当前位置:网站首页>Naacl2022: (code practice) good visual guidance promotes better feature extraction, multimodal named entity recognition (with source code download)
Naacl2022: (code practice) good visual guidance promotes better feature extraction, multimodal named entity recognition (with source code download)
2022-06-26 14:37:00 【Computer Vision Research Institute】
Pay attention to the parallel stars
Never get lost
Institute of computer vision



official account ID|ComputerVisionGzq
Study Group | Scan the code to get the join mode on the homepage
Address of thesis :https://arxiv.org/pdf/2205.03521.pdf
Code address : https://github.com/zjunlp/HVPNeT
Computer Vision Institute column
author :Edison_G
Multimodal named entity recognition and relation extraction (MNER and MRE) It is a basic and key branch of information extraction .
1
Generalization
Multimodal named entity recognition and relation extraction (MNER and MRE) It is a basic and key branch of information extraction . However , When the text contains unrelated object images , The existing MNER and MRE Methods are often affected by error sensitivity .

To solve these problems , Some researchers have proposed a novel Hierarchical visual prefix fusion network (HVPNeT), For visual enhancement of entity and relationship extraction , Designed to achieve more efficient and powerful performance .
say concretely , Treat visual representations as pluggable visual prefixes , Expressed in text to guide error insensitive prediction decisions . Furthermore, a dynamic gated aggregation strategy is proposed , To achieve hierarchical multi-scale visual features as a fusion of visual prefix . A large number of experiments on three benchmark data sets have proved the effectiveness of the new method , And achieve the most advanced performance .
2
New framework
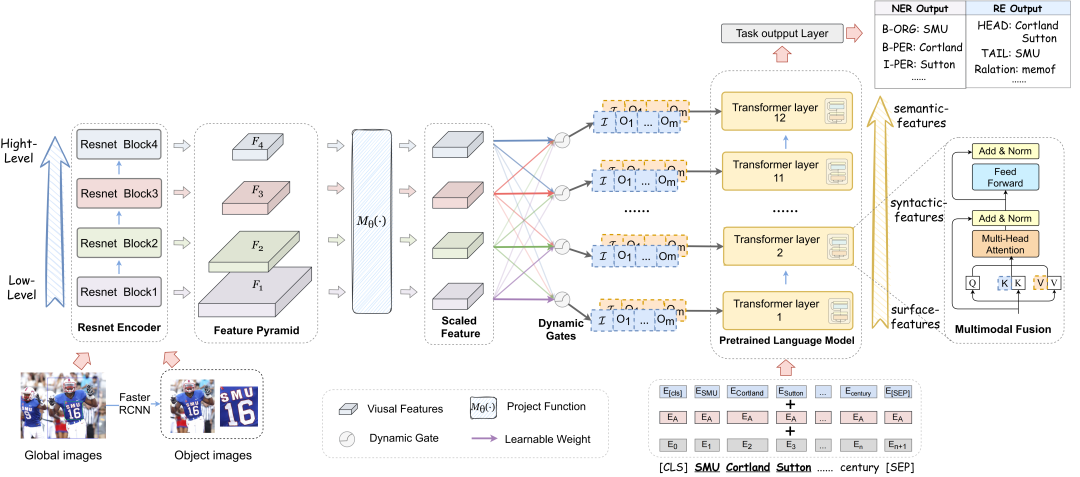
Collection of Pyramidal Visual Feature
One side , Images associated with sentences maintain multiple visual objects related to entities in sentences , It further provides more semantic knowledge to assist in information extraction . On the other hand , Global image features may express abstract concepts , Play the role of weak learning signal . therefore , Multiple visual cues are collected for multimodal entity and relationship extraction , It includes the area image as important information , Complemented by the global image .
Dynamic Gated Aggregation
Although objects of different sizes can have appropriate feature representation at corresponding scales , But decide which part of the visual backbone is Transformer It is not easy to assign visual prefixes to each layer in the . To meet this challenge , The researchers suggest building a routing space with dense connections , The hierarchical multi-scale visual features are connected with each transformer layer .
Dynamic Gate Module
Routine processing through the dynamic door module , It can be seen as a process of path decision-making . The motive of the dynamic gate is to predict a normalized vector , It indicates the degree to which the visual features of each block are executed .

Aggregated Hierarchical Feature
Based on the above dynamic door g(l), The final aggregated hierarchical visual features can be derived Vgated, To match Transformer No l layer :

Visual Prefix-guided Fusion
Hierarchical multi-scale image features are used as visual prefixes , And in BERT The visual prefix sequence is added to the text sequence in each self attention layer of the .
The hierarchical multi-scale visual feature is used as the visual prefix of each fusion layer , And perform multimodal attention in turn to update all text states . In this way , The final text state encodes both context and cross modal semantic information . This helps to reduce the error sensitivity of unrelated object elements .
3
experiment


