当前位置:网站首页>菜鸟看源码之HashTable
菜鸟看源码之HashTable
2022-07-26 10:49:00 【leilifengxingmw】
HashTable :key,value都不能为null;线程安全。(如果不需要线程安全,应该使用HashMap,如果需要线程安全,可以使用ConcurrentHashMap,HashTable估计要退出历史舞台了)
作为key的对象必须实现hashCode方法和equals方法。
默认的负载因子是0.75,太小会导致频繁分配空间,太大会增加查找的时间。
如果知道要一次性放入HashTable很多元素,可以指定一个比较大的初始化容量,这样可以避免多次rehashing来增加表的容量。
HashTable继承结构

HashTable成员变量
//哈希表的数据
private transient Entry<?,?>[] table;
//哈希中数据的数量
private transient int count;
// 阈值(capacity * loadFactor),当表的size超过这个阈值,就会rehash来增加表的容量
private int threshold;
//负载因子
private float loadFactor;
//修改次数
private transient int modCount = 0;
//序列化id
private static final long serialVersionUID = 1421746759512286392L;
HashTable节点的数据结构,单链表
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next;
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
//省略其他的方法
...
}
HashTable的构造函数
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
//初始化table
table = new Entry<?,?>[initialCapacity];
//给threshold赋值
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
总之初始化函数就是初始化table对象,并给threshold赋值。
HashTable的成员方法,为什么说是线程安全呢,方法前面都加了synchronized。
/** * key,value都不能为null。方法返回null或者key位置上的前一个value。 */
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
//key不能为null
int hash = key.hashCode();
//计算出存储的位置
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
//遍历链表
for(; entry != null ; entry = entry.next) {
//存在一样的元素,更新元素返回oldValue
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
//添加新元素
addEntry(hash, key, value, index);
return null;
}
- 首先看要插入的位置index上存在元素entry,如果存在,就向后遍历entry。
- 如果满足(entry.hash == hash) && entry.key.equals(key),就用新值替换旧值,并返回旧值。
- 如果位置index上不存在存在元素entry,就调用addEntry方法把元素插入,返回null;
addEntry(hash, key, value, index)方法
private void addEntry(int hash, K key, V value, int index) {
//结构性修改
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// 如果元素数量超过了阈值,就rehash,增加表的容量
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// 新建一个Entry对象,插入index位置,注意tab[index]为null
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
- 修改次数加1。
- 如果元素数量超过了阈值,就rehash,增加表的容量,并重新计算index。
- 新建一个Entry对象,插入index位置,元素个数加1。
HashTable的putAll(Map<? extends K, ? extends V> t)方法,内部就是遍历调用HashTable的put(K key, V value)方法。
public synchronized void putAll(Map<? extends K, ? extends V> t) {
for (Map.Entry<? extends K, ? extends V> e : t.entrySet())
put(e.getKey(), e.getValue());
}
HashTable的get(Object key)方法
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
- 根据key值计算hash值,然后找到存储位置index,如果index位置上存在元素entry,就向后遍历,如果满足元素e
(e.hash == hash) && e.key.equals(key)),就返回e的value。 - 否则返回null.
HashTable的containsValue(Object value)方法
public boolean containsValue(Object value) {
return contains(value);
}
HashMap的contains(Object value)方法
public synchronized boolean contains(Object value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<?,?> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
- 从后向前遍历table,如果i位置上有元素entry,就向后遍历entry,如果存在元素e满足
e.value.equals(value),就返回true。 - 找不到就返回false。
HashTable的containsKey(Object key)方法
public synchronized boolean containsKey(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
- 根据key的哈希值,找到对应的index,如果index位置上存在元素e,就向后遍历e。如果存在一个元素满足
(e.hash == hash) && e.key.equals(key)就返回true。 - 不存在就返回false。
HashTable的clear函数,没啥可说的,增加修改次数,吧每个位置上的元素置为null,元素数量设为0。
public synchronized void clear() {
Entry<?,?> tab[] = table;
modCount++;
for (int index = tab.length; --index >= 0; )
tab[index] = null;
count = 0;
}
HashTable的rehash()方法
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
//新的容量是table原来容量的两倍+1
int newCapacity = (oldCapacity << 1) + 1;
//确保最大长度小于等于Integer.MAX_VALUE - 8
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
//修改次数加1
modCount++;
//重新给threshold赋值
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
//让table指向newMap
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
- 计算新的容量newCapacity ,原来table的长度*2+1。如果新容量最大值不能超过MAX_ARRAY_SIZE(Integer.MAX_VALUE - 8)
- 新建一个长度为newCapacity 的newMap,增加修改次数,重新给threshold赋值,让table指向newMap。
- 从后向前遍历old table,如果i位置上存在元素,找到i位置上的最后一个元素,重新计算index,然后就让i位置上的最后一个元素指向newMap[index](newMap[index]这时候为null),然后给newMap[index]赋值为e。
举个例子,如下图所示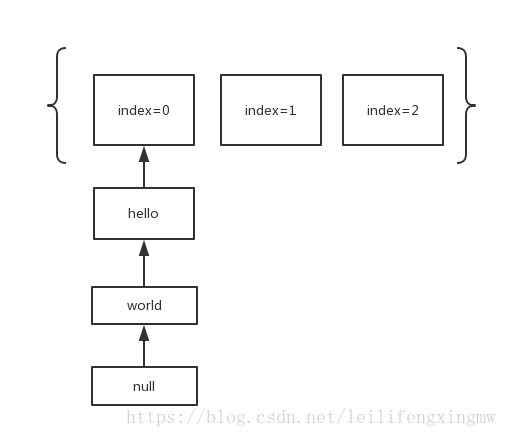
在上面的例子中,只有index=0 的位置上有数据
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
遍历的结果是
当i=1;i-->0的时候,index=0的位置上有元素
进入第二层for循环
(Entry<K,V> old = oldMap[0] = {hello->world->null};old!=null;){
...
}
1. 第1次遍历,old = hello->world->null
e=hello->world->null;
old=world->null;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;//假设新计算出来的index这个值为5,并且这个index上没有元素
e.next = (Entry<K,V>)newMap[5];//e=hello->null;
newMap[5] = e;//newMap[5] = hello->null;
2. 第2次遍历,old=world->null
e=world->null;
old=null;
int index=5;
e.next = (Entry<K,V>)newMap[5];//e=world->hello->null;
newMap[5] = e;//newMap[5]=world->hello->null;
3. 第3次循环 old=null; 结束
遍历完以后的结果如下所示,会把对应位置上的链表翻转
边栏推荐
- MFC中0x003b66c3 处有未经处理的异常: 0xC000041D: 用户回调期间遇到未经处理的异常
- MFC图片控件
- Anaconda is used on vscode (the environment has been configured)
- flutter dart生成N个区间范围内不重复随机数List
- RT thread learning notes (V) -- edit, download and debug programs
- WinPcap packet capturing function pcap_ Loop (), stop the problem
- [machine learning notes] [face recognition] deeplearning ai course4 4th week programming
- 27.移除元素
- C language pengge 20210812c language function
- Codepoint 58880 not found in font, aborting. flutter build apk时报错
猜你喜欢

