当前位置:网站首页>Virtual file system
Virtual file system
2022-06-24 06:47:00 【51CTO】
I found the study notes of several years ago ; Attached today
Virtual file system (Virtual File System, abbreviation VFS) yes Linux One of the subsystems of the kernel , It provides a unified interface for user programs to operate files and file systems , Shield the differences and operation details of different file systems . With the help of VFS You can use it directly open()、read()、write() Such a system call operation file , Without considering the specific file system and the actual storage medium .
VFS The implied thoughts are mainly : Introduce a common file model , This model can represent all the supported files ;VFS Provides an abstraction for the underlying layer, that is 1、 Provides a minimal generic model , Make the function of this model the minimum set of all file systems . 2、 Provide a common model as large as possible , Make this model a collection of all file system functions .
The common file model consists of the following modules :
Super block object Store information about the installed file system
Inode object General information for storing specific documents
File object Store information about the interaction between the open file and the process .
Directory entry object Store directory entries ( That is, the specific name of the file ) Information about connecting to the corresponding file .

Recently used directory entry objects are stored in the so-called directory entry cache disk cache , To speed up the conversion process from the file name to the inode of the last path component .
Disk caching is a software mechanism ; Allows the kernel to save some information that originally existed on disk in RAM in , So that we can quickly access these data ;
VFS A layer between an application and a concrete file , However, in some cases, some operations can be performed by VFS Do it yourself , There is no need to call the underlying function file_operation; such as close When a file is already open ,bing
There is no need to involve the corresponding files on the disk , It only needs VFS Release the corresponding file object .
VFS data structure :
Super block object :


struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type;
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
struct mutex s_lock;
int s_count;
atomic_t s_active;
#ifdef CONFIG_SECURITY
void *s_security;
#endif
const struct xattr_handler **s_xattr;
struct list_head s_inodes; /* all inodes */
struct hlist_bl_head s_anon; /* anonymous dentries for (nfs) exporting */
#ifdef CONFIG_SMP
struct list_head __percpu *s_files;
#else
struct list_head s_files;
#endif
struct list_head s_mounts; /* list of mounts; _not_ for fs use */
/* s_dentry_lru, s_nr_dentry_unused protected by dcache.c lru locks */
struct list_head s_dentry_lru; /* unused dentry lru */
int s_nr_dentry_unused; /* # of dentry on lru */
/* s_inode_lru_lock protects s_inode_lru and s_nr_inodes_unused */
spinlock_t s_inode_lru_lock ____cacheline_aligned_in_smp;
struct list_head s_inode_lru; /* unused inode lru */
int s_nr_inodes_unused; /* # of inodes on lru */
struct block_device *s_bdev;
struct backing_dev_info *s_bdi;
struct mtd_info *s_mtd;
struct hlist_node s_instances;
struct quota_info s_dquot; /* Diskquota specific options */
struct sb_writers s_writers;
char s_id[32]; /* Informational name */
u8 s_uuid[16]; /* UUID */
void *s_fs_info; /* Filesystem private info */
unsigned int s_max_links;
fmode_t s_mode;
/* Granularity of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
char *s_subtype;
/*
* Saved mount options for lazy filesystems using
* generic_show_options()
*/
char __rcu *s_options;
const struct dentry_operations *s_d_op; /* default d_op for dentries */
/*
* Saved pool identifier for cleancache (-1 means none)
*/
int cleancache_poolid;
struct shrinker s_shrink; /* per-sb shrinker handle */
/* Number of inodes with nlink == 0 but still referenced */
atomic_long_t s_remove_count;
/* Being remounted read-only */
int s_readonly_remount;
};
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
View Code
All super fast objects are linked together in the form of a two-way circular linked list . The first element in the linked list uses super_blocks Express ,sb_lock Spinlocks protect linked lists from simultaneous access by multiple processors .
