当前位置:网站首页>【mycat】mycat搭建读写分离
【mycat】mycat搭建读写分离
2022-07-24 05:19:00 【你怎么不笑了】
Mycat搭建读写分离
通过 Mycat 和 MySQL 的主从复制配合搭建数据库的读写分离,实现 MySQL 的 高可用性。我们将搭建:一主一从、双主双从两种读写分离模式。
1.搭建一主一从
一台主机用于处理所有写请求,一台从机负责所有读请求

1.1搭建mysql数据库主从复制
安装mysql教程:https://blog.csdn.net/sinat_33151213/article/details/101269488
需要两台服务器安装mysql,我这里安装的,mysql主机master:192.168.171.142,mysql从机slave:192.168.171.143
实际请以自己安装的环境为准
接下来就是配置mysql的主从复制了
修改主机master:192.168.171.142的mysql配置文件
vim /etc/my.cnf
直接配置
# mysql实例id,不可重复
server-id=1
# 启用二进制日志,路径为binlog日志位置
log-bin=/var/lib/mysql/binlog
# 设置需要同步的数据库
binlog-do-db=mydb1
# 需要同步多个数据库,另起一行binlog-do-db配置
# binlog-do-db=mydb2
# 设置不需要同步的数据库
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置binlog格式
binlog_format=STATEMENT

修改从机slave:192.168.171.143的mysql配置文件
vim /etc/my.cnf
#数据库实例id,不可重复
server-id=2
#启用中继日志
relay-log=/var/lib/mysql/relaylog

重启两台mysql服务器
systemctl restart mysqld
systemctl status mysqld
服务器防火墙或者端口需要开放
主机上建立slave1用户并授权
用navicat执行命令也可
# 在主机mysql里执行授权命令,用户名随意,能区分就行...
create user 'slave1'@'%' identified by 'root';
grant replication slave on *.* to 'slave1'@'%';
flush privileges;

查询主机master状态
show master status;

记下File和Position的值,之后暂时不要再操作master主机了,防止主数据服务器状态值变化
在从机上配置需要复制的主机
# 配置master
# master_host:主机ip,配置你自己的
# master_port:主机端
# master_user:一开始在主机数据库创建的用户
# master_password:创建的用户密码
# master_log_file:show master status查询到的File值
# master_log_pos:show master status查询到的Position值
change master to master_host = '192.168.171.142',
master_port=3306,
master_user='slave1',
master_password='root',
master_log_file='binlog.000001',
master_log_pos=743;

启动从机复制功能
start slave;

查看从机状态
show slave status\G;
Slave_IO_Running和Slave_SQL_Running都是YES就表示主从配置成功!

验证下
在主机master上新建数据库、数据表、数据记录
-- 在主机master操作
-- 建库语句,数据库名称是mydb1,因为在my.cnf配置文件配置的需要同步的数据库是mydb1
create database mydb1;
-- 建表语句
create table mytb1(id int, name VARCHAR(32));
-- 插入数据
insert into mytb1 values(1, 'zhangsan');


停止从机复制功能
stop slave;

在主机新增一条记录后,从机slave不会同步数据了

重启主从复制功能
start slave;
重置主从复制功能
stop slave;
reset master
后面就重新按上面的步骤配置
1.2配置Mycat读写分离
登录mycat,创建逻辑库,配置数据源
# 登录mycat,需要加ip访问
# 用户名和密码是mycat conf/users路径下配置的,不是真实mysql的
mysql -uroot -proot -P 8066 -h 192.168.171.142
# 在mycat中创建逻辑库
create database mydb1;

然后退出,进入到conf/schemas目录下,会看到新建数据库后生成的schema文件:

修改mydb1.schema.json配置下主机数据源,prototype是数据源名称

然后,使用注解的方式添加数据源
需要创建两个数据源,写数据源和读数据源
写数据源,rwSepw表示写数据源,配置信息需要修改成自己的
-- 写数据源
/*+ mycat:createDataSource{ "name":"rwSepw","url":"jdbc:mysql://192.168.171.142:3306/mydb1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"root" } */;
读数据源,rwSepr表示读数据源,配置信息需要修改成自己的
-- 读数据源
/*+ mycat:createDataSource{ "name":"rwSepr","url":"jdbc:mysql://192.168.171.143:3306/mydb1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"root" } */;
打开navicat,连上mycat,是8066的,然后复制运行,注意执行代码不要有多余的空格换行

