当前位置:网站首页>Li Mu D2L (V) -- multilayer perceptron
Li Mu D2L (V) -- multilayer perceptron
2022-07-26 09:09:00 【madkeyboard】
List of articles
One 、 perceptron
Concept
A given input x, The weight w, And offset b, The output of the sensor is as follows . The output of perceptron is a binary problem , The output of linear regression is a real number ,Softmax If there is n A class will output n Elements , It is a multi classification problem .
The perceptron cannot fit XOR problem , Because it can only produce linear split surfaces

Training perceptron
Its solution algorithm is equivalent to using a batch size of 1 The gradient of .

Convergence theorem

Two 、 Multilayer perceptron
Why is it called multilayer ? When the goal we want to achieve cannot be achieved at one time , Just learn a simple function first , Learn another simple function , Finally, another function is used to combine the two functions .

Single hidden layer - Single category
Input is n Dimension vector , The hidden layer is m x n Matrix , Offset is long bit m Vector . The output layer is also a long bit m Vector , The offset is a scalar .

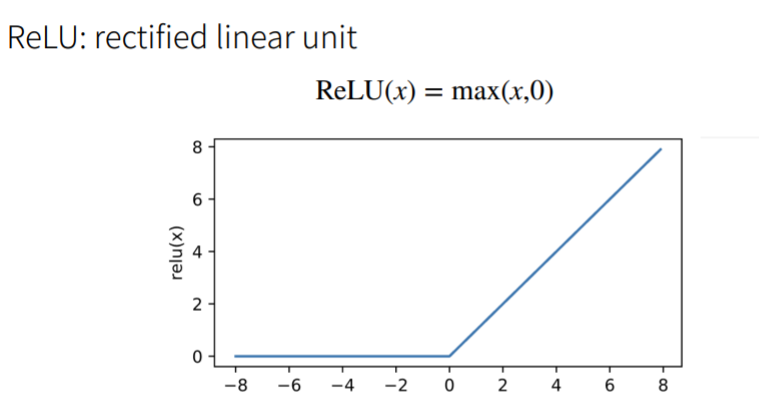
Why do we need a nonlinear activation function ? Suppose the activation function is itself , namely σ(x) = x, You can see the output o Of w2T W1 x + b’ It is still a linear function , Then it is equivalent to a single-layer perceptron .

Sigmoid Activation function

Tanh Activation function

ReLU Activation function
Multilevel classification
Input and hidden layers are the same as single classification , The difference is that the output layer is a m x k Matrix , The offset is a length of k Vector .

3、 ... and 、 Multi layer perceptron code starts from scratch
import torch
from torch import nn
from d2l import torch as d2l
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 1 Implement a multi-layer perceptron with a single hidden layer , contain 256 Hidden units
num_inputs, num_outputs = 784, 10
num_hiddens = 256
w1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01) # randn It is normally distributed in (0,1) The reason why I multiply by 0.01 Is to limit the scope to (0,0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
w2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [w1, b1, w2, b2]
# 2 Realization RELU Activation function
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
# 3 Implementation model
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ w1 + b1) # @ Abbreviation for matrix multiplication
return (H @ w2 + b2)
# 4 Loss
loss = nn.CrossEntropyLoss(reduction='none')
# 5 Training process
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
d2l.plt.show()
From the results, we can see that it is the same as last time sofmax comparison , its loss To reduce the , But the accuracy has not improved .

Four 、 Simple implementation
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
边栏推荐
- PAT 甲级 A1034 Head of a Gang
- Pat grade a a1013 battle over cities
- Canal 的学习笔记
- Database operation topic 2
- (1) CTS tradefed test framework environment construction
- 围棋智能机器人阿法狗,阿尔法狗机器人围棋
- Review notes of Microcomputer Principles -- zoufengxing
- 【LeetCode数据库1050】合作过至少三次的演员和导演(简单题)
- Pat grade a A1034 head of a gang
- jvm命令归纳
猜你喜欢
谷粒学院的全部学习源码

【LeetCode数据库1050】合作过至少三次的演员和导演(简单题)

Flask project learning (I) -- sayhello
公告 | FISCO BCOS v3.0-rc4发布,新增Max版,可支撑海量交易上链

Dynamic SQL and exceptions of pl/sql

JS file import of node

Database operation topic 2

Matlab 绘制阴影误差图

NFT与数字藏品到底有何区别?

Study notes of automatic control principle -- correction and synthesis of automatic control system
随机推荐
MySQL 强化知识点
Day06 homework - skill question 7
JS file import of node
Summary of common activation functions for deep learning
数据库操作 题目二
论文笔记: 知识图谱 KGAT (未完暂存)
谷粒学院的全部学习源码
JS - DataTables 关于每页显示数的控制
“could not build the server_names_hash, you should increase server_names_hash_bucket_size: 32” 问题处理
Where are the laravel framework log files stored? How to use it?
187. Repeated DNA sequence
力扣刷题,三数之和
Form form
“No input file specified “问题的处理
Espressif plays with the compilation environment
Which of count (*), count (primary key ID), count (field) and count (1) in MySQL is more efficient? "Suggested collection"
Canal 的学习笔记
NTT (fast number theory transformation) polynomial inverse 1500 word analysis
day06 作业--技能题1
209. Subarray with the smallest length