Namespace :
Install the normal file system :
mount system call :
sys_mount The function analysis is as follows ;
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name,
char __user *, type, unsigned long, flags, void __user *, data)
{
int ret;
char *kernel_type;
char *kernel_dir;
char *kernel_dev;
unsigned long data_page;
ret = copy_mount_string(type, &kernel_type);
if (ret < 0)
goto out_type;
kernel_dir = getname(dir_name);
if (IS_ERR(kernel_dir)) {
ret = PTR_ERR(kernel_dir);
goto out_dir;
}
ret = copy_mount_string(dev_name, &kernel_dev);
if (ret < 0)
goto out_dev;
ret = copy_mount_options(data, &data_page);
if (ret < 0)
goto out_data;
ret = do_mount(kernel_dev, kernel_dir, kernel_type, flags,
(void *) data_page);
free_page(data_page);
out_data:
kfree(kernel_dev);
out_dev:
putname(kernel_dir);
out_dir:
kfree(kernel_type);
out_type:
return ret;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
From the above code It can be seen that :1、 Set the user status parameter copy To kernel state ;2、 call do_mount() function ;
Why does it exist copy User parameter to kernel address ? Why and why copy_from_user() Equal function exists for the same reason .
because : copy_from_user The purpose of the function is to copy data from user space to kernel space , Failure returns no Number of bytes copied , Successfully returns 0. This function covers a lot of knowledge about the kernel , For example, the kernel makes errors about exceptions To deal with . Copy from user space You have to be very careful when putting data into the kernel , If the user space data address is an illegal address 、
Out of user space , perhaps Those addresses have not been mapped to , Can have a big impact on the kernel , Such as oops, Or be made Impact on system safety . therefore copy_from_user The function is more than just copying data from user space , It also Do some pointer checking and deal with these The way of the problem
Convertible bond from http://blog.chinaunix.net/uid-23769728-id-3189280.html
Recently, it seems that someone asked me why I use copy_from_user The problem of this kind of function , Can't the kernel use user state pointers ? The man did an experiment himself , no need copy_from_user, Instead, you use user state pointers directly in the kernel , The program works well , Nothing . So why should the kernel provide such functions ?
I think some people on the Internet say that the user state pointer has no meaning in the kernel , It is as meaningless as the kernel pointer in user mode . This is not true , With x86 Come on , The page table of contents is placed in CR3 Medium , This register There are no kernel user states , In other words, a user mode process enters the kernel mode through system calls ,task_struct The structure of the cr3 It's all the same ,
No page table of contents changes raw . So it makes sense to use the pointer passed by the user process in kernel mode , And in user mode, the pointer of the kernel is also meaningful , Just because the permission is not enough , An exception occurs when a user process uses a kernel pointer .
Go back to the topic above , Since the kernel can use pointers passed by user processes , Then why not use memcpy Well ? Most of the time memcpy replace copy_from_user All are OK Of , In fact, there is no MMU On the system of ,copy_from_user Namely memcpy. But why is there MMU Not so Well , Use copy_from_user Except for that access_ok Beyond the inspection ,
The first half of its implementation is memcpy, There are two more in the back section. This must be Start with the missing page exception provided by the kernel , and copy_from_user It is used to deal with the situation that the virtual address pointed to by the user state pointer is not mapped to the actual physical memory , This phenomenon is common among users Space is not a big deal , Page missing exceptions will automatically commit physical memory , After that, the abnormal instruction runs normally ,
As if nothing had happened . But it's not the same in the kernel , The kernel needs to explicitly fix this Exceptions , The idea behind it is : The kernel's access to virtual address spaces that do not submit physical addresses cannot be as casual as user processes , The kernel has to show its attitude -- Don't try to do bad things , I'm staring at you . Is this What do you mean . therefore copy_from_user and memcpy The difference is that there are two more section,
So for the exception of missing pages ,copy_from_user It can be repaired just , however memcpy no way .
The pointer passed from the user space is in the virtual address space , The virtual address space it points to is probably not really mapped to the actual physical page . But what can this be ? Exceptions caused by missing pages are transparently fixed by the kernel ( Submit a new physical page for the address space of the missing page ), Instructions that access the missing page will continue to run as if nothing had happened . But this is just the abnormal behavior of missing pages in user space ,
In kernel space, this is due to a fix that must be displayed , This is determined by the design pattern of the missing page exception handler provided by the kernel , The thought behind it : In kernel state , If the program attempts to access a user space address that has not yet submitted a physical page , The kernel must be vigilant about this and not as imperceptible as user space .
