当前位置:网站首页>Atomic operation of day4 practice in 2022cuda summer training camp
Atomic operation of day4 practice in 2022cuda summer training camp
2022-07-29 10:27:00 【Hua Weiyun】

2022CUDA Summer training camp Day1 practice https://bbs.huaweicloud.com/blogs/364478
2022CUDA Summer training camp Day2 practice https://bbs.huaweicloud.com/blogs/364479
2022CUDA Summer training camp Day3 practice https://bbs.huaweicloud.com/blogs/364480
2022CUDA Summer training camp Day4 Unified memory of practice https://bbs.huaweicloud.com/blogs/364481
Today is the fourth day , The theme is unified memory 、 Atomic operation, etc .
( Two ) Atomic manipulation
CUDA The atomic operation of is for Global Memory Or is it Shared Memory.
Why introduce the concept of atomic operation . We learned from the training camp course a few days ago :
- Shared Memory Can be the same block All of the thread visit ( Reading and writing ) Of .
- Global Memory Equivalent to video memory , Can be all thread visit ( Reading and writing ) Of .
that , These two kinds of Memory, You are likely to encounter multiple thread The problem of reading and writing the same memory area at the same time .
Suppose both threads are doing “ Read - modify - write in " operation , If in this operation , There are interlaced situations , There will be chaos . for instance , For example, the value in a block of memory is 10,A、B Two uses are ” Add one “ Threads of read this block of memory at the same time , Then add each one 1,A Change the value to 11, Write it back ;B Also change the value to 11, Also wrote back . This is the time , The result is 11. But obviously, the result we require should be 12.
We have to ask for “ Read - modify - write in " Bundled into a logical single operation , It's not divisible , Logically proceed in sequence , Ensure one-time success . Only in this way can we ensure the correctness of the results of any operation on variables .
The commonly used atomic operation functions are as follows :
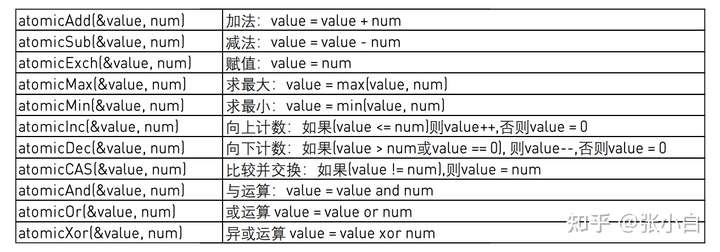
Most of these functions return variable values before atomic operations .
Atom operated functions are polymorphic , Applicable to versions of different data types and precision , With atomicAdd For example :

Let's fight !
(a) actual combat 1: Yes 1000 Sum the integer array of ten thousand
About Sum all the elements of the vector This matter , Lecturer Mr. He provided a framework . He passed ppt The principle of this framework is introduced . It looks more complicated . He only 32 Taking the sum of data as an example, this process is illustrated :