执行成功后,查询配置数据源结果
-- /查询配置数据源结果
/*+ mycat:showDataSources{} */;

回到上面的mydb1.schema.json修改的步骤,我们配置的targetName名字是prototype,这时候会有疑惑,刚刚创建的两个rwSepr和rwSepw数据源名称都不是prototype
targetName可以是数据源名称也可以是集群名称的
只需要将rwSepr和rwSepw组成一个集群就行了,集群的名称是prototype,然后就通过mycat实现主从读写分离
-- 创建集群, 集群名称是prototype
/*! mycat:createCluster{"name":"prototype","masters":["rwSepw"],"replicas":["rwSepr"]} */

查看集群状态
-- 查看集群
/*+ mycat:showClusters{} */;

WRITE_DS:rwSepw是写数据源
READ_DS:读数据源,rwSepw也在这里是因为具有写操作,同样也具备读操作
查看集群的配置文件,conf/clusters/prototype.cluster.json
vim ../conf/clusters/prototype.cluster/json
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"rwSepw"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"rwSepr"
],
"switchType":"SWITCH"
}
readBalanceType 查询负载均衡策略
可选值:
BALANCE_ALL(默认值): 获取集群中所有数据源
BALANCE_ALL_READ: 获取集群中允许读的数据源
BALANCE_READ_WRITE: 获取集群中允许读写的数据源,但允许读的数据源优先
BALANCE_NONE: 获取集群中允许写数据源,即主节点中选择
switchType
NOT_SWITCH: 不进行主从切换
SWITCH: 进行主从切换
重启mycat,验证读写分离
./mycat restart
重启完成后,在主数据库master插入数据,不是mycat也不是从数据库slave
# 插入带系统变量的数据,这样从机同步的数据获取的是自己机器的系统变量
INSERT INTO mytb1 VALUES(2,@@hostname);

自己手动在从机同步的数据上面改也可以,只要确保两边数据不一致就行,只是为了验证读写分离,真实场景下数据肯定要一致的
在mycat的mytb1表中查询,可查询到主从数据库中的数据,mycat的库中如果没有mytb1表记得创建一个,不需要停止服务,创建就行,其他的都不用动,然后执行
# 注意,这是在Mycat中的查询
select * from mytb1;