If the kernel accesses a space that has not yet been submitted to a physical page , Page missing exception will be generated , The kernel calls do_page_fault, Because the exception occurs in kernel space ,do_page_fault Will call search_exception_tables stay “ __ex_table” Find the repair instruction for the exception instruction in , stay __arch_copy_from_user Functions are often used USER macro , This macro defines “__ex_table”section.
linux/include/asm-arm/assembler.h
#define USER(x...) \
9999: x; \
.section __ex_table,"a"; \
.align 3; \
.long 9999b,9001f; \
.previous
This definition contains the following data ;
.long 9999b,9001f;
among 9999b Corresponding label 9999 Instructions at ,9001f yes 9001 Instructions at , yes 9999b Repair instructions for instructions at . such , When label 9999 Page missing exception occurs at , The system will call do_page_fault Submit physical pages , Then jump to 9001 Carry on .
If not used in the driver copy_from_user While using memcpy Instead of , What will happen to the above situation ? When label 9999 Page missing exception occurs , The system is in “__ex_table”section The repair address will never be found , because memcpy Didn't like copy_from_user That defines a “__ex_table”section, here do_page_fault Will pass through no_context Function generation Oops.
It is very likely that you will see information similar to the following :
Unable to handle kernel NULL pointer dereference at virtual address 00000fe0
All in order to ensure the safety of device drivers , You should use copy_from_user Function instead of memcpy.
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
so malloc Allocate virtual space first , The physical address is mapped only when it is used . This just meets our requirements , It didn't turn out to be Ideal , I don't know this malloc Is the kernel similar copy-on-write Such a big feature , All in all memcpy No abnormality is reported for this condition . Then just come Ruthless , Directly estimate the virtual address of a user space that may not have been mapped ,
Drivers passed to kernel space , So the question came :memcpy It happened. oops,copy_from_user Up and running .
It seems that this is the difference between the two , as for access_ok, Anyone who has read the source code knows that it is just to verify the address range , At first, I thought this function would operate on the page directory table , Not at all .
- 1.
- 2.
- 3.
/*
* Flags is a 32-bit value that allows up to 31 non-fs dependent flags to
* be given to the mount() call (ie: read-only, no-dev, no-suid etc).
*
* data is a (void *) that can point to any structure up to
* PAGE_SIZE-1 bytes, which can contain arbitrary fs-dependent
* information (or be NULL).
*
* Pre-0.97 versions of mount() didn't have a flags word.
* When the flags word was introduced its top half was required
* to have the magic value 0xC0ED, and this remained so until 2.4.0-test9.
* Therefore, if this magic number is present, it carries no information
* and must be discarded.
*/
/* The following functions copy user mode parameters to kernel mode , Include :
** 1. kernel_type: Mount the file system type , Such as ext3
** 2. kernel_dir: Mount point path
** 3. dev_name: Equipment name
** 4. data_pages: Option information
*/
/* Parameters :
** dev_name : Name of the mounted device
** dir_name : Mount point name
** type_page: Save the mounted file system type , Such as "ext3"
** flags : Mount sign
** data_page: Most of the time it's NULL
*/
long do_mount(char *dev_name, char *dir_name, char *type_page,
unsigned long flags, void *data_page)
{
struct path path;
int retval = 0;
int mnt_flags = 0;
/* Discard magic */
if ((flags & MS_MGC_MSK) == MS_MGC_VAL)
flags &= ~MS_MGC_MSK;
/* Basic sanity checks */
if (!dir_name || !*dir_name || !memchr(dir_name, 0, PAGE_SIZE))
return -EINVAL;
if (data_page)
((char *)data_page)[PAGE_SIZE - 1] = 0;
/* ... and get the mountpoint */
/* call kern_path(), Find the mount point by its name dentry Etc
