当前位置:网站首页>“LSTM之父”新作:一种新方法,迈向自我修正的神经网络
“LSTM之父”新作:一种新方法,迈向自我修正的神经网络
2022-06-11 17:51:00 【数据实战派】

神经网络的过程包括其权重矩阵(Weight Matrix:WM)的更新。
一旦网络训练结束,权重矩阵将被永久固定,然后根据网络在测试数据上的泛化结果评估其有效性。然而,许多环境在训练结束后会继续进化,测试数据可能会偏离训练,超出神经网络的泛化能力。
这就需要人工干预,来重新训练或调整模型。相反,一个完全自主的系统应该学会在没有干预的情况下,根据新的经验更新自己的程序。特别是在多任务学习(Multi-task learning)和元学习(Meta-learning,学习如何去学习)中,学习如何保持更新和微调模型是非常重要,这可以帮助网络快速适应各种情况和新挑战。
在A Modern Self-Referential Weight Matrix That Learns to Modify Itself这项研究中,“LSTM之父”Jürgen Schmidhuber等人根据更新和生成权重的现代技术,重新审视90年代以来提出的自我修正权重矩阵(self-referential WM),特别是利用了Fast Weight Programmers(FWPs)背景下建立的机制,推导出一种新型的自我修正的权重矩阵(self-referential WM:SRWM)。
这项研究从以下三种方面对SRWM进行评估:
首先,该模型在标准的小样本学习上取得了具有竞争力的性能,证明了所提模型能够有效地产生有用的自我修正;
其次,通过将小样本学习设置扩展到连续多任务学习设置,测试了SRWM在运行时适应任务实时变化的能力;
最后,在ProcGen游戏环境设置的多任务强化学习(RL)环境中对其进行了评估,其中包括程序性生成的游戏环境。总的来说,证明了本文所提方法的实际适用性和强性能。
新型自我修正权重矩阵
本文提出的新型自我修正权重矩阵(SRWM)与最近提出的FWPs变体类似,通过学习自己发明的键/值的“训练”模式和学习速率进行自我训练,调用基于外积(outer products)和delta函数更新规则的基本编程指令。
具体步骤如下:
给定t时刻的输入xt∈Rdin,本文的SRWM Wt−1∈R(dout+2*din+1)×din将会产生四个变量[yt,qt,kt,βt]。
其中,yt∈Rdout是该层在当前时间步长的输出,qt∈Rdin和kt∈Rdin是查询向量和键向量,βt∈R是根据delta函数使用的自创学习率。与90年代提出的原始SRWM论文引入的术语类似,kt∈Rdin是修正键向量,代表着键向量,它的当前值在SRWM中必须被修正;qt∈Rdin是查询向量,它被再次送入SRWM,以检索一个新的“值”向量,并与修正键向量相关联。
整体的动态可以简单地表达如下: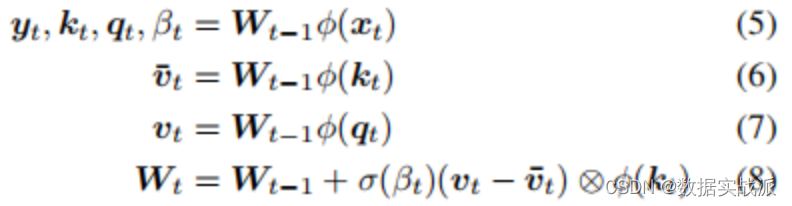
其中,值向量有维数:vt ,∈R(dout+2*din+1)。模型如图1所示。