结论:同样的语句,返回不同的name,说明是从不同的数据库查询出来的
搞定。
2.搭建双主双从
一主一从搭建成功后,主机master负责写请求,从机slave负责读请求
而双主双从就是,两台主机master,两台从机slave,一台主机master1用于处理写请求,它的从机slave1与另外一台主机master2和它的从机slave2负责所有读请求。当master1宕机后,由master2负责写请求,master1和master2互为备机,这样就有了更高的容错性。
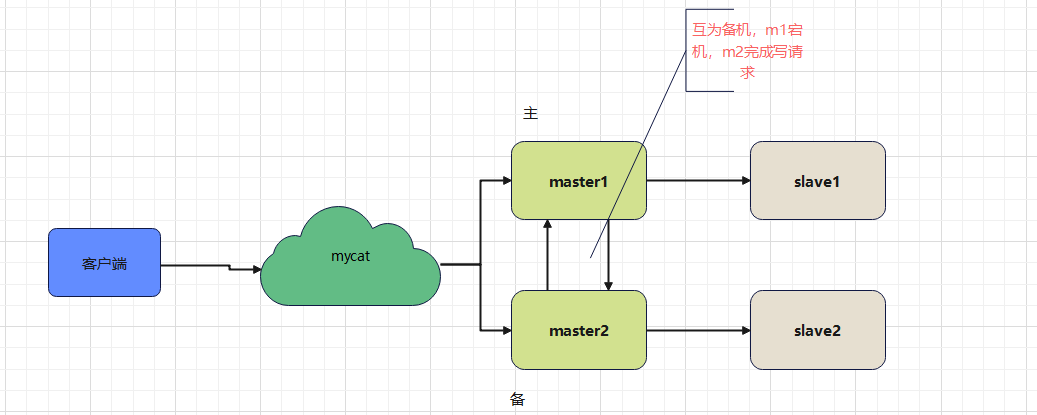
架构如图所示:需要4台服务器了
2.1搭建mysql数据库双主双从复制
自行准备好四台服务器,以自己的为准
| 编号 | 角色 | ip | 服务主机名 |
|---|---|---|---|
| 1 | master1 | 192.168.171.142 | hll1 |
| 2 | slave1 | 192.168.171.143 | hll2 |
| 3 | master2 | 192.168.171.140 | hll3 |
| 4 | slave2 | 192.168.171.142 | hll3 |
双主机配置
master1配置,修改配置文件master1主机的my.cnf文件
vim /etc/my.cnf
# 主服务器唯一id,不可重复
server-id=1
# 启用二进制日志,路径为binlog日志位置
log-bin=/var/lib/mysql/binlog
#设置不要复制的数据库(可设置多个)
#binlog-ignore-db=mysql
#binlog-ignore-db=information_schema
#设置需要复制的数据库,配置这个就好,ignore可以不配
#binlog-do-db=自己业务需要复制的数据库名称
binlog-do-db=mydb1
#设置binlog格式
binlog_format=STATEMENT
#在作为从数据库的时候,有写入操作要进行更新binlog日志文件
#就一行这个,没有=
log-slave-updates
#自增字段每次递增的值,默认是1,取值范围1~65535
#等于2是因为两台主机,他们的新增数据的id肯定要唯一不能冲突,所以自增+2后的结果是:m1的id为1357.。。 m2的id为2468.。。
auto-increment-increment=2
#表示自增字段从哪个数开始,取值范围是1~65535
auto-increment-offset=1

master2配置,修改配置文件master2主机的my.cnf文件
vim /etc/my.cnf
# 主服务器唯一id,不可重复
server-id=3
# 启用二进制日志,路径为binlog日志位置
log-bin=/var/lib/mysql/binlog
#设置不要复制的数据库(可设置多个)
#binlog-ignore-db=mysql
#binlog-ignore-db=information_schema
#设置需要复制的数据库,配置这个就好
#binlog-do-db=自己业务需要复制的数据库名称
binlog-do-db=mydb1
#设置binlog格式
binlog_format=STATEMENT
#在作为从数据库的时候,有写入操作要进行更新binlog日志文件
#就一行这个,没有=
log-slave-updates
#自增字段每次递增的值,默认是1,取值范围1~65535
#等于2是因为两台主机,他们的新增数据的id肯定要唯一不能冲突,所以自增+2后的结果是:m1的id为1357.。。 m2的id为2468.。。
auto-increment-increment=2
#表示自增字段从哪个数开始,取值范围是1~65535
auto-increment-offset=2

双从机配置
slave1配置,修改配置文件slave1主机的my.cnf文件
vim /etc/my.cnf
# 从服务器唯一id,不可重复
server-id=2
#启用中继日志
relay-log=/var/lib/mysql/relaylog

slave2配置,修改配置文件slave2主机的my.cnf文件
vim /etc/my.cnf
# 从服务器唯一id,不可重复
server-id=4
#启用中继日志
relay-log=/var/lib/mysql/relaylog

重启mysql服务
双主机、双从机重启一下,然后防火墙都关闭或者把对应的端口都开放下
systemctl restart mysqld
systemctl status mysqld
建立授权用户
同一主一从一样,前面一主一从已经建立过一个slave用户了,现在只需要在master2上面建立一个从机用户即可。如果都没创建的话,那就在master1和master2上分别创建一个从机用户。
建用户命令:
mysql -uroot -p
#在主机MySQL里执行授权命令
#在master1主机创建,已创建就忽略
create user 'slave1'@'%' identified by 'root';
grant replication slave on *.* to 'slave1'@'%';
#在master2主机创建
create user 'slave2'@'%' identified by 'root';
grant replication slave on *.* to 'slave2'@'%';
#如果创建用户提示密码问题,通过此语句执行。
alter user 'slave2'@'%' IDENTIFIED WITH mysql_native_password BY 'root';