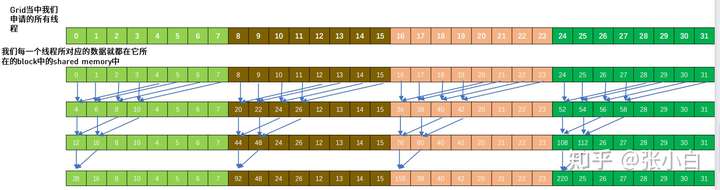
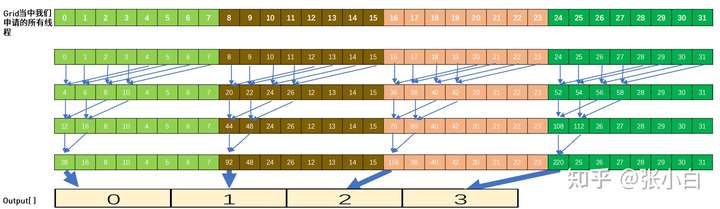
The specific code is as follows :
sum.cu
#include<stdio.h>#include<stdint.h>#include<time.h> //for time()#include<stdlib.h> //for srand()/rand()#include<sys/time.h> //for gettimeofday()/struct timeval#include"error.cuh"#define N 10000000#define BLOCK_SIZE 256#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) __managed__ int source[N]; //input data__managed__ int final_result[1] = {0}; //scalar output__global__ void _sum_gpu(int *input, int count, int *output){ __shared__ int sum_per_block[BLOCK_SIZE]; int temp = 0; for (int idx = threadIdx.x + blockDim.x * blockIdx.x; idx < count; idx += gridDim.x * blockDim.x ) { temp += input[idx]; } sum_per_block[threadIdx.x] = temp; //the per-thread partial sum is temp! __syncthreads(); //**********shared memory summation stage*********** for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2) { int double_kill = -1; if (threadIdx.x < length) { double_kill = sum_per_block[threadIdx.x] + sum_per_block[threadIdx.x + length]; } __syncthreads(); //why we need two __syncthreads() here, and, if (threadIdx.x < length) { sum_per_block[threadIdx.x] = double_kill; } __syncthreads(); //....here ? } //the per-block partial sum is sum_per_block[0] if (blockDim.x * blockIdx.x < count) //in case that our users are naughty { //the final reduction performed by atomicAdd() if (threadIdx.x == 0) atomicAdd(output, sum_per_block[0]); }}int _sum_cpu(int *ptr, int count){ int sum = 0; for (int i = 0; i < count; i++) { sum += ptr[i]; } return sum;}void _init(int *ptr, int count){ uint32_t seed = (uint32_t)time(NULL); //make huan happy srand(seed); //reseeding the random generator //filling the buffer with random data for (int i = 0; i < count; i++) ptr[i] = rand();}double get_time(){ struct timeval tv; gettimeofday(&tv, NULL); return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);}int main(){ //********************************** fprintf(stderr, "filling the buffer with %d elements...\n", N); _init(source, N); //********************************** //Now we are going to kick start your kernel. cudaDeviceSynchronize(); //steady! ready! go! fprintf(stderr, "Running on GPU...\n"); double t0 = get_time(); _sum_gpu<<<BLOCKS, BLOCK_SIZE>>>(source, N, final_result); CHECK(cudaGetLastError()); //checking for launch failures CHECK(cudaDeviceSynchronize()); //checking for run-time failursdouble t1 = get_time(); int A = final_result[0]; fprintf(stderr, "GPU sum: %u\n", A); //********************************** //Now we are going to exercise your CPU... fprintf(stderr, "Running on CPU...\n");double t2 = get_time(); int B = _sum_cpu(source, N);double t3 = get_time(); fprintf(stderr, "CPU sum: %u\n", B); //******The last judgement********** if (A == B) { fprintf(stderr, "Test Passed!\n"); } else { fprintf(stderr, "Test failed!\n"); exit(-1); } //****and some timing details******* fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0); fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0); return 0;} Because its principle is slightly complex , Zhang Xiaobai thinks so :
The above code actually provides a GPU Traverse the frame of all fields , This is a divide and rule idea :
block Multiple threads in are responsible for multiple data points , These points are regulated (reduce/ cut ) To a scalar . So each of them block There is a scalar result in . but blocks There's a lot of , An array of these variables / vector , It still needs to be reduced twice to the final 1 A scalar value .
There are two steps in the above process reduce, The first step is to use parallel halving ( Statute ), The second step is to operate the function directly with atoms atomicAdd Statute . After two steps , Get a single point .
Let's run it and try :
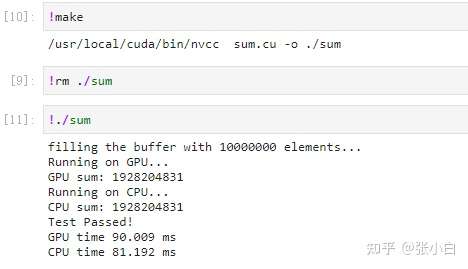
so ,CPU and GPU The result of summation is consistent , It shows that this framework for traversing all fields is no problem .
Look at the performance :
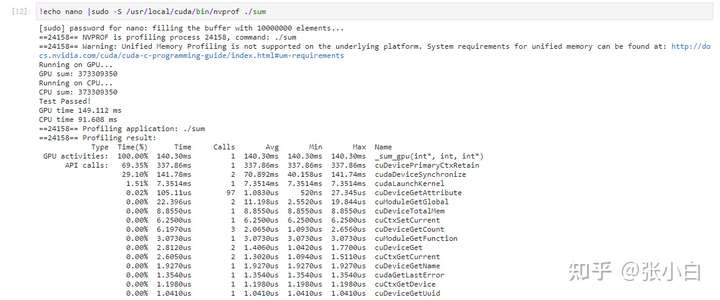
(b) actual combat 2: Yes 1000 The integer array of ten thousand finds the maximum and minimum values
