当前位置:网站首页>Edata base, a secondary development project based on spark packaging, is introduced
Edata base, a secondary development project based on spark packaging, is introduced
2022-07-27 10:40:00 【sword_ csdn】
Catalog
Introduce
edata-base Is based on Spark Big data secondary development library , It encapsulates the Spark And other commonly used intermediate methods , Make based on Spark The development of is simpler .
Source warehouse address :https://gitee.com/alan-sword/edata-base
Project introduction

edata-base Medium POM
edata-base Specifies the Spark API With other middleware API Version of , Customize Spark The project can quote itself ,edata-base-component This parent project is referenced .
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.edata.bigdata</groupId>
<artifactId>edata-base</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<scala.version>2.11</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.3</spark.version>
<hadoop.version>3.1.2</hadoop.version>
<posgresql.version>42.1.1</posgresql.version>
<nebula.version>2.6.1</nebula.version>
<flink.version>1.14.3</flink.version>
<zookeeper.version>3.6.1</zookeeper.version>
</properties>
<modules>
<module>edata-base-component</module>
<module>edata-bigdata-test</module>
</modules>
<dependencies>
<!--Postgresql-->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.3.1</version>
</dependency>
<!--mongodb-->
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_${scala.version}</artifactId>
<version>2.4.3</version>
</dependency>
<!--Spark-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!--ZooKeeper-->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>${zookeeper.version}</version>
</dependency>
</dependencies>
<build>
<!-- <sourceDirectory>src/main/scala</sourceDirectory>-->
<!-- <testSourceDirectory>src/test/scala</testSourceDirectory>-->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- <plugin>-->
<!-- <groupId>org.apache.maven.plugins</groupId>-->
<!-- <artifactId>maven-surefire-plugin</artifactId>-->
<!-- <version>2.19</version>-->
<!-- <configuration>-->
<!-- <skip>true</skip>-->
<!-- </configuration>-->
<!-- </plugin>-->
</plugins>
</build>
</project>
edata-base-component Use in custom projects
We can first take a general look at the custom project edata-base-test How to use edata-base-component Of , First of all POM file
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>edata-base</artifactId>
<groupId>com.edata.bigdata</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>edata-bigdata-test</artifactId>
<modelVersion>4.0.0</modelVersion>
<dependencies>
<dependency>
<groupId>com.edata.bigdata</groupId>
<artifactId>edata-base-component</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
</project>
As shown above ,edata-base-test Refer to the edata-base-component My bag . You can use related libraries as shown below .
package com.edata.bigdata.viewmain
import com.edata.bigdata.bean.MyClass
import com.edata.bigdata.mongo.{
SparkMongoConnector, SparkMongoImpl}
object testing {
def main(args: Array[String]): Unit = {
// Create a connector
val connector:SparkMongoConnector = new SparkMongoConnector()
connector.appname="SparkMongoTesting"
connector.master = "local[*]"
connector.ipport = "192.168.36.141:27017"
connector.database = "spark"
connector.collection = "collection"
connector.username = "admin"
connector.password = "123456"
//connector.uri = "mongodb://admin:[email protected]:27017/spark.collection?authSource=admin"
// establish Spark-mongo Data interaction examples , Assign connector
val smi = new SparkMongoImpl[MyClass]
smi.connector = connector
val data = smi.find()
data.first()
smi.save(data)
}
}
Custom projects are in use edata-base-component when , Only two steps are needed
(1) establish Spark Connector with other middleware (connector) example .
(2) establish Spark Interface with other intermediate instances , During the creation process, the user-defined case class( The code above is MyClass), And assign the connector instance to the interface instance .
edata-base-component The module division of
As shown in the figure below 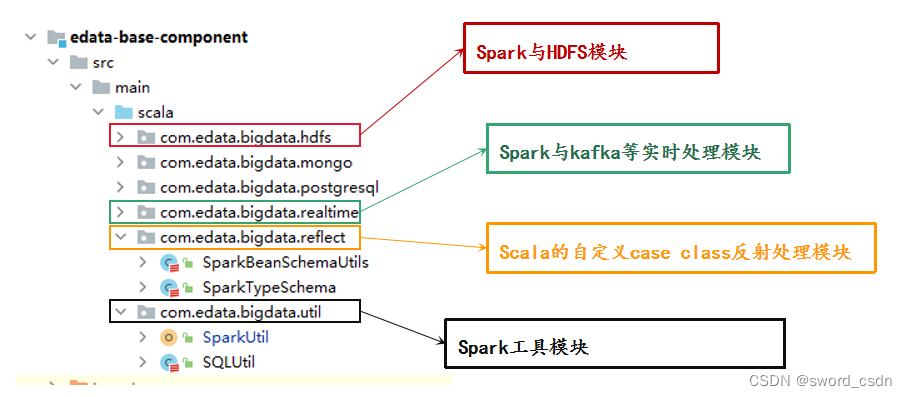
edata-base-component according to Spark Different partition modules in interaction with mainstream middleware , for example hdfs,mongodb,postgresql etc. , There are also some tool classes , And for customization case class Reflection conversion . Make based on edata-base-component Developed Spark The program can automatically User defined case class convert to DataFrame Medium Schema.
The use of Engineering
take edata-base-component The project is packaged into Jar, And quote in your own custom project ,POM The documents are as follows
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>edata-base</artifactId>
<groupId>com.edata.bigdata</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>edata-bigdata-test</artifactId>
<modelVersion>4.0.0</modelVersion>
<dependencies>
<dependency>
<groupId>com.edata.bigdata</groupId>
<artifactId>edata-base-component</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
</project>
Overall , Can be based on edata-base-component The code of is divided into two parts , Create a connector , as well as call API.
val connector:KafkaComsumeConnector = new KafkaComsumeConnector()
connector.appname = "SparkKafkaComsumerTesting"
connector.master = "local[*]"
connector.bootstraps = "localhost:9092"
connector.topic = "topicA"
connector.group_id = "direct"
val ski = new SparkKafkaImpl[String,String]
ski.comsumeConnector = connector
ski.createDirectStream()
ski.stream.foreachRDD(rdd=>{
rdd.foreach(println)
val kvRDD = rdd.map(record=>(record.key,record.value))
kvRDD.foreach(println)
})
ski.start()

