当前位置:网站首页>Implementation principle and application practice of Flink CDC mongodb connector
Implementation principle and application practice of Flink CDC mongodb connector
2022-06-21 20:20:00 【Apache Flink】
This paper is compiled from XTransfer Senior Java Development Engineer 、Flink CDC Maintainer Sunjiabao is Flink CDC Meetup Speech . The main contents include :
- MongoDB Change Stream Technical introduction
- MongoDB CDC Connector Business practice
- MongoDB CDC Connector Production tuning
- MongoDB CDC Connector Parallelization Snapshot improvement
- Follow up planning
Click to view live playback & speech PDF
One 、MongoDB Change Stream Technical introduction

MongoDB Is a document oriented non relational database , Support semi-structured data storage ; It is also a distributed database , Two cluster deployment modes, replica set and shard set, are provided , High availability and horizontal scalability , It is suitable for large-scale data storage . in addition , MongoDB 4.0 Version also provides support for multi document transactions , It is more friendly to some complex business scenarios .

MongoDB A weakly structured storage mode is used , Support flexible data structure and rich data types , fit Json file 、 label 、 snapshot 、 Location 、 Business scenarios such as content storage . Its natural distributed architecture provides out of the box sharding mechanism and automation rebalance Ability , Suitable for large-scale data storage . in addition , MongoDB It also provides the function of distributed grid file storage , namely GridFS, Suitable for pictures 、 Audio 、 Storage of large files such as video .

MongoDB Two cluster mode deployment modes, replica set and shard set, are provided .
Replica set : Highly available deployment mode , The secondary node replicates data by copying the operation logs of the primary node . When the primary node fails , The secondary node and the quorum node will re initiate voting to select a new primary node , Achieve failover . in addition , The secondary node can also share the query request , Reduce the query pressure of main nodes .
Fragment set : Horizontal expansion deployment mode , Spread the data evenly among different Shard On , Every Shard Can be deployed as a replica set ,Shard The primary node in the hosts read / write requests , The secondary node will copy the operation logs of the primary node , The data can be divided into multiple partitions according to the specified partition index and partition strategy 16MB A block of data , And give these data blocks to different Shard For storage .Config Servers We will record Shard Correspondence with data block .

MongoDB Of Oplog And MySQL Of Binlog similar , Recorded data in MongoDB All operation logs in .Oplog Is a collection with capacity , If it exceeds the preset capacity range , The previous information will be discarded .

And MySQL Of Binlog Different , Oplog Before the change is not recorded / Complete information after . Traverse Oplog It does capture MongoDB Data change of , But I want to convert it into Flink Supported by Changelog There are still some limitations .
First , subscribe Oplog Is difficult . Each replica assembly maintains its own Oplog, For fragmented clusters , Every Shard It may be a separate replica set , Need to traverse each Shard Of Oplog And sort according to the operation time . in addition , Oplog The complete status before and after the change document is not included , Therefore, it cannot be converted into Flink The standard Changelog , Nor can it be converted into Upsert Type of Changelog . This is what we are trying to achieve MongoDB CDC Connector There is no direct subscription Oplog The main reason for the scheme .

In the end, we chose to use MongoDB Change Streams Plan to achieve MongoDB CDC Connector.
Change Streams yes MongoDB 3.6 New features provided by version , It provides a simpler change data capture interface , Direct traversal is shielded Oplog Complexity .Change Streams It also provides the function of extracting the complete status of the changed document , It can be easily converted into Flink Upsert Type of Changelog. It also provides relatively complete fault recovery capability , Each change record data will contain a resume token To record the location of the current change flow . After the failure , Can pass resume token Recover from the current consumption point .
in addition , Change Streams Support the filtering and customization of change events . For example, regular filters for database and collection names can be pushed down to MongoDB To complete , It can significantly reduce network overhead . It also provides change subscriptions to the collection library and the entire cluster level , It can support corresponding permission control .

Use MongoDB Change Streams Feature implementation CDC Connector As shown in the figure above . First, through Change Streams subscribe MongoDB Changes . Such as the insert、update、delete、replace Four types of changes , First convert it into Flink Supported by upsert Changelog, You can define a dynamic table on it , Use Flink SQL To deal with .
at present MongoDB CDC Connector Support Exactly-Once semantics , Support full plus incremental subscriptions , Support from checkpoints 、 Save point recovery , Support Snapshot Data filtering , Support database Database、Collection And so on , It also supports regular filtering of library collections .
Two 、MongoDB CDC Connector Business practice

XTransfer Founded on 2017 year , Focus on B2B Cross border payment business , Provide foreign trade collection and risk control services for small, medium and micro enterprises engaged in cross-border e-commerce export . Cross-border B The business link involved in this kind of business settlement scenario is very long , From inquiry to final transaction , Logistics clauses are involved in the process 、 Payment terms, etc , It is necessary to do a good job in risk management and control in each link , To meet the regulatory requirements for cross-border capital transactions .
The above factors are important to XTransfer The security and accuracy of data processing put forward higher requirements . On this basis ,XTransfer be based on Flink Built its own big data platform , It can effectively guarantee cross-border B2B The data on the whole link can be effectively collected 、 Processing and calculation , And meet the requirements of high security 、 Low latency 、 High precision requirements .