Based on the above actual combat 1 The principle of analysis , We then analyze the solution of this problem :
Also use two steps reduce, The first step is to use parallel halving ( Statute ), The second step is to operate directly with atoms atomicMax and atomicMin Statute . After two steps , Get a single point ( Maximum / minimum value ).
So we are like building blocks , Will a sum Change to one max And a min, The code changes as follows :
min_or_max.cu
#include<stdio.h>#include<stdint.h>#include<time.h> //for time()#include<stdlib.h> //for srand()/rand()#include<sys/time.h> //for gettimeofday()/struct timeval#include"error.cuh"#define N 10000000#define BLOCK_SIZE 256#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) __managed__ int source[N]; //input data//__managed__ int final_result[2] = {INT_MIN,INT_MAX}; //scalar output__managed__ int final_result_max = INT_MIN; //scalar output__managed__ int final_result_min = INT_MAX; //scalar output__global__ void _sum_min_or_max(int *input, int count, int *max_output, int *min_output){ __shared__ int max_per_block[BLOCK_SIZE]; __shared__ int min_per_block[BLOCK_SIZE]; int max_temp = 0; int min_temp = 0; for (int idx = threadIdx.x + blockDim.x * blockIdx.x; idx < count; idx += gridDim.x * blockDim.x ) { //temp += input[idx]; max_temp = (input[idx] > max_temp) ? input[idx] :max_temp; min_temp = (input[idx] < min_temp) ? input[idx] :min_temp; } max_per_block[threadIdx.x] = max_temp; //the per-thread partial max is temp! min_per_block[threadIdx.x] = min_temp; //the per-thread partial max is temp! __syncthreads(); //**********shared memory summation stage*********** for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2) { int max_double_kill = -1; int min_double_kill = -1; if (threadIdx.x < length) { max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length]; min_double_kill = (min_per_block[threadIdx.x] < min_per_block[threadIdx.x + length]) ? min_per_block[threadIdx.x] : min_per_block[threadIdx.x + length]; } __syncthreads(); //why we need two __syncthreads() here, and, if (threadIdx.x < length) { max_per_block[threadIdx.x] = max_double_kill; min_per_block[threadIdx.x] = min_double_kill; } __syncthreads(); //....here ? } //the per-block partial sum is sum_per_block[0] if (blockDim.x * blockIdx.x < count) //in case that our users are naughty { //the final reduction performed by atomicAdd() //if (threadIdx.x == 0) atomicAdd(output, max_per_block[0]); if (threadIdx.x == 0) atomicMax(max_output, max_per_block[0]); if (threadIdx.x == 0) atomicMin(min_output, min_per_block[0]); }}int _max_min_cpu(int *ptr, int count, int *max1, int *min1){ int max = INT_MIN; int min = INT_MAX; for (int i = 0; i < count; i++) { //sum += ptr[i]; max = (ptr[i] > max)? ptr[i]:max; min = (ptr[i] < min)? ptr[i]:min; } //printf(" CPU max = %d\n", max); //printf(" CPU min = %d\n", min); *max1 = max; *min1 = min; return 0;}void _init(int *ptr, int count){ uint32_t seed = (uint32_t)time(NULL); //make huan happy //srand(seed); //reseeding the random generator //filling the buffer with random data for (int i = 0; i < count; i++) { //ptr[i] = rand() % 100000000; ptr[i] = rand() ; if (i % 2 == 0) ptr[i] = 0 - ptr[i] ; } }double get_time(){ struct timeval tv; gettimeofday(&tv, NULL); return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);}int main(){ //********************************** fprintf(stderr, "filling the buffer with %d elements...\n", N); _init(source, N); //********************************** //Now we are going to kick start your kernel. cudaDeviceSynchronize(); //steady! ready! go! fprintf(stderr, "Running on GPU...\n"); double t0 = get_time(); _sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N, &final_result_max, &final_result_min); CHECK(cudaGetLastError()); //checking for launch failures CHECK(cudaDeviceSynchronize()); //checking for run-time failures double t1 = get_time(); //int A = final_result[0]; fprintf(stderr, " GPU max: %d\n", final_result_max); fprintf(stderr, " GPU min: %d\n", final_result_min); //********************************** //Now we are going to exercise your CPU... fprintf(stderr, "Running on CPU...\n");double t2 = get_time(); int cpu_max=0; int cpu_min=0; int B = _max_min_cpu(source, N, &cpu_max, &cpu_min); printf(" CPU max = %d\n", cpu_max); printf(" CPU min = %d\n", cpu_min); double t3 = get_time(); //fprintf(stderr, "CPU sum: %u\n", B); //******The last judgement********** if ( final_result_max == cpu_max && final_result_min == cpu_min ) { fprintf(stderr, "Test Passed!\n"); } else { fprintf(stderr, "Test failed!\n"); exit(-1); } //****and some timing details******* fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0); fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0); return 0;} Here are a few points that need to be pointed out :