图1 一个“现代的”自指权重矩阵(SRWM)
重要的是,SRWM中W0的初始值是该层中唯一需要经过梯度下降训练的参数。
在实践中,本文将矩阵的输出维度从“3D+1”(dout+2din+1) 扩展到 “3D+4”(dout+2din+4)来生成4个不同的、自行发明的时变学习速率βt∈R4,用于式(8)中的Wt−1=[Wyt−1,Wqt−1,Wtk−1,Wβt−1]的四个子矩阵的计算,继而用于生成式(5)中的yt, qt, kt和β。为了提高计算效率,本文还利用了普通的Transformers模型中的多头计算。
上述的SRWM可被用来替换任何常规的权重矩阵。这里本文主要关注一个模型,它可以通过用相应的SRWM中的式(5)-(8)取代基准模型DeltaNet中的式(1)-(4)而得到。
实验结果
实验的总体目标是评估所提出的SRWM在各种需要“良好”自我修改类型的任务上的性能,因此对标准监督的小样本(few-shot)学习任务和在游戏环境中的多任务强化学习进行了实验。
1. 标准小样本(Few-Shot)学习
小样本图像分类任务或称为基于包含C类数据集的N-way K-shot图像分类任务,是通过所谓的场景来组织的。
在每一个场景中,从C类中随机抽取N个不同的类,由此产生的N类被重新标记的数据集,将N个不同的随机标签索引中的一个分配给每一个类。对于这N个类中的每一个,随机抽取K个样本。由此得到的N×K个标签图像的集合称为支持集。该任务的目标是根据支持集中可用的信息,预测从N类中的一类中采样的另一幅图像(不在支持集中的查询图像)的标签。
虽然有好几种方法可以解决这个问题,但本文采用顺序学习方法来评估本文的SRWM。也就是说,将支持集的图像/标签对随机排序,形成一个由序列处理神经网络(例如,循环神经网络)读取的序列。对应的神经网络通过将支持集信息编码为其内部状态来预测查询图像的标签。在本文提出的SRWM中,模型在读取支持集项的序列时生成自己的更新权重,生成的权重用于计算对查询图像的最终预测。为了详细说明这种方法,还需要解释如何将输入图像/标签对输入到模型中。
这里本文采用Mishra等人使用的方法,称为图2所示的同步标签设置,这是专门为N-way K-shot学习设计的策略。即对支持集中的N×K个项目,同时将输入及其标签输送给模型。该模型只预测第(N×K+1)个输入的标签,即没有标签的查询图像。本文称另一种方法为延迟标签设置(如图3所示)。
事实上,因为Mishra等人提出的SNAIL模型是一个类似于transformer的模型(规则前馈块被一维卷积代替),因此将其作为本文实验的基准模型,还在基准模型中引入了Oreshkin等人提出的TADAM方法。
然而,本文注意到,TADAM是一种专门为小样本学习设计的方法,与本文的模型和SNAIL不一样,SNAIL是适用于小样本学习之外的通用序列处理神经网络。

图2 N-way K-shot学习的同步标签设置。正确的标签与前N×K个标记相应的输入一起作为输入。只对第(NK+1)个无标签输入的标签进行预测。
图3 延迟标签设置。正确的标签在对应输入的后一步被输入。在每一步进行预测。
最终的性能受视觉特征提取器选择的直接影响,视觉特征提取器使用视觉模型将输入图像转换为一个紧凑的特征向量,然后将其提供给序列处理模块。
在这里,本文展示了在这些基准模型上使用两种流行特征提取器的结果:Conv-4和Res-12。结果如表1所示。
总体而言,所提出的SRWM性能良好。将SRWM与一般的SNAIL模型进行比较,SRWM在Mini-ImageNet2上实现了独立于视觉后端(Conv-4或Res12)的具有竞争力的性能。
DeltaNet和SRWM具有相似的性能。这是一个令人满意的结果,因为它表明单个自修正的WM(而不是单独的慢速和快速网络)在这个单一任务场景中仍然具有竞争力。

