RTK cannot be widely used due to their high cost? Adopt the idea of integrated deplo

Use of RadioButton in QT
ELK - Hearthbeat实现服务监控

Zhejiang University and Microsoft Asia Research Institute released a new method of video recognition, which can recognize video frame by frame without data marking, or can be used for sign language tr

Use compiler option ‘--downlevelIteration‘ to allow iterating of iterators 报错解决

Intl.numberformat set number format

How does Sister Feng change to ice?

iframe 传值

C# 设置或验证 PDF中的文本域格式
随机推荐
Dominating set, independent set, covering set
01_ Description object_ Class diagram
The wonderful use of XOR (C language)
Eulato
Memory mapping image of the grayloc module in the surfacefinder process
Node connects to MySQL database and writes fuzzy query interface
Zero after factorial (C language)
P2580 "so he started the wrong roll call"
C# 设置或验证 PDF中的文本域格式
[第二章 基因和染色体的关系]生物知识概括–高一生物
arguments.callee 实现函数递归调用
ObjectInputStream读取文件对象ObjectOutputStream写入文件对象
Linux忘记MySQL密码后修改密码
解决swagger文档接口404的问题
JVM class loading process
C# 在PDF文档中应用多种不同字体
Learning in Bi design 03
Use compiler option ‘--downlevelIteration‘ to allow iterating of iterators 报错解决
2022 | framework for Android interview -- Analysis of the core principles of binder, handler, WMS and AMS!
Zhejiang University and Microsoft Asia Research Institute released a new method of video recognition, which can recognize video frame by frame without data marking, or can be used for sign language tr