(1) Initialize the maximum variable final_result_max When , Give it a minimum INT_MIN; Initialize the minimum value variable final_result_min When , Give it a maximum INT_MAX, So when it compares , Will be compared , Change to the latest value . If someone accidentally writes it backwards , Then it's over . If you don't believe it, you can try .
(2) Is producing 1000 Ten thousand random numbers , Zhang Xiaobai adopted teacher he's suggestion , Every two numbers has a positive number , There is a negative number . This will not cause the original minimum value to always be 0 The situation of .
Compile operation :
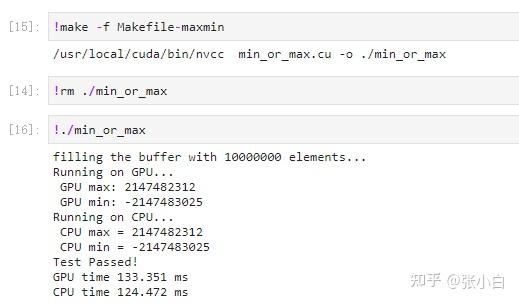
look CPU and GPU The calculated results are consistent . What about? ? Easy ?
The above code , Zhang Xiaobai is lazy , Two are used managed Variables record results , Zhang Xiaobai looked at the homework behind , There's another one “ find 1000 10000 data in the top 10 A maximum of ” The subject of , It still feels like Array will be more suitable . Maybe it can be upgraded seamlessly to solve the following problem , So Zhang Xiaobai made the following changes :
#include<stdio.h>#include<stdint.h>#include<time.h> //for time()#include<stdlib.h> //for srand()/rand()#include<sys/time.h> //for gettimeofday()/struct timeval#include"error.cuh"#define N 10000000#define BLOCK_SIZE 256#define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) __managed__ int source[N]; //input data__managed__ int final_result[2] = {INT_MIN,INT_MAX}; //scalar output//__managed__ int final_result_max = INT_MIN; //scalar output//__managed__ int final_result_min = INT_MAX; //scalar output//__global__ void _sum_min_or_max(int *input, int count, int *max_output, int *min_output)__global__ void _sum_min_or_max(int *input, int count,int *output){ __shared__ int max_per_block[BLOCK_SIZE]; __shared__ int min_per_block[BLOCK_SIZE]; int max_temp = 0; int min_temp = 0; for (int idx = threadIdx.x + blockDim.x * blockIdx.x; idx < count; idx += gridDim.x * blockDim.x ) { //temp += input[idx]; max_temp = (input[idx] > max_temp) ? input[idx] :max_temp; min_temp = (input[idx] < min_temp) ? input[idx] :min_temp; } max_per_block[threadIdx.x] = max_temp; //the per-thread partial max is temp! min_per_block[threadIdx.x] = min_temp; //the per-thread partial max is temp! __syncthreads(); //**********shared memory summation stage*********** for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2) { int max_double_kill = -1; int min_double_kill = -1; if (threadIdx.x < length) { max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length]; min_double_kill = (min_per_block[threadIdx.x] < min_per_block[threadIdx.x + length]) ? min_per_block[threadIdx.x] : min_per_block[threadIdx.x + length]; } __syncthreads(); //why we need two __syncthreads() here, and, if (threadIdx.x < length) { max_per_block[threadIdx.x] = max_double_kill; min_per_block[threadIdx.x] = min_double_kill; } __syncthreads(); //....here ? } //the per-block partial sum is sum_per_block[0] if (blockDim.x * blockIdx.x < count) //in case that our users are naughty { //the final reduction performed by atomicAdd() //if (threadIdx.x == 0) atomicAdd(output, max_per_block[0]); //if (threadIdx.x == 0) atomicMax(max_output, max_per_block[0]); //if (threadIdx.x == 0) atomicMin(min_output, min_per_block[0]); if (threadIdx.x == 0) atomicMax(&output[0], max_per_block[0]); if (threadIdx.x == 0) atomicMin(&output[1], min_per_block[0]); }}int _max_min_cpu(int *ptr, int count, int *max1, int *min1){ int max = INT_MIN; int min = INT_MAX; for (int i = 0; i < count; i++) { //sum += ptr[i]; max = (ptr[i] > max)? ptr[i]:max; min = (ptr[i] < min)? ptr[i]:min; } //printf(" CPU max = %d\n", max); //printf(" CPU min = %d\n", min); *max1 = max; *min1 = min; return 0;}void _init(int *ptr, int count){ uint32_t seed = (uint32_t)time(NULL); //make huan happy srand(seed); //reseeding the random generator //filling the buffer with random data for (int i = 0; i < count; i++) { //ptr[i] = rand() % 100000000; ptr[i] = rand() ; if (i % 2 == 0) ptr[i] = 0 - ptr[i] ; } }double get_time(){ struct timeval tv; gettimeofday(&tv, NULL); return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);}int main(){ //********************************** fprintf(stderr, "filling the buffer with %d elements...\n", N); _init(source, N); //********************************** //Now we are going to kick start your kernel. cudaDeviceSynchronize(); //steady! ready! go! fprintf(stderr, "Running on GPU...\n"); double t0 = get_time(); //_sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N, &final_result_max, &final_result_min); _sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N,final_result); CHECK(cudaGetLastError()); //checking for launch failures CHECK(cudaDeviceSynchronize()); //checking for run-time failures double t1 = get_time(); //int A = final_result[0]; //fprintf(stderr, " GPU max: %d\n", final_result_max); //fprintf(stderr, " GPU min: %d\n", final_result_min); fprintf(stderr, " GPU max: %d\n", final_result[0]); fprintf(stderr, " GPU min: %d\n", final_result[1]); //********************************** //Now we are going to exercise your CPU... fprintf(stderr, "Running on CPU...\n");double t2 = get_time(); int cpu_max=0; int cpu_min=0; int B = _max_min_cpu(source, N, &cpu_max, &cpu_min); printf(" CPU max = %d\n", cpu_max); printf(" CPU min = %d\n", cpu_min); double t3 = get_time(); //fprintf(stderr, "CPU sum: %u\n", B); //******The last judgement********** //if ( final_result_max == cpu_max && final_result_min == cpu_min ) if ( final_result[0] == cpu_max && final_result[1] == cpu_min ) { fprintf(stderr, "Test Passed!\n"); } else { fprintf(stderr, "Test failed!\n"); exit(-1); } //****and some timing details******* fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0); fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0); return 0;} Respectively in
Definition :
__managed__ int final_result[2] = {INT_MIN,INT_MAX}; //scalar outputKernel function definition :
__global__ void _sum_min_or_max(int *input, int count,int *output)Kernel operation :
if (threadIdx.x == 0) atomicMax(&output[0], max_per_block[0]); if (threadIdx.x == 0) atomicMin(&output[1], min_per_block[0]); And kernel function calls :
_sum_min_or_max<<<BLOCKS, BLOCK_SIZE>>>(source, N,final_result);These places have been changed .
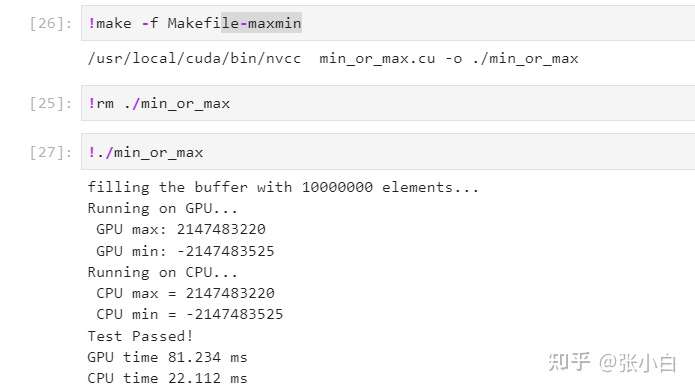
Start compilation , function :
(Quardo P1000 Up operation )
(Nano Up operation )
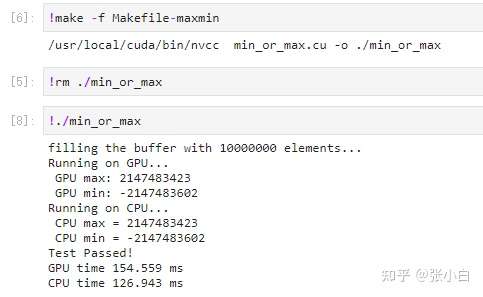
There's no problem running , But it looks like GPU The elapsed time (81ms) Than CPU The elapsed time (22ms) Slow down . The comparison is in Nano On GPU The elapsed time (154ms) Than CPU The elapsed time (126ms), It seems that the result is indeed GPU Speed is not dominant . What's the reason for this ?
The calculation includes Memory access intensive still Computationally intensive Other types . Whether it's addition , still max/min, All are Intensive access to storage The calculation of . Unless a separate graphics card , And prefetch or transfer data to video memory in advance , otherwise GPU Whether it's managed Automatic data migration , perhaps GPU and CPU Enjoy the same bandwidth (Jetson On ), Will not take advantage .
that , How to generalize the process f(a,b) operation , To make GPU It has significant advantages ? Even in Jetson such CPU and GPU Have the same memory access bandwidth , Or even if it is forced to walk slowly PCI-E Transmission bandwidth ,GPU Can still compare CPU It's much faster ?
This problem , Just leave it for everyone to think ! Listening, speaking, reading Teacher fanzheyong's little red book 《CUDA Programming : Foundation and practice 》 You can find a solution ~~