表1 在Omniglot、Mini-ImageNet和FC100上使用Conv4或Res-12视觉特征提取器进行单任务、 5-way、小样本分类测试准确率(%)。
本文发现虽然TADAM在 5-shot Mini-ImageNet上的表现优于SRWM,但在1-shot、5-shot FC100以及 1-shot MiniImangeNet上的性能与SRWM不相上下。尽管SRWM是一种非常通用的方法,但它的整体性能非常具有竞争力,这表明了所提出的自我修正权重矩阵的有效性(本实验的主要目标)。
2. 连续的多任务适应性
本节需要在运行时适应环境变化的任务上测试它的自适应性。本文对上述小样本学习进行了两个修改。
首先,不使用同步标签设置(图2)对模型进行N-way K-shot分类的专门训练,而是在如图3所示的延迟标签设置中训练本文的模型。此处,模型在每个时间步下,通过接收一个需要分类的输入图像和前一个输入的正确标签(因此标签输送被移动/延迟一个时间步)来做出预测。这种设置便于在连续的预测/解决方案流上评估模型。其次,通过将来自两个不同数据集的两个图像序列(Omniglot和Mini-ImageNet)串联起来,构造出要预测的图像序列。该模型首先接收来自其中一个数据集的图像流,在某个时刻,使数据集突然发生变化,以模拟环境的变化。模型必须学会在没有人为干预的情况下,在程序的持续执行中适应这种转变。
注意,本文的目标是构造一个任务,它需要适应模型运行期间的突然变化。这不同于连续的小样本学习的目标,即在多个小样本学习任务上连续进行元学习。
因此,本文在一个5-way分类设置中进行实验,将Omniglot和Mini-ImageNet片段串联起来,每个片段中的每个类包含多达15个示例。
每个batch的连接顺序是交替的,训练片段的长度是随机裁剪的。无论模型类型如何,本文发现延迟标签设置下的训练模型比同步标签设置下的训练模型更难。本文观察到,在许多配置中,模型被卡在一个次优行为中,在这个行为中,它学习提高了零样本(zero-shot)的类平均精度(显然是通过学习输出序列中第一次出现的新类的一个未使用的标签),但在反馈中的每一步中都不能正确地学习。本文确定的最关键的超参数是足够大的批处理大小。
最后,本文在这个连续自适应任务上成功的训练了DeltaNet基准模型和SRWM。图4显示了SRWM的测试时间精度随着输入的增加而变化的情况。在这个测试设置中,模型从接收来自Omniglot数据集的一系列样本开始。在第74代任务发生变化;此时模型必须对从Mini-ImageNet数据集采样的图像进行分类。这个变化导致模型的准确率明显下降,这是因为模型不知道新的数据点属于哪个类,但它能够有效地适应自己,开始学习第二个任务。表2比较了DeltaNet和SRWM。虽然他们在基于Omniglot的测试序列的第一部分的表现相似,SRWM在Mini-ImageNet的第二部分采样中实现了更高的精度,显示了其快速适应能力。
图4 基于SRWM的测试精度(%)(使用Conv4后端),该模型作为连续多任务适应设置中转发步骤数量的函数(第4.2节)。数据点流以延迟标签的方式提供给模型(图3)。数据点从Omniglot进行采样直到第74步(精度下降),然后从Mini-ImageNet采样。

表2 连续多任务小样本学习实验的总准确率和实例级准确率(%)(第4.2节)。对于实例级精度,列k∈{1,2,3,5,10}表示每个类中第k个实例的正确预测百分比。测试时间的场景下的模型首先被要求学习预测Omniglot和Mini-ImageNet。Conv4后端用于两种模型。
3.多任务强化学习(RL)
最后,本文在采用程序生成的ProcGen游戏环境设置的多任务RL上评估所提出的模型。相应的设置如图5所示。