Change data collection CDC It is the key link of data integration . Before use Flink CDC Before , In general use Debezium、Canal Etc CDC Tool to extract the change log of the database , And forward it to Kafka in , Downstream read Kafka The change log in . This architecture has the following pain points :
- There are many deployment components , The cost of operation and maintenance is high ;
- Downstream data consumption logic needs to be adapted according to the writing end , There is a certain development cost ;
- Data subscription configuration is complex , Not like Flink CDC Same only through SQL Statement defines a complete data synchronization logic ;
- It is difficult to meet all the requirements + Incremental acquisition , May need to introduce DataX Equal volume acquisition module ;
- The comparison favors the collection of change data , The ability to process and filter data is weak ;
- It is difficult to meet the scenario of widening heterogeneous data sources .
At present, our big data platform mainly uses Flink CDC To capture change data , It has the following advantages :
1. Real time data integration

- No additional deployment Debezium、Canal、Datax And so on , The cost of operation and maintenance is greatly reduced ;
- Support rich data sources , It can also be reused Flink Existing connectors Data acquisition and writing , It can cover most business scenarios ;
- It reduces the difficulty of development , Only through Flink SQL A complete data integration workflow can be defined ;
- Strong data processing ability , Depending on Flink The powerful computing power of the platform can realize streaming ETL Even heterogeneous data sources join、group by etc. .
2. Build real-time data warehouse

- Greatly simplify the deployment difficulty of real-time data warehouse , adopt Flink CDC Real time collection of database changes , And write Kafka、Iceberg、Hudi、TiDB Wait for the database , You can use Flink Deep data mining and data processing .
- Flink The computing engine of can support the integrated computing mode of stream and batch , No more maintenance of multiple computing engines , It can greatly reduce the development cost of data .
3. Real time risk control
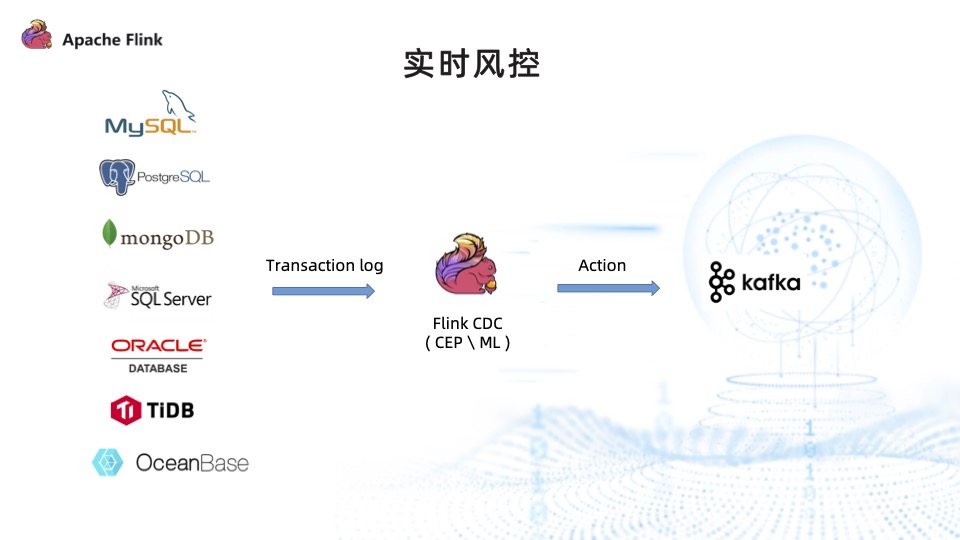
- Real time risk control used to be Kafka The method of Zhongfa business event is implemented , While using Flink CDC after , Risk control events can be captured directly from the business library , And then through Flink CDC To handle complex events .
- You can run the model , In order to pass the Flink ML、Alink To enrich the ability of machine learning . Finally, the disposal results of these real-time risk control will be put back into Kafka, Issue risk control instructions .
3、 ... and 、MongoDB CDC Connector Production tuning

MongoDB CDC Connector The following requirements apply to the use of :
- In view of the use of Change Streams To achieve MongoDB CDC Connector, So it requires MongoDB The minimum available version of is 3.6, Comparison recommendation 4.0.8 And above .
- You must use the cluster deployment mode . Due to subscription MongoDB Of Change Streams The nodes are required to replicate data with each other , stand-alone MongoDB Data cannot be copied to each other , either Oplog, Only in the case of replica set or shard set can there be a data replication mechanism .
- Need to use WireTiger Storage engine , Use pv1 Copy agreement .
- Need to own ChangeStream and find User permissions .