** Parameters :@dir_name : Mount point path
** :@LOOKUP_FOLLOW: Find the flag , Continue to search when encountering links
** :@path : The search results are saved in this structure
*/
retval = kern_path(dir_name, LOOKUP_FOLLOW, &path);
if (retval)
return retval;
retval = security_sb_mount(dev_name, &path,
type_page, flags, data_page);
if (retval)
goto dput_out;
/* Default to relatime unless overriden */
if (!(flags & MS_NOATIME))
mnt_flags |= MNT_RELATIME;
/* Separate the per-mountpoint flags */
if (flags & MS_NOSUID)
mnt_flags |= MNT_NOSUID;
if (flags & MS_NODEV)
mnt_flags |= MNT_NODEV;
if (flags & MS_NOEXEC)
mnt_flags |= MNT_NOEXEC;
if (flags & MS_NOATIME)
mnt_flags |= MNT_NOATIME;
if (flags & MS_NODIRATIME)
mnt_flags |= MNT_NODIRATIME;
if (flags & MS_STRICTATIME)
mnt_flags &= ~(MNT_RELATIME | MNT_NOATIME);
if (flags & MS_RDONLY)
mnt_flags |= MNT_READONLY;
flags &= ~(MS_NOSUID | MS_NOEXEC | MS_NODEV | MS_ACTIVE | MS_BORN |
MS_NOATIME | MS_NODIRATIME | MS_RELATIME| MS_KERNMOUNT |
MS_STRICTATIME);
if (flags & MS_REMOUNT)
/* Modify existing file system parameters , That is, change the superblock object s_flags
Installation flags for fields */
retval = do_remount(&path, flags & ~MS_REMOUNT, mnt_flags,
data_page);
else if (flags & MS_BIND) /** It is required that the files or directories on another installation point of the system directory tree can be visible **/
retval = do_loopback(&path, dev_name, flags & MS_REC);
else if (flags & (MS_SHARED | MS_PRIVATE | MS_SLAVE | MS_UNBINDABLE))
retval = do_change_type(&path, flags);
else if (flags & MS_MOVE)
retval = do_move_mount(&path, dev_name);/* Change the installation point of the installed files */
else /*handles normal mount operations. This is the default situation, so no special flags are required*/
retval = do_new_mount(&path, type_page, flags, mnt_flags,
dev_name, data_page); /* Install the normal file system */
dput_out:
path_put(&path);
return retval;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
about :kern_path(dir_name, LOOKUP_FOLLOW, &path);
among : /* call kern_path(), Find the mount point by its name dentry Etc
** Parameters :@dir_name : Mount point path
** :@LOOKUP_FOLLOW: Find the flag , Continue to search when encountering links
** :@path : The search results are saved in this structure
*/
Find the memory directory entry structure in the kernel according to the path name of the mount point (struct dentry), Save in path in ;
about do_new_mount(.......) analysis ;
/*
* create a new mount for userspace and request it to be added into the
* namespace's tree
*/
static int do_new_mount(struct path *path, const char *fstype, int flags,
int mnt_flags, const char *name, void *data)
{
struct file_system_type *type;
struct user_namespace *user_ns = current->nsproxy->mnt_ns->user_ns;
struct vfsmount *mnt;
int err;
if (!ns_capable(current_user_ns(), CAP_SYS_ADMIN))
return -EPERM;
if (!fstype)
return -EINVAL;
type = get_fs_type(fstype);
if (!type)
return -ENODEV;
if (user_ns != &init_user_ns) {
/* Only in special cases allow devices from mounts
* created outside the initial user namespace.
*/
if (!(type->fs_flags & FS_USERNS_DEV_MOUNT)) {
flags |= MS_NODEV;
mnt_flags |= MNT_NODEV | MNT_LOCK_NODEV;
}
if (type->fs_flags & FS_USERNS_VISIBLE) {
if (!fs_fully_visible(type, &mnt_flags)) {
put_filesystem(type);
return -EPERM;
}
}
}
/* Build in the kernel vfsmount Objects and superblock object */
mnt = vfs_kern_mount(type, flags, name, data);
if (!IS_ERR(mnt) && (type->fs_flags & FS_HAS_SUBTYPE) &&
!mnt->mnt_sb->s_subtype)
mnt = fs_set_subtype(mnt, fstype);
put_filesystem(type);
if (IS_ERR(mnt))
return PTR_ERR(mnt);
err = do_add_mount(real_mount(mnt), path, mnt_flags);
if (err)
mntput(mnt);
return err;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
vfs_kern_mount:
/*vfs_kern_mount There are three main things to do :
1. alloc_vfsmnt Create a new struct mount structure
2. stay mount_fs Function to call a specific file system mount The callback function constructs a root dentry, Contains a specific file system super block Information