2021-08-12 function recursion_ Learn C language with brother Peng

nmap弱点扫描结果可视化转换

Flutter编译报错 version of NDK matched the requested version 21.0.6113669. Versions available locally: 2
Bash shell学习笔记(七)

RT thread learning notes (III) -- building a compilation environment with scons

【小程序】onReachBottom 事件为什么不能触发 ?(一秒搞定)

Why do I need automated testing? Software testers take you to evaluate different software testing tools

用两个栈实现队列
2021-08-12函数递归_和鹏哥学习C语言

The problem of formatting IAR sprintf floating point to 0.0 in UCOS assembly
随机推荐
Sword finger offer (twenty): stack containing min function
Disable usbjatg in Altium Designer
2021-08-12函数递归_和鹏哥学习C语言
Stringing of macro parameters and connection of macro parameters in C language
[leetcode daily question 2021/2/14]765. Lovers hold hands
RT thread learning notes (VIII) -- start the elmfat file system based on SPI flash (Part 2)
解决:无法加载文件 C:\Users\user\AppData\Roaming\npm\npx.ps1,因为在此系统上禁止运行脚本 。
对面向抽象编程的理解
10 let operator= return a reference to *this
企鹅龙(DRBL)无盘启动+再生龙(clonezilla)网络备份与还原系统
1748.唯一元素的和
[paper after dinner] deep mining external perfect data for chestx ray disease screening
解决org.apache.commons.codec.binary.Base64爆红问题
Sword finger offer (49): convert a string to an integer
2021-08-12 function recursion_ Learn C language with brother Peng
Minesweeping Pro version 2021-08-19
SQL Server 之Sql语句创建数据库
RT-Thread 学习笔记(三)---用SCons 构建编译环境
Why do I need automated testing? Software testers take you to evaluate different software testing tools
@JsonFormat和@DateTimeFormat的区别和使用