Use MongoDB CDC Connector Pay attention to the setting when you are working Oplog Capacity and expiration time of .MongoDB oplog Is a special set with capacity , After the capacity reaches the maximum , Historical data will be discarded . and Change Streams adopt resume token To recover , Too small oplog Capacity can lead to resume token Corresponding oplog The record no longer exists , namely resume token Be overdue , Leading to Change Streams Cannot be recovered .
have access to replSetResizeOplog Set up oplog Capacity and minimum retention time ,MongoDB 4.4 The minimum time can also be set after version . generally speaking , Recommendations in production environments oplog Reserve no less than 7 God .

For some tables that change slowly , It is recommended to enable the heartbeat event in the configuration . Change events and heartbeat events can be pushed forward at the same time resume token, For tables that change slowly , You can refresh through the heartbeat event resume token Avoid expiration .
Can pass heartbeat.interval.ms Set the heartbeat interval .

Because only MongoDB Of Change Streams convert to Flink Of Upsert changelog, It is similar to Upsert Kafka form , To make up –U Pre image value , Will add an operator ChangelogNormalize, And this leads to additional state overhead . Therefore, it is recommended to use in the production environment RocksDB State Backend.

When the parameters of the default connection cannot meet the use requirements , Can be set by connection.options Configure items to pass MongoDB Supported connection parameters .
For example, connection. MongoDB The database created by the user of is not in admin in , You can set parameters to specify which database to use to authenticate the current user , You can also set the maximum connection parameters of the connection pool ,MongoDB The connection string of supports these parameters by default .

Regular matching multi library 、 Multi table yes MongoDB CDC Connector stay 2.0 New features available after version . We need to pay attention to , If the database name uses a regular parameter , You need to have readAnyDatabase role . because MongoDB Of Change Streams Only in the whole cluster 、 Database and collection On granularity . If you need to filter the entire database , The database can only be enabled on the entire cluster when performing regular matching Change Streams , And then through Pipeline Filter database changes . It can be done by Ddatabase and Collection Write the regular expression in the two parameters for multi library 、 Multi table subscription .
Four 、MongoDB CDC Connector Parallelization Snapshot improvement

To speed up Snapshot The speed of , have access to Flip-27 Introduced source To carry out parallel transformation . First, use a split Enumerator , According to certain segmentation strategies , Will be a complete Snapshot The task is divided into several subtasks , Then assign to multiple split reader Do it in parallel Snapshot , So as to improve the running speed of the overall task .
But in MongoDB in , In most cases, the components are ObjectID, The first four bytes are UNIX describe , The middle five bytes are a random value , The last three bytes are a self increment . Documents inserted in the same description are not strictly incremental , Intermediate random values may affect local strict incrementing , But on the whole , Still able to meet the increasing trend .
therefore , differ MySQL Incremental component of ,MongoDB Not suitable for offset + limit A simple splitting of its set by the segmentation strategy of , Need to aim at ObjectID Adopt targeted segmentation strategies .

Final , We have adopted the following three MongoDB Segmentation strategy :
- Sample Sampling is divided into barrels : The principle is to use $sample Command to collection Random sampling , Through the average document size and each chunk To estimate the number of barrels needed . The query permission of the corresponding set is required , Its advantage is that it is faster , It is applicable to the set with large amount of data but without fragmentation ; The disadvantage is that the sampling estimation mode is used , The result of barrel division cannot be absolutely uniform .
- SplitVector Index sharding :SplitVector yes MongoDB Calculation chunk Internal command of the split point , Each... Is calculated by accessing the specified index chunk The boundary of the . Ask to have SplitVector jurisdiction , Its advantage is high speed ,chunk Uniform results ; The disadvantage is that for a large amount of data and a fragmented set , It is better to read directly config Already divided in the library chunks Metadata .
- Chunks Metadata reading : because MongoDB stay config The database will store the actual sharding results of the sharding set , So you can directly config Read the actual partition result of the partition set in . Ask to have config Library read permission , Only for sliced sets . Its advantage is high speed , There is no need to recalculate chunk Split point ,chunk Uniform results , By default 64MB; The disadvantage is that it can not meet all the scenarios , Only for sliced scenes .