3. Use the results obtained in step 2 to complete struct mount Construction , return vfsmnt structure .
par name: Express /dev/sda Equipment name
*/
struct vfsmount *
vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data)
{
struct mount *mnt;
struct dentry *root;
if (!type)
return ERR_PTR(-ENODEV);
// alloc A new struct mount structure , And initialize the inner part ( Such as linked list pointer 、mnt_devname And so on
mnt = alloc_vfsmnt(name);
if (!mnt)
return ERR_PTR(-ENOMEM);
if (flags & MS_KERNMOUNT)
mnt->mnt.mnt_flags = MNT_INTERNAL;
/* Call specific file system mount Callback function type->mount, Continue to mount ; such as ext2_fs_type->ext2_mount
ext4_fs_type->ext4_mount */
/*
ext2_fs_type->ext2_mount----->
ext4_fs_type->ext4_mount ---->
The last call is mount_bdev And the corresponding ext2/ext4_fill_super Callback
*/
root = mount_fs(type, flags, name, data);
if (IS_ERR(root)) {
mnt_free_id(mnt);
free_vfsmnt(mnt);
return ERR_CAST(root);
}
// complete mnt The last assignment of the structure , And back to vfsmount structure
mnt->mnt.mnt_root = root;//mount Correlation root dentry ( Use vfsmount relation )
mnt->mnt.mnt_sb = root->d_sb;//mount Associated superblock
mnt->mnt_mountpoint = mnt->mnt.mnt_root;// mount Associated mount points
mnt->mnt_parent = mnt;// The father mounts to himself ( Temporarily point to It will be set later
lock_mount_hash();
list_add_tail(&mnt->mnt_instance, &root->d_sb->s_mounts);
unlock_mount_hash();
return &mnt->mnt;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
mount_bdev The main logic is
1. Find the corresponding block device descriptor according to the file name of the block device to be mounted ( Block device descriptors are used to manipulate block devices behind the kernel );
2. First, in the file system type fs_supers The linked list looks up whether the specified vfs Superblock , I'll compare every super block s_bdev Block device descriptor , Didn't create a vfs Superblock ;
3. The newly created vfs Superblock , Need to call specific file system fill_super Method to read the filled superblock .
/*blkdev_get_by_path Get by device name block_device structure
sget Get the existing or newly allocated super_block structure
If it already exists sb, Release what you got in the first step bdev structure
If it's new sb, Just call the file system to implement fill_super Function to continue processing the new sb, And create the root inode, dentry
Return what you get s_root
*/
struct dentry *mount_bdev(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
struct block_device *bdev;
struct super_block *s;
fmode_t mode = FMODE_READ | FMODE_EXCL;
int error = 0;
if (!(flags & MS_RDONLY))
mode |= FMODE_WRITE;
// adopt dev_name Device name ( Such as /dev/sda1) Get the corresponding block_device structure
// The first is a path finding process , call kern_path() obtain struct path
// And then to path.dentry->d_inode Call for parameter bd_acquire obtain block_device structure
// The problems of path finding and block devices will be described later
bdev = blkdev_get_by_path(dev_name, mode, fs_type);
if (IS_ERR(bdev))
return ERR_CAST(bdev);
if (current_user_ns() != &init_user_ns) {
/*
* For userns mounts, disallow mounting if bdev is open for
* writing
*/
if (!atomic_dec_unless_positive(&bdev->bd_inode->i_writecount)) {
error = -EBUSY;
goto error_bdev;
}
if (bdev->bd_contains != bdev &&
!atomic_dec_unless_positive(&bdev->bd_contains->bd_inode->i_writecount)) {
atomic_inc(&bdev->bd_inode->i_writecount);
error = -EBUSY;
goto error_bdev;
}
}
/*
* once the super is inserted into the list by sget, s_umount
* will protect the lockfs code from trying to start a snapshot
* while we are mounting
*/
mutex_lock(&bdev->bd_fsfreeze_mutex);
if (bdev->bd_fsfreeze_count > 0) {
mutex_unlock(&bdev->bd_fsfreeze_mutex);
error = -EBUSY;
goto error_inc;
}
/*/ sget Now there are fs_type->fs_supers Find the existing super block instance in the linked list ( Because a device may have been mounted ),
fs_supers yes file_system_type Members of , It points to the linked list header of all super block instances under a specific file system . The process of comparison is
Is traversal fs_supers Linked list , Use each one super_block->s_bdev and sget Of bdev Compare the parameters , Compare whether they are the same device ,
test_bdev_super Just for comparison bdev And the function parameters passed in . If an existing superblock instance cannot be found ,
Then you can only create a new one . here set_bdev_super Function is used to put bdev Parameter settings to newly created super_block Of s_bdev domain .