边栏推荐
- Apache cannot start in phpstudy
- TDengine 助力西门子轻量级数字化解决方案 SIMICAS 简化数据处理流程
- kgdb调试内核无法执行断点及kdb-22:Permisson denied
- [Linux] install MySQL
- JSP自定义标签之自定义分页01
- Samba server
- [Linux] install redis
- Matlab/simulink sample sharing for solving differential equations
- window平台下本地连接远程服务器数据库(一)
- Local connection to remote server database under Windows platform (I)
猜你喜欢

简单几步教您实现为工业树莓派共享网络
Analysis of heterogeneous computing technology

WEB服务如何平滑的上下线
A few simple steps to realize the sharing network for industrial raspberry pie

Li Kou brush question 02 (sum of three numbers + sum of maximum subsequence + nearest common ancestor of binary tree)

游戏玩家问题

阿里邮箱web端登录转圈的处理

Matlab low-level source code realizes the median filtering of the image (used to eliminate some miscellaneous points on the image)
window平台下本地连接远程服务器数据库(一)
Alibaba mailbox web login turn processing
随机推荐
Alibaba mailbox web login turn processing
Data types and variables
hugo学习笔记
JSP自定义标签之自定义分页01
Matlab create text cloud
Distributed block device replication: client
Establishment of NFS server
【精选】如何完美的写 PHP 代码的呢?
让人深思:句法真的重要吗?邱锡鹏组提出一种基于Aspect的情感分析的强大基线...
Warning: remote head references to nonexistent ref, unable to checkout error messages
Understanding and code implementation of Se (sequence and exception) module
程序的翻译和执行,从编辑、预处理、编译、汇编、链接到执行
Local connection to remote server database under Windows platform (I)
Project team summer vacation summary 01
文档智能多模态预训练模型LayoutLMv3:兼具通用性与优越性
Shardingproxy sub database and table actual combat and comparison of similar products
A brief introduction to R language pipeline symbols (% >%) and placeholders (.)
warning package. Json: no license field error
MySQL 索引、事务与存储引擎
Mail server