查询master状态
在两台mysql主机执行:
show master status;
master1主机

master2主机

很重要:
#分别记录下File和Position的值
#执行完此步骤后不要再操作主服务器MYSQL,防止主服务器状态值变化
从机配置需要复制的主机
slave1复制master1,slave2复制master2
# 复制主机的命令,这个是在从机执行的
CHANGE MASTER TO MASTER_HOST='主机的IP地址',
MASTER_USER='slave', //在主机创建的用户
MASTER_PASSWORD='root', //哟过户密码
MASTER_LOG_FILE='binlog.具体数字',MASTER_LOG_POS=具体值;
slave1的复制命令
# 这个是在从机执行的
CHANGE MASTER TO MASTER_HOST='192.168.171.142',
MASTER_USER='slave1',
MASTER_PASSWORD='root',
MASTER_LOG_FILE='binlog.000009',MASTER_LOG_POS=154;
slave1的我在搭建一主一从的时候配置过了,不再重新执行截图了。
slave2的复制命令
# 这个是在从机执行的
CHANGE MASTER TO MASTER_HOST='192.168.171.140',
MASTER_USER='slave2',
MASTER_PASSWORD='root',
MASTER_LOG_FILE='binlog.000001',MASTER_LOG_POS=406;

启动从机的复制功能
#这个是在从机执行的
start slave;

执行完成后,查看从机状态
show slave status\G;


#下面两个参数都是Yes,则说明主从配置成功!
#Slave_IO_Running: Yes
#Slave_SQL_Running: Yes
自己验证下,master1、master2创建数据库,数据表,添加数据查看slave1、slave2有没有正常同步成功
两台主机master互相复制
master1复制master2,master2复制master1
master2复制命令
如果服务有操作过,需要重新查询下log_file和position
#查询master1的
show master status;
将查询的最新的结果替换给MASTER_LOG_FILE和MASTER_LOG_POS
# 在master2执行,ip等配置信息都是master1的
CHANGE MASTER TO MASTER_HOST='192.168.171.142',
MASTER_USER='slave1',
MASTER_PASSWORD='root',
MASTER_LOG_FILE='binlog.000010',MASTER_LOG_POS=1499;

master1复制命令
如果服务有操作过,需要重新查询下log_file和position
#查询master2的
show master status;
将查询的最新的结果替换给MASTER_LOG_FILE和MASTER_LOG_POS
# 在master1执行,ip等配置信息都是master2的
CHANGE MASTER TO MASTER_HOST='192.168.171.140',
MASTER_USER='slave2',
MASTER_PASSWORD='root',
MASTER_LOG_FILE='binlog.000002',MASTER_LOG_POS=344;

操作成功后,启动两天master服务器的复制功能
start slave;
show slave status\G;
#下面两个参数都是Yes,则说明配置成功!
#Slave_IO_Running: Yes
#Slave_SQL_Running: Yes
自己验证下,master1创建数据库/数据表/添加数据查看master2、slave1、slave2有没有正常同步成功
只在master1一端操作,其他三端可以同步数据,这样mysql的两主两从,两主复制搭建成功
重启主从复制功能
start slave;
重置主从复制功能
stop slave;
reset master
后面就重新按上面的步骤配置
2.2修改mycat的集群配置实现多种主从
双主双从集群角色划分
m1:主机
m2:备机,也负责读
s1,s2:从机
增加数据源
第一节中,一主一从已经添加过数据源了,现在将另外的一主一从也添加mycat数据源
同样需要创建两个数据源,写数据源和读数据源
写数据源,rwSepw2表示写数据源,配置信息需要修改成自己的
-- 写数据源
/*+ mycat:createDataSource{ "name":"rwSepw2","url":"jdbc:mysql://192.168.171.140:3306/mydb1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"root" } */;
读数据源,rwSepr2表示读数据源,配置信息需要修改成自己的
-- 读数据源
/*+ mycat:createDataSource{ "name":"rwSepr2","url":"jdbc:mysql://192.168.171.141:3306/mydb1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"root" } */;
打开navicat,连上mycat,是8066的,然后复制运行,注意执行代码不要有多余的空格换行