Then set it up s_type and s_id(s_id Here, the file system name is initialized first , Later, if it is found that it is a disk device, change it to the disk device name ),
And put this new sb Join the global super_blocks Linked list , And this file_system_type Of fs_supers In the list .
Here we have a known or new super_block example , The later work is to fill this super_block The content of ,
And add it to various linked lists .
*/
s = sget(fs_type, test_bdev_super, set_bdev_super, flags | MS_NOSEC,
bdev);//----> s->s_bdev = bdev;
mutex_unlock(&bdev->bd_fsfreeze_mutex);
if (IS_ERR(s))
goto error_s;
// This if By judgment sb Is it an existing one or a new one sb, What already exists sb Of s_root It's already initialized , new sb Of s_root Still empty
if (s->s_root) {
/* By mount The root entry of the file system already exists Really read only */
if ((flags ^ s->s_flags) & MS_RDONLY) {
deactivate_locked_super(s);
error = -EBUSY;
goto error_inc;
}
/*
* s_umount nests inside bd_mutex during
* __invalidate_device(). blkdev_put() acquires
* bd_mutex and can't be called under s_umount. Drop
* s_umount temporarily. This is safe as we're
* holding an active reference.
These locks I haven't figured it out yet You need to look at the reasons for concurrency in detail */
up_write(&s->s_umount);
// This corresponds to the previous blkdev_get_by_path prevent blkdev The reference count for is due to getbypath It has been growing since
blkdev_put(bdev, mode);
down_write(&s->s_umount);
} else {
char b[BDEVNAME_SIZE];
s->s_mode = mode;
strlcpy(s->s_id, bdevname(bdev, b), sizeof(s->s_id));
sb_set_blocksize(s, block_size(bdev));
/*/ Set up sb Of mode, id, blocksize after , That's it fill_super It's time .fill_super Is a function parameter ,
It is implemented by the specific file system itself , Such as xfs And that's what happened xfs_fs_fill_super ---- perhaps ext4_fill_super*/
error = fill_super(s, data, flags & MS_SILENT ? 1 : 0);
if (error) {
deactivate_locked_super(s);
goto error;
}
s->s_flags |= MS_ACTIVE;
bdev->bd_super = s;
}
/* Normal return is mount File system root entry */
return dget(s->s_root);
error_s:
error = PTR_ERR(s);
error_inc:
if (current_user_ns() != &init_user_ns) {
atomic_inc(&bdev->bd_inode->i_writecount);
if (bdev->bd_contains != bdev)
atomic_inc(&bdev->bd_contains->bd_inode->i_writecount);
}
error_bdev:
blkdev_put(bdev, mode);
error:
return ERR_PTR(error);
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.