The picture above shows sample Sampling barrel division example . On the left is a complete set , Set the number of samples from the complete set , Then reduce the whole sample , And divide the barrels according to the samples after sampling , The end result is what we want chunks The border .
sample The order is MongoDB A built-in command for sampling . When the sample value is less than 5% Under the circumstances , Use pseudo-random algorithm for sampling ; The sample value is greater than 5% Under the circumstances , Use random sorting first , Then choose before N A document . Its uniformity and time-consuming mainly depend on the random algorithm and the number of samples , It's a trade-off between uniformity and segmentation speed , It is suitable for fast segmentation , But it can tolerate scenes with uneven segmentation results .
In the actual test ,sample The uniformity of sampling has a good performance .

The picture above shows SplitVector Index sharding example . On the left is the original set , adopt SplitVector The command specifies the index to be accessed , by ID Indexes . You can set each chunk Size , Unit is MB, And then use SplitVector Command access index , And calculate the boundary of each block by index .
It's fast ,chunk The results are also uniform , Suitable for most scenarios .

The picture above shows config.chuncks Read example , That is, read directly MongoDB Already divided chunks Metadata . stay Config Server Each... Is stored in Shard、 The machine on which it is located and each Shard The boundary of the . For piecemeal sets , Can be directly in chunks Read its boundary information in , There is no need to calculate these splitting points repeatedly , It can also ensure that every chunk Can be read on a single machine , Extremely fast , It has a good performance in the scene of large-scale fragment collection .
5、 ... and 、 Follow up planning

Flink CDC The follow-up planning of the project is mainly divided into the following five aspects :
- First of all , Assist in improvement Flink CDC The incremental Snapshot frame ;
- second , Use MongoDB CDC docking Flink CDC The incremental Snapshot frame , Enable it to support parallelism Snapshot improvement ;
- Third ,MongoDB CDC Support Flink RawType. For some flexible storage structures RawType transformation , The user can go through UDF Custom parsing in the form of ;
- Fourth ,MongoDB CDC Support the collection of change data from the specified location ;
- The fifth ,MongoDB CDC Optimization of stability .
Question and answer
Q:MongoDB CDC Is the delay high ? Whether you need to reduce latency by sacrificing performance ?
A:MongoDB CDC The delay is not high , During full collection, it passes through changelog normalize It might be for CDC Incremental acquisition of causes some back pressure , But this can be done through MongoDB Parallel transformation 、 Ways to increase resources to avoid .
Q: When the default connection cannot meet the requirements ?
A:MongoDB Of users can be in any database 、 Create in any sub Library . If not in admin Create users in the database of , When authenticating, you need to explicitly specify which database to authenticate users in , You can also set parameters such as the maximum connection size .
Q:MongoDB current DBlog Does it support lock free concurrent reading ?
A:DBlog The ability to have incremental snapshots concurrently without locks , But because MongoDB Difficult to access current changelog The locus of , Therefore, incremental snapshots cannot be realized immediately , But lock free concurrency Snapshot Support soon .
边栏推荐
猜你喜欢
![[wechat applet failed to change appid] wechat applet failed to modify appid all the time and reported an error. Tourist appid solution](/img/b7/6ce97e345a4f8fce7f3aeb2c472e13.png)
[wechat applet failed to change appid] wechat applet failed to modify appid all the time and reported an error. Tourist appid solution

【时序预测完整教程】以气温预测为例说明论文组成及PyTorch代码管道构建

How MySQL sums columns

范畴(Category)

NetCore3.1 ping网络是否畅通及获取服务器Cpu、内存使用率
点云转深度图:转化,保存,可视化

HMS Core机器学习服务身份证识别功能,实现信息高效录入

【CVPR2022】CMU《多模态机器学习》教程,200+页阐述表示、对齐、推理、迁移、生成与量化六大挑战的多模态学习系统知识

Inno setup change installation path learning

Grain College p40~43
随机推荐
播放量高达4000w+,情侣如何靠撒狗粮出圈?
Is there any difference between MySQL and Oracle
inno setup 更改安装路径学习
MySQL 5.7 compilation and installation
粗读Targeted Supervised Contrastive Learning for Long-Tailed Recognition
Datagear uses coordinate mapping table to make geographic coordinate data visualization Kanban
uniapp获取登录授权和手机号授权(整理)
Whether MySQL has triggers
机器学习之贝叶斯分类与集成学习
uniapp小程序打开地图选择位置demo效果wx.chooseLocation(整理)
MySQL-CentOS安装MySQL8
Assembly language greedy snake and Tetris dual task design implementation details (III) -- Tetris detailed design
mysql如何對列求和
What are the knowledge points of SQL statements
mysql如何对列求和
新手使用APICloud可视化开发搭建商城主页
Simple use of JS
Codeforces Round #394 (Div. 2) E. Dasha and Puzzle
Jupyter Notebook启动方式及相关问题
自定义代码模板