4
Code practice
To run the codes, you need to install the requirements:
pip install -r requirements.txtData Collection:
The datasets that we used in our experiments are as follows:
Twitter2015 & Twitter2017
The text data follows the conll format. You can download the Twitter2015 data via this link and download the Twitter2017 data via this link. Please place them in
data/NER_data.You can also put them anywhere and modify the path configuration in
run.pyMNER
The MRE dataset comes from MEGA and you can download the MRE dataset with detected visual objects using folloing
command:
cd data
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gz
mv data RE_dataData Preprocess:
HMNeT
|-- data # conll2003, mit-movie, mit-restaurant and atis
| |-- NER_data
| | |-- twitter2015 # text data
| | | |-- train.txt
| | | |-- valid.txt
| | | |-- test.txt
| | | |-- twitter2015_train_dict.pth # {full-image-[object-image]}
| | | |-- ...
| | |-- twitter2015_images # full image data
| | |-- twitter2015_aux_images # object image data
| | |-- twitter2017
| | |-- twitter2017_images
| |-- RE_data
| | |-- ...
|-- models # models
| |-- bert_model.py
| |-- modeling_bert.py
|-- modules
| |-- metrics.py # metric
| |-- train.py # trainer
|-- processor
| |-- dataset.py # processor, dataset
|-- logs # code logs
|-- run.py # main
|-- run_ner_task.sh
|-- run_re_task.shTrain:
NER Task
The data path and GPU related configuration are in the run.py. To train ner model, run this script.
bash run_twitter15.sh
bash run_twitter17.shcheckpoints can be download via Twitter15_ckpt, Twitter17_ckpt.
RE Task
To train re model, run this script.
bash run_re_task.shcheckpoints can be download via re_ckpt
Test:
NER Task
To test ner model, you can download the model chekpoints we provide via Twitter15_ckpt, Twitter17_ckpt or use your own tained model and set load_path to the model path, then run following script:
python -u run.py \
--dataset_name="twitter15/twitter17" \
--bert_name="bert-base-uncased" \
--seed=1234 \
--only_test \
--max_seq=80 \
--use_prompt \
--prompt_len=4 \
--sample_ratio=1.0 \
--load_path='your_ner_ckpt_path'RE Task
To test re model, you can download the model chekpoints we provide via re_ckpt or use your own tained model and set load_path to the model path, then run following script:
python -u run.py \
--dataset_name="MRE" \
--bert_name="bert-base-uncased" \
--seed=1234 \
--only_test \
--max_seq=80 \
--use_prompt \
--prompt_len=4 \
--sample_ratio=1.0 \
--load_path='your_re_ckpt_path'THE END
Please contact the official account for authorization.

The learning group of computer vision research institute is waiting for you to join !
Institute of computer vision Mainly involves Deep learning field , It's mainly about Face detection 、 Face recognition , Multi target detection 、 Target tracking 、 Image segmentation, etc Research direction . research institute Next, we will continue to share the latest papers, algorithms and new frameworks , The difference of our reform this time is , We need to focus on ” Research “. After that, we will share the practice process for the corresponding fields , Let's really understand Get rid of the theory The real scene of , Develop the habit of hands-on programming and brain thinking !
Sweep code Focus on
Institute of computer vision
official account ID|ComputerVisionGzq
Study Group | Scan the code to get the join mode on the homepage
Previous recommendation
边栏推荐
- Summary of decimal point of amount and price at work and pit
- Research on balloon problem
- Flex & Bison 开始
- H5关闭当前页面,包括微信浏览器(附源码)
- SwiftUI找回丢失的列表视图(List)动画
- 方程推导:二阶有源带通滤波器设计!(下载:教程+原理图+视频+代码)
- Usage of unique function
- How to convert data in cell cell into data in matrix
- Hard (magnetic) disk (II)
- Sword finger offer 06.24.35 Linked list
猜你喜欢

C language | Consortium

Related knowledge of libsvm support vector machine

Build your own PE manually from winpe of ADK

FreeFileSync 文件夹比较与同步软件

GDAL multiband synthesis tool

Electron

Leaflet load day map

从Celsius到三箭:加密百亿巨头们的多米诺,史诗级流动性的枯竭

One article of the quantification framework backtrader read observer

'coach, I want to play basketball!'—— AI Learning Series booklet for system students
随机推荐
datasets Dataset类(2)
NAACL2022:(代码实践)好的视觉引导促进更好的特征提取,多模态命名实体识别(附源代码下载)...
Intellij IDEA--格式化SQL文件的方法
ThreadLocal巨坑!内存泄露只是小儿科...
GDAL multiband synthesis tool
Experience sharing of mathematical modeling: comparison between China and USA / reference for topic selection / common skills
fileinput.js php,fileinput
ArcGIS batch export layer script
Error when redis is started: could not create server TCP listening socket *: 6379: bind: address already in use - solution
Codeforces Round #765 (Div. 2) D. Binary Spiders
Sword finger offer 18.22.25.52 Double pointer (simple)
9項規定6個嚴禁!教育部、應急管理部聯合印發《校外培訓機構消防安全管理九項規定》
Difference between classification and regression
Introduction to granular computing
Why is there always a space (63 or 2048 sectors) in front of the first partition when partitioning a disk
Recent important news
Question bank and answers of the latest Guizhou construction eight (Mechanics) simulated examination in 2022
'coach, I want to play basketball!'—— AI Learning Series booklet for system students
FreeFileSync 文件夹比较与同步软件
Introduction to basic knowledge of C language (Daquan) [suggestions collection]