ext2_fill_super The analysis is as follows :
static int ext2_fill_super(struct super_block *sb, void *data, int silent)
{
struct buffer_head * bh;// Buffer header Record read disk superblock
struct ext2_sb_info * sbi; // In memory ext2 Superblock information
struct ext2_super_block * es;// On disk Superblock information
struct inode *root;
unsigned long block;
unsigned long sb_block = get_sb_block(&data);
unsigned long logic_sb_block;
unsigned long offset = 0;
unsigned long def_mount_opts;
long ret = -EINVAL;
int blocksize = BLOCK_SIZE;
int db_count;
int i, j;
__le32 features;
int err;
err = -ENOMEM;
sbi = kzalloc(sizeof(*sbi), GFP_KERNEL); // Distribute In memory ext2 Super block information structure
if (!sbi)
goto failed;
sbi->s_blockgroup_lock =
kzalloc(sizeof(struct blockgroup_lock), GFP_KERNEL);
if (!sbi->s_blockgroup_lock) {
kfree(sbi);
goto failed;
}
sb->s_fs_info = sbi; //vfs Super block of Of s_fs_info Pointing to memory ext2 Super block information structure
sbi->s_sb_block = sb_block;
spin_lock_init(&sbi->s_lock);
/*
* See what the current blocksize for the device is, and
* use that as the blocksize. Otherwise (or if the blocksize
* is smaller than the default) use the default.
* This is important for devices that have a hardware
* sectorsize that is larger than the default.
*/
blocksize = sb_min_blocksize(sb, BLOCK_SIZE);
if (!blocksize) {
ext2_msg(sb, KERN_ERR, "error: unable to set blocksize");
goto failed_sbi;
}
/*
* If the superblock doesn't start on a hardware sector boundary,
* calculate the offset.
*/
if (blocksize != BLOCK_SIZE) {
logic_sb_block = (sb_block*BLOCK_SIZE) / blocksize;
offset = (sb_block*BLOCK_SIZE) % blocksize;
} else {
logic_sb_block = sb_block;
}
if (!(bh = sb_bread(sb, logic_sb_block))) { // Read the superblock from disk to memory Use buffer_head Associate memory buffers with disk sectors
ext2_msg(sb, KERN_ERR, "error: unable to read superblock");
goto failed_sbi;
}
/*
* Note: s_es must be initialized as soon as possible because
* some ext2 macro-instructions depend on its value
*/
es = (struct ext2_super_block *) (((char *)bh->b_data) + offset);// Convert to struct ext2_super_block structure
sbi->s_es = es; // In memory ext2 Super block information structure s_es Point to the real ext2 Disk superblock information structure
sb->s_magic = le16_to_cpu(es->s_magic);// Get the magic number of the file system ext2 by 0xEF53
if (sb->s_magic != EXT2_SUPER_MAGIC) // verification Is magic number right
goto cantfind_ext2;
/* Set defaults before we parse the mount options */
def_mount_opts = le32_to_cpu(es->s_default_mount_opts);
if (def_mount_opts & EXT2_DEFM_DEBUG)
set_opt(sbi->s_mount_opt, DEBUG);
if (def_mount_opts & EXT2_DEFM_BSDGROUPS)
set_opt(sbi->s_mount_opt, GRPID);
if (def_mount_opts & EXT2_DEFM_UID16)
set_opt(sbi->s_mount_opt, NO_UID32);
#ifdef CONFIG_EXT2_FS_XATTR
if (def_mount_opts & EXT2_DEFM_XATTR_USER)
set_opt(sbi->s_mount_opt, XATTR_USER);
#endif
#ifdef CONFIG_EXT2_FS_POSIX_ACL
if (def_mount_opts & EXT2_DEFM_ACL)
set_opt(sbi->s_mount_opt, POSIX_ACL);
#endif
if (le16_to_cpu(sbi->s_es->s_errors) == EXT2_ERRORS_PANIC)
set_opt(sbi->s_mount_opt, ERRORS_PANIC);
else if (le16_to_cpu(sbi->s_es->s_errors) == EXT2_ERRORS_CONTINUE)
set_opt(sbi->s_mount_opt, ERRORS_CONT);
else
set_opt(sbi->s_mount_opt, ERRORS_RO);
sbi->s_resuid = make_kuid(&init_user_ns, le16_to_cpu(es->s_def_resuid));
sbi->s_resgid = make_kgid(&init_user_ns, le16_to_cpu(es->s_def_resgid));
set_opt(sbi->s_mount_opt, RESERVATION);
if (!parse_options((char *) data, sb))
goto failed_mount;
sb->s_flags = (sb->s_flags & ~MS_POSIXACL) |
((EXT2_SB(sb)->s_mount_opt & EXT2_MOUNT_POSIX_ACL) ?