( To be continued )
边栏推荐
- 10 suggestions for 10x improvement of application performance
- 若依集成minio实现分布式文件存储
- This developer, who has been on the list for four consecutive weeks, has lived like a contemporary college student
- remap_ Use of table in impdp
- [fortran]vscode配置fortran跑hello world
- [HFCTF 2021 Final]easyflask
- Vim到底可以配置得多漂亮?
- Consumer electronics, frozen to death in summer
- After eating Alibaba's core notes of highly concurrent programming, the backhand rose 5K
- ECCV 2022 | CMU提出在视觉Transformer上进行递归,不增参数,计算量还少
猜你喜欢

Performance optimization analysis tool | perf

Big cloud service company executives changed: technology gives way to sales

mosquitto_sub -F 参数使用
![[semantic segmentation] 2021-pvt iccv](/img/43/3756c0dbc30fa2871dc8cae5be9bce.png)
[semantic segmentation] 2021-pvt iccv

静态资源映射

函数——(C游记)

可线性渐变的环形进度条的实现探究

Efficient 7 habit learning notes
![[FPGA tutorial case 18] develop low delay open root calculation through ROM](/img/c3/02ce62fafb662d6b13aedde79e21fb.png)
[FPGA tutorial case 18] develop low delay open root calculation through ROM

Intel joins hands with datawhale to launch learning projects!
随机推荐
电竞入亚后,腾讯要做下一个“NBA赛事捕手”?
“为机器立心”:朱松纯团队搭建人与机器人的价值双向对齐系统,解决人机协作领域的重大挑战
Where are those test / development programmers in their 30s? a man should be independent at the age of thirty......
PAHO cross compilation
基于STM32设计的酒驾报警系统
Several common design methods of test cases [easy to understand]
[paper reading] i-bert: integer only Bert quantification
[semantic segmentation] 2021-pvt iccv
Function - (C travel notes)
跟着李老师学线代——行列式(持续更新)
[jetson][reprint]pycharm installed on Jetson
Enterprise architecture | togaf architecture capability framework
Vim到底可以配置得多漂亮?
Attachment of text of chenjie Report
Research on the realization of linear gradient circular progress bar
MySQL 8 of relational database -- deepening and comprehensive learning from the inside out
[reading notes] the way of enterprise IT architecture transformation Alibaba's China Taiwan strategic thinking and Architecture Practice
[paper reading] q-bert: Hessian based ultra low precision quantification of Bert
Leetcode question brushing - sorting
云服务大厂高管大变阵:技术派让位销售派