当前位置:网站首页>Thinking about distributed system consensus
Thinking about distributed system consensus
2022-06-23 21:06:00 【lincoln】
The challenge of Distributed Systems
In the previous article , We analyze the business consistency technology of distributed system , Distributed transactions , Its result orientation is user oriented . But inside our system , Sometimes we also need to face higher-level consistency requirements from software architecture , such as Redis Sentry mode ,Zookeeper The election process, etc . The consistency they consider is more a problem between service nodes Consensus Of , When consensus is reached , You can take this as the guiding principle , Expand more collaborative operations .
Before studying how to reach a consensus , Let's first analyze the characteristics of distributed systems :
Concurrent: Processes on different nodes can be executed at the same time , We need a coordination mechanism to complete the tasks at all stages .Global clock: In a distributed system , It's basically hard to maintain a global clock , There is no absolute time sequence for each server .Failure effects: There is no system without faults , The overall impact on the system needs to be considered , And the fault-tolerant processing capability that the system can provide .The messaging: Due to the complex environment of the network , The communication between nodes may reach , It may also partially arrive at , It is possible to transmit... Within a known time range , It may also be delayed indefinitely , This is not necessarily .
thus it can be seen , The challenge of reaching consensus in a distributed system is Coordinate 、 Fault tolerance 、 Uncertain communication .
State replication
If we want to introduce a coordinator into a system , So it's very simple , Just introduce a stateful component , The current business phase of the system should be ensured by judging the status . A stateful component is well implemented , As long as it has persistence function , image Mysql,MongoDB. however , Considering the importance of the coordinator , We often need to ensure its high availability , To that end , We will add the replication process in the process of updating the status . For example, the updated value , Synchronize to other machines .
however , Whether all machines need to be copied in place , To complete the update process ? not always , image Mysql Synchronous replication 、 Asynchronous replication 、 Semi synchronous replication provides us with a variety of options in terms of performance and data consistency , It's just that the more efficient replication is , The less consistent the data is .
Coordinators like us update less frequently , Small amount of data , Will often use The minority is subordinate to the majority The strategy of , As long as more than half of the synchronization nodes , Then it can be considered that the writing is successful .Raft Log synchronization for ,Zookeeper That's how the message broadcast is handled . besides , In order to ensure the correctness of synchronization , And introduce The election Mechanism , Let the election come out Leader Nodes uniformly process synchronization results . When Leader When the node fails or goes offline , There will be re-election according to certain rules ( For example, the latest submission level of logs ), Ensure the normal operation of the system .
Fault handling
In the above consensus approach , It is bound to consider the impact of the fault , There are two corresponding fault types :
Breakdown: The node suddenly crashes and stops responding to other nodesByzantium failed: Nodes are not trusted , An error message will be sent to other nodes
Aim at Breakdown This type of failure , We can be like Raft, Paxos agreement , Settle... By election . But like Byzantium failed This kind of problem is more difficult to solve , Because there may be rebellious nodes , Make the whole system reach a consensus in the wrong direction , Obvious , This is not what we want . Therefore, we will see the following solutions in the blockchain :
PBFT(Practical Byzantine Fault Tolerance): Byzantine fault tolerant algorithm ( League chain / The private chain uses this algorithm )PoW(Proof of Work): Workload proof algorithm ( Bitcoin and Ethereum use this algorithm )
FLP Impossible principle
On the communication model between distributed systems , In general, it can be divided into the following two types :
- Sync : The time for the system to process messages is within the specified range , Once beyond , It is regarded as failure directly .
- asynchronous : The time for the system to process messages is uncertain , It is possible to get results , You may not get it all the time .
among , stay asynchronous Communication model , There is a famous FLP Impossible principle , namely :
Reliable on the Internet 、 But node failures are allowed ( Even if there's only one ) The minimum asynchronous model system , There is a consensus on the existence of an algorithm to solve the problem of uncertainty
FLP The impossible principle tells us , Don't waste time designing consensus algorithms for any scenario for asynchronous distributed systems . We should focus on a constrained 、 In a distributed system with termination conditions , If the algorithm we design meets the following two conditions as much as possible , Then our system will have a consensus output :
- activity : Each non fault node will eventually decide to output a value , If the node does not make a decision , Then the system will stop .
- Security : All non fault nodes will eventually output the same value , If this effect is not achieved , So consistency is hard to guarantee .
Consensus building
Different algorithms will describe the above conditions differently , In a broad sense , Consensus algorithm usually divides the following three roles :
Proposal is: Often referred to as a leader or coordinatorThe recipient: Respond to the proposal put forward by the proposerLearners': Not involved in decision making , The final value of learning decision
When the roles and responsibilities are divided , We will define a consensus algorithm through the following three steps :
The first 1 Step The election : When an external event triggers , The leader proposes the next valid output value .
The first 2 Step vote : After the non fault node receives the value proposed by the leader , Verify it , And propose it as the next valid value .
