当前位置:网站首页>Idea runs the wordcount program (detailed steps)
Idea runs the wordcount program (detailed steps)
2022-07-24 11:15:00 【What about Saipan】
IDEA edition :2020.3
Hadoop edition :2.7.7
preparation :
First you have to build your hadoop colony , then IDEA plug-in unit Big Data Tools Can successfully connect hdfs distributed file system
First understand WordCount The principle of the program
then , Create a new one maven Program ( Just define the package name yourself )

![]()
To configure pom.xml file ( Import you hadoop Version corresponding dependencies , my hadoop yes 2.7.7 Of )
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.7</version>
</dependency>
</dependencies>The corresponding version can be found in maven Check in the warehouse :https://mvnrepository.com/

Prepare input files and output directories
Input file :(hdfs://192.168.183.101:9000/test/input/file01.txt)

You can write one locally txt file , And then to hdfs Up ; Or write a file in the virtual machine , Then send the document to hdfs Up . No, you can refer to :HDFS-java Programming
The output directory :“hdfs://192.168.183.101:9000/test/output” there output The folder has not been created , Because the program will create itself when it runs , We don't need to create , If the output directory exists before running, an error will be reported
Configuration file input and output path ( The input and output paths here are all in hdfs Upper )
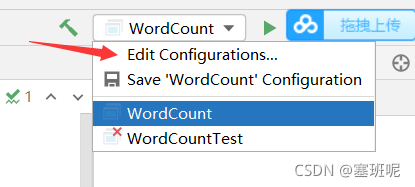

The first is the path of the input file :“hdfs://192.168.183.101:9000/test/input/file01.txt”
The second number is the path of the output file :“hdfs://192.168.183.101:9000/test/output”
Be careful : The output path here must be hdfs That doesn't exist on the , Otherwise, it will report a mistake

Give the complete code
package cn.neu.connection.test;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class Map extends Mapper<Object,Text,Text,IntWritable>{
private static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
StringTokenizer st = new StringTokenizer(value.toString());
while(st.hasMoreTokens()){
word.set(st.nextToken());
context.write(word, one);
}
}
}
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{
private static IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{
int sum = 0;
for(IntWritable val:values){
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception{
System.setProperty("HADOOP_USER_NAME", "lingyi");
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage WordCount <int> <out>");
System.exit(2);
}
Job job = new Job(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
otherArgs[0]="hdfs://192.168.183.101:9000/test/input/file01.txt";// Input path
otherArgs[1]="hdfs://192.168.183.101:9000/test/output";// The output path , Before running hdfs No, well, there should be this path , Otherwise an error
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Two points of attention

Change the user name here to your own
 Input and output paths are defined by themselves , Must be hdfs Upper path ( It can be downloaded from Big Table Tools Get the path quickly in the plug-in )
Input and output paths are defined by themselves , Must be hdfs Upper path ( It can be downloaded from Big Table Tools Get the path quickly in the plug-in )

Come here , The program can run
 If here 1 There are mistakes
If here 1 There are mistakes


At the same time, you can also xshell Or view on the virtual machine part-r-00000 The output file
hadoop fs -cat /test/output/part-r-00000
It's not over yet. .........
There is a problem , Every time you run the program, you have to delete or change the output path to another path
Here's the solution :
Determine whether the output file exists before each run , Delete when there is
The modified code
System.setProperty("HADOOP_USER_NAME", "lingyi");
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage WordCount <int> <out>");
System.exit(2);
}
// Check whether the output path exists before each run , Delete if it exists
Path outPath = new Path(otherArgs[1]);
if(fs.exists(outPath)) {
fs.delete(outPath, true);
}边栏推荐
- [white hat talks about web security] Chapter 1 my security world view
- [white hat talks about web security] Chapter 2 browser security
- 07【Path、Files类的使用】
- 性能测试总结(一)---基础理论篇
- 2022,软测人的平均薪资,看完我瞬间凉了...
- Detailed explanation and example demonstration of Modbus RTU communication protocol
- [golang] golang implements the string interception function substr
- Working principle and function application of frequency converter
- Fiddler抓包工具总结
- Simply understand MODBUS function code and partition
猜你喜欢

Reprint of illustrations in nature, issue 3 - area map (part2-100)

E2PROM read / write (xiicps) on PS side of zcu102 board

2022, the average salary of the soft tester, after reading it, I was instantly cool
Use Modelsim to independently simulate Altera and Xilinx IP cores

黑马瑞吉外卖之员工信息分页查询
JMeter接口测试步骤-安装教程-脚本录制-并发测试
Redismission watchdog implementation mechanism can be understood at a glance

Over the weekend, I had a dinner with the technology gurus and talked about the "golden nine and silver ten" peak of the software testing industry [the trend of involution has been formed]

tcp 服务端接收数据处理思路梳理,以及select: Invalid argument报错 笔记

How to convert word to markdown text
随机推荐
FastCGI运行原理及php-fpm参数配置
《Nature》论文插图复刻第3期—面积图(Part2-100)
Jmeter-Runtime控制器
Installing MySQL under Linux
黑马瑞吉外卖之员工信息分页查询
"Low power Bluetooth module" master-slave integrated Bluetooth sniffer - help smart door lock
【反序列化漏洞-02】PHP反序列化漏洞原理测试及魔术方法总结
Online customer service chat system source code_ Beautiful and powerful golang kernel development_ Binary operation fool installation_ Construction tutorial attached
Decomposition of kubernets principle
Reprint: getting started with cache coherence
Depth first search and breadth first search of Graphs
Talk about software testing - automated testing framework
Lanqiao cup provincial training camp - commonly used STL
[golang] golang implements simple Memcache
Simply use MySQL index
高频笔试题(蔚来)
Read the triode easily. It turns out that it works like this
基于NoCode构建简历编辑器
This should be postman, the most complete interface testing tool in the whole network
How to convert word to markdown text