图5 多任务RL的插图。初始权矩阵W0对所有任务和场景是相同的。有效的权重矩阵是特定任务/事件的输入流的函数。

表3展示了聚合的标准化分数。
相较于基准模型,SRWM性能的提高在Bigfish和Starpilot这两个环境尤其大。本文对这两个案例进行单独研究。如表所示,本文将上述多任务训练与专门在一个环境下训练50M步的专家训练进行了比较。
在Starpilot上,本文观察到自我修正机制甚至在单个任务情况下也有改进。Bigfish的例子更有趣:在专家训练案例中,具有自我修正能力和不具有自我修正能力的模型性能接近。然而,自我修正模型在多任务设置中获得了更好的分数,在多任务设置中,基准模型的性能有很大的幅度的下降。这验证了SRWM能够适应多任务场景中每个环境的能力。

表4 多任务与专家训练模型性能的比较。在ProcGen的简单分布中获得的原始分数。
作为消融研究,本文通过在每个固定时间跨度(其长度为反向传播跨度)后重置权重更新来训练和评估SRWM。相比较那些没有自我修正的模型(表3)而未能利用SRWM机制模型,该模型在训练和测试分支上分别获得28.5(1.2)和16.1(2.2)的分数。
三个实验中,证明了本文提出的SRWM是实用的,并且在有监督的小样本学习和多任务强化学习,以及程序生成的游戏环境表现良好。希望本文的结果可以鼓励对自我修正神经网络的进一步研究。
https://arxiv.org/abs/2202.05780
边栏推荐
- Delete the penultimate node of the linked list ---2022/02/22
- Install MariaDB 10.5.7 (tar package installation)
- [MapReduce] a complete Mr program case teaches you how to package and run with idea
- 单选按钮 文字背景同时改变
- Global and Chinese market of high frequency bipolar junction transistors 2022-2028: Research Report on technology, participants, trends, market size and share
- GB gb28181 protocol video platform easygbs adds or deletes offline channels
- Intelligent overall legend, legend of wiring, security, radio conference, television, building, fire protection and electrical diagram [transferred from wechat official account weak current classroom]
- Mysql8 installation, Navicat installation, sqli labs setup
- RadioGroup动态添加RadioButton
- 送给大模型的「高考」卷:442人联名论文给大模型提出204个任务,谷歌领衔
猜你喜欢
![Spring 2021 daily question [week3 not finished]](/img/a4/72f2235d014613d26be0fc3524d236.jpg)
Spring 2021 daily question [week3 not finished]

Tle6389-2g V50's unique pwm/pfm control scheme has a duty cycle of up to 100%, forming a very low differential pressure - keshijin mall

Tle6288r is a 6-channel (150 MOhm) intelligent multi-channel switch using intelligent power technology - keshijin mall

ADB command learning notes

Why is the UDP stream set to 1316 bytes
![[collect first and use it sooner or later] 100 Flink high-frequency interview questions series (II)](/img/cf/44b3983dd5d5f7b92d90d918215908.png)
[collect first and use it sooner or later] 100 Flink high-frequency interview questions series (II)

NFT platform development NFT mall source code NFT mall development chain game development

Initial experience of MariaDB spider sharding engine

RadioGroup动态添加RadioButton

Nocturnal installs APK and BP agent
随机推荐
Can 400 fans earn 20W a month? How did you do it?
R language to find missing value location of data set
Speed adjustment of tidb DDL
【题解】Codeforces Round #798 (Div. 2)
Tle6288r is a 6-channel (150 MOhm) intelligent multi-channel switch using intelligent power technology - keshijin mall
How ZABBIX can customize MySQL monitoring items and trigger alarms
mysql8安装,navicat安装,sqli-labs搭建
安全领域常规术语
Radiogroup dynamically add RadioButton
GB gb28181 protocol video platform easygbs adds or deletes offline channels
Hello go (XI). Go language common standard library I
Winter vacation daily question 2022 [week1 not finished]
There are three standards and three methods, i.e. fast growth and quick realization. How to choose the direction for making short videos of we media?
Threejs uses indexeddb cache to load GLB model
Experiment 2: write a program and verify that the linear table sequence represents all operations
vulhub
Initial egg framework
关于元素位置和尺寸
7-1 are prime numbers
Spring 2021 daily question [week3 not finished]