共四个数据源了。
修改配置文件,将新的数据源加进去
在一主一从的时候已经通过注解方式创建过集群且生成过集群文件了,所以现在只需要在集群文件把新的数据源配置进去就ok了
进入到你的mycat服务目录,编辑集群文件
vim ../conf/clusters/prototype.cluster.json

{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"rwSepw","rwSepw2"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"rwSepr","rwSepw2","rwSepr2"
],
"switchType":"SWITCH"
}
重启mycat生效
-- 查看集群状态
/*+ mycat:showClusters{} */;
3.读写分离扩展配置
(1)一主一从,无备,m是主,s是从
"clusterType":"MASTER_SLAVE",
"masters":[
"m"
],
"replicas":[
"s"
],
(2)一主一从一备,m是主,s是从备
"clusterType":"MASTER_SLAVE",
"masters":[
"m", "s"
],
"replicas":[
"s"
],
(3)一主一从一备,m是主,s是从,b是备
"clusterType":"MASTER_SLAVE",
"masters":[
"m", "b"
],
"replicas":[
"s"
],
(4)MHA,一主一从一备,m是主,s是从,b是备
"clusterType":"MHA",
"masters":[
"m", "b"
],
"replicas":[
"s"
],
(5)MGR,一主一从一备,m是主,s是从,b是备
"clusterType":"MGR",
"masters":[
"m", "b"
],
"replicas":[
"s"
],
(6)GARELA_CLUSTER,一主一从一备,m是主,s是从,b是备
"clusterType":"GARELA_CLUSTER",
"masters":[
"m", "b"
],
"replicas":[
"s"
],
边栏推荐
- Useref create dynamic reference
- 数据仓库与数仓建模
- 【百度地图API】您所使用的地图JS API版本过低,已不再维护,为保证地图基本功能 正常使用,请尽快升级到最新版地图JS API
- Tree structure + node
- Review the whole process of the 5th Polkadot Hackathon entrepreneurship competition, and uncover the secrets of the winning projects!
- 通用分页2.0
- Draw a moving teapot on the screen. The teapot first moves slowly towards the screen, becoming smaller and smaller, becoming more and more blurred; Then it grows bigger and clearer, and keeps repeatin
- 网页播放rtsp视频流
- 微信小程序map的使用
- 去中心化的底层是共识——Polkadot 混合共识机制解读
猜你喜欢

Mobile software development ISO simple wechat

haclabs: no_name(HL.ova)靶机渗透-Vulnhub

Summary of data types

Insanity:1 (insanity hosting) target penetration vulnhub

Restore UI design draft

Fusdt流动性质押挖矿开发逻辑系统原理
Mapboxgl + GeoServer configuration local map tutorial

【百度地图API】您所使用的地图JS API版本过低,已不再维护,为保证地图基本功能 正常使用,请尽快升级到最新版地图JS API

Flink Watermark机制

微信小程序返回携带参数或触发事件
随机推荐
OpenGL draws a cone on the screen, which has four faces, each of which is a triangle. Add lighting and texture effects to the cone
Flink函数(2):CheckpointedFunction
php的多选、单选结果怎么在前台显示?
自定义MVC 1.0
Flink Task、Sub-Task、task slot和parallelism
Principle of fusdt liquidity pledge mining development logic system
php+mysql导出excel文件方法
首届波卡黑客松项目「Manta Network」的进击之路
盘点波卡生态潜力项目 | 跨链特性促进多赛道繁荣
Sunset: noontide target penetration vulnhub
How to export Excel files with php+mysql
Collection = = academic waste
PyCharm设置代码模板
02 mobile terminal page adaptation
第五届 Polkadot Hackathon 创业大赛全程回顾,获胜项目揭秘!
Insanity:1 (insanity hosting) target penetration vulnhub
Canvas - rotate
The repetition detection function of PHP multi line text content and count the number of repetitions
通用分页2.0
【虚拟化】如何将虚拟机从workstation转换到esxi