The first 3 Step decision : According to the proposed results of rms at each non fault node , Decide whether to use this value ; Otherwise, restart step 1
For the above steps , Different consensus algorithms will have some differences , For example, the definition of terms 、 Voting process 、 Determination criteria of effective value, etc .
application
The consensus of distributed system needs to be reached in unreliable 、 In an untrusted network . If the so-called byzantine fault tolerance , So our raft、zookeeper An agreement is enough , And their application scenarios are often in the intranet , So the default internal nodes are trusted . If we want to reach a consensus in an open network that contains malicious behavior , For example, blockchain , Then we have to consider the improvement of the following three situations :
- Rationalization : Participants choose the execution of the agreement according to the strategy of maximizing benefits .
- Altruistic : During execution , Be able to consider the overall interests .
- Byzantine fault tolerance : It can resist the malicious behavior of some nodes , Ensure the normal operation of the system .
summary
The process of reaching consensus on distributed systems requires activity and Security The protection of , Its consensus mechanism also needs to take Byzantine errors into account . The solution of consensus problem makes our distributed system run more robust , It is precisely because of the importance of consensus , Today's blockchain technology is extra important !
Reference resources
边栏推荐
- How to process the text of a picture into a table? Can the text in the picture be transferred to the document?
- WinDbg loads mex DLL analysis DMP file
- How to solve the problem that the ID is not displayed when easycvr edits the national standard channel?
- JS namespace
- The element of display:none cannot get offsetwidth and offsetHeight
- Which is better for securities companies? I don't understand. Is it safe to open an account online?
- The background receives the post data passed by the fetch
- 网上证券开户安全还是去营业部安全
- [golang] quick review guide quickreview (III) - Map
- Model selection and optimization
猜你喜欢
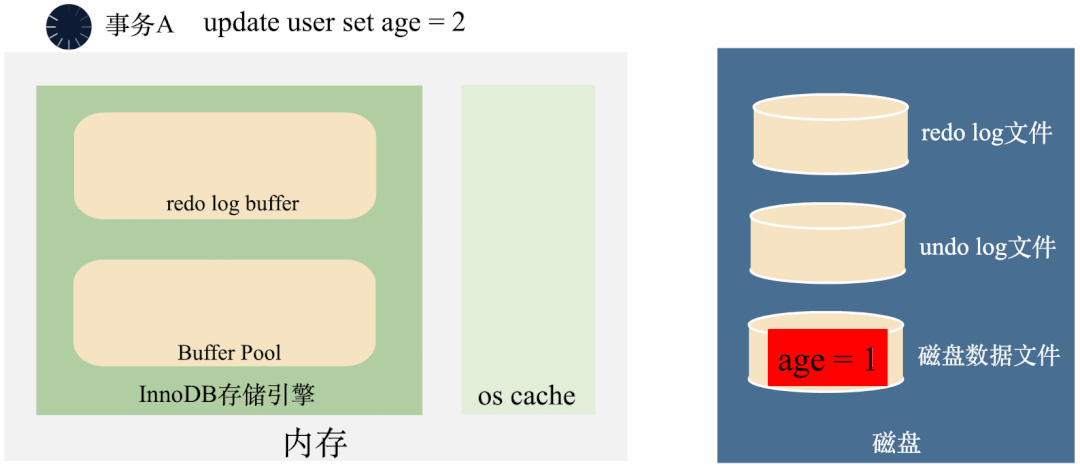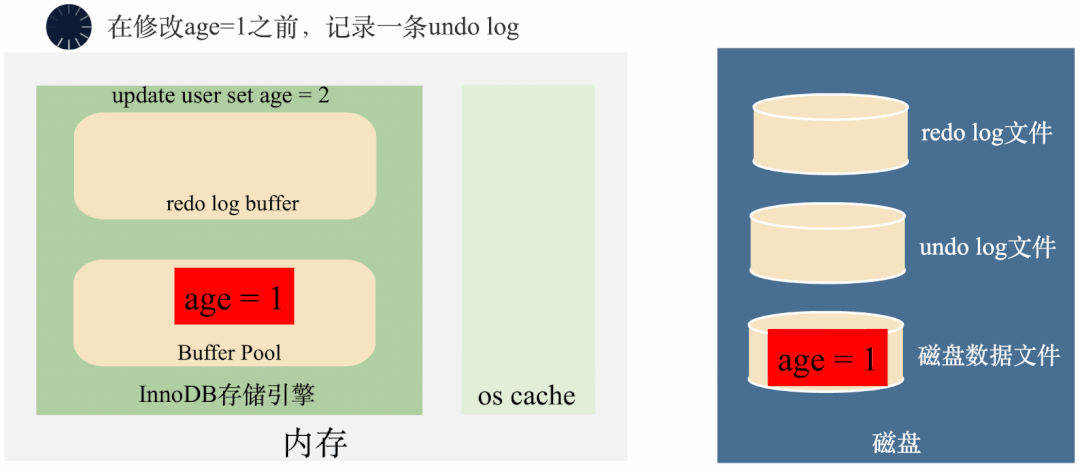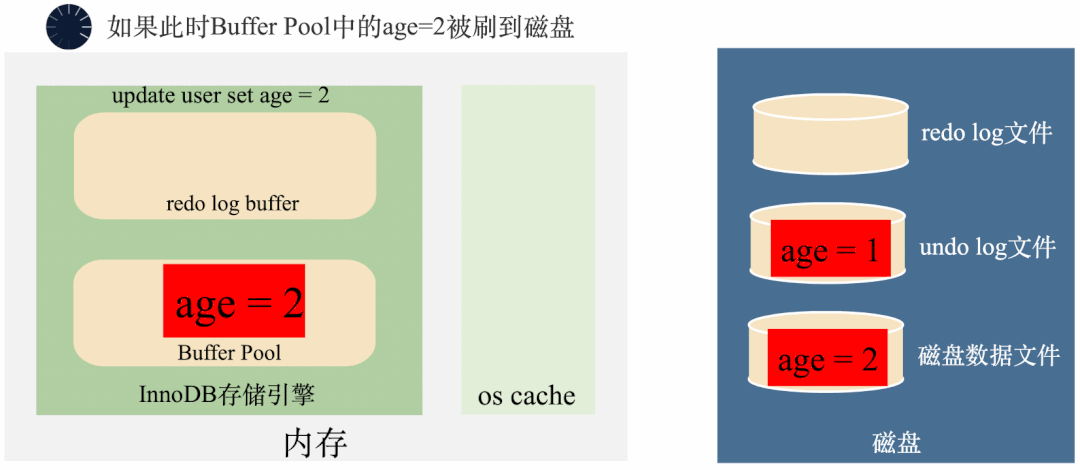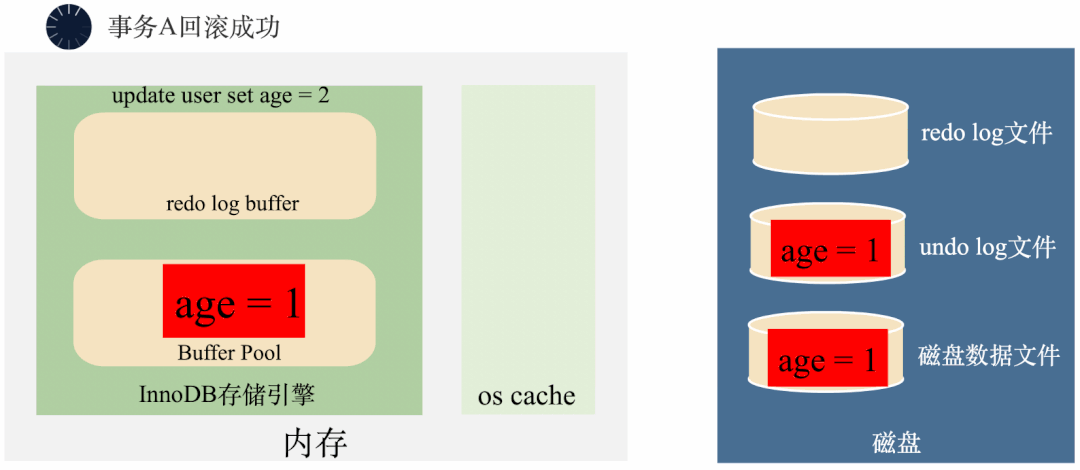
3000 frame animation illustrating why MySQL needs binlog, redo log and undo log
Application of JDBC in performance test

Applet development framework recommendation
Implementing MySQL fuzzy search with node and express

JS advanced programming version 4: generator learning

Yaokui tower in Fengjie, Chongqing, after its completion, will be the safety tower for Sichuan river shipping with five local scholars in the company


随机推荐
Bypass memory integrity check
ASP. Net MVC and asp Net web form
How PostgreSQL quickly locate blocking SQL
CPS 22 January additional incentive rules
[golang] some questions to strengthen slice
[golang] quick review guide quickreview (IV) -- functions
Yaokui tower in Fengjie, Chongqing, after its completion, will be the safety tower for Sichuan river shipping with five local scholars in the company
How is the picture mosaic clear? What is mosaic for?
【Golang】怎么实现Go程序的实时热更新
Process injection
数字电路概述
. NET Core . NET Framework
Setinterval stop
How to define an "enumeration" type in JS
This article introduces you to the necessity of database connection pooling
Cobalt Strike Spawn & Tunnel
Summary of multiple methods for obtaining the last element of JS array
Strokeit- the joy of one handed fishing you can't imagine
Using asp Net core MVC framework for building web applications
How to Net project migration to NET Core