MS_POSIXACL : 0);
sb->s_iflags |= SB_I_CGROUPWB;
if (le32_to_cpu(es->s_rev_level) == EXT2_GOOD_OLD_REV &&
(EXT2_HAS_COMPAT_FEATURE(sb, ~0U) ||
EXT2_HAS_RO_COMPAT_FEATURE(sb, ~0U) ||
EXT2_HAS_INCOMPAT_FEATURE(sb, ~0U)))
ext2_msg(sb, KERN_WARNING,
"warning: feature flags set on rev 0 fs, "
"running e2fsck is recommended");
/*
* Check feature flags regardless of the revision level, since we
* previously didn't change the revision level when setting the flags,
* so there is a chance incompat flags are set on a rev 0 filesystem.
*/
features = EXT2_HAS_INCOMPAT_FEATURE(sb, ~EXT2_FEATURE_INCOMPAT_SUPP);
if (features) {
ext2_msg(sb, KERN_ERR, "error: couldn't mount because of "
"unsupported optional features (%x)",
le32_to_cpu(features));
goto failed_mount;
}
if (!(sb->s_flags & MS_RDONLY) &&
(features = EXT2_HAS_RO_COMPAT_FEATURE(sb, ~EXT2_FEATURE_RO_COMPAT_SUPP))){
ext2_msg(sb, KERN_ERR, "error: couldn't mount RDWR because of "
"unsupported optional features (%x)",
le32_to_cpu(features));
goto failed_mount;
}
// Get the block size read from the disk
blocksize = BLOCK_SIZE << le32_to_cpu(sbi->s_es->s_log_block_size);
if (sbi->s_mount_opt & EXT2_MOUNT_DAX) {
if (blocksize != PAGE_SIZE) {
ext2_msg(sb, KERN_ERR,
"error: unsupported blocksize for dax");
goto failed_mount;
}
if (!sb->s_bdev->bd_disk->fops->direct_access) {
ext2_msg(sb, KERN_ERR,
"error: device does not support dax");
goto failed_mount;
}
}
/* If the blocksize doesn't match, re-read the thing.. */
if (sb->s_blocksize != blocksize) {
brelse(bh);
if (!sb_set_blocksize(sb, blocksize)) {
ext2_msg(sb, KERN_ERR,
"error: bad blocksize %d", blocksize);
goto failed_sbi;
}
logic_sb_block = (sb_block*BLOCK_SIZE) / blocksize;
offset = (sb_block*BLOCK_SIZE) % blocksize;
bh = sb_bread(sb, logic_sb_block);// again Read superblock
if(!bh) {
ext2_msg(sb, KERN_ERR, "error: couldn't read"
"superblock on 2nd try");
goto failed_sbi;
}
es = (struct ext2_super_block *) (((char *)bh->b_data) + offset);
sbi->s_es = es;
if (es->s_magic != cpu_to_le16(EXT2_SUPER_MAGIC)) {
ext2_msg(sb, KERN_ERR, "error: magic mismatch");
goto failed_mount;
}
}
sb->s_maxbytes = ext2_max_size(sb->s_blocksize_bits);// Set the maximum file size
sb->s_max_links = EXT2_LINK_MAX;
// Read or set inode Size and first inode Number
if (le32_to_cpu(es->s_rev_level) == EXT2_GOOD_OLD_REV) {
sbi->s_inode_size = EXT2_GOOD_OLD_INODE_SIZE;
sbi->s_first_ino = EXT2_GOOD_OLD_FIRST_INO;
} else {
sbi->s_inode_size = le16_to_cpu(es->s_inode_size);
sbi->s_first_ino = le32_to_cpu(es->s_first_ino);
if ((sbi->s_inode_size < EXT2_GOOD_OLD_INODE_SIZE) ||
!is_power_of_2(sbi->s_inode_size) ||
(sbi->s_inode_size > blocksize)) {
ext2_msg(sb, KERN_ERR,
"error: unsupported inode size: %d",
sbi->s_inode_size);
goto failed_mount;
}
}
sbi->s_frag_size = EXT2_MIN_FRAG_SIZE <<
le32_to_cpu(es->s_log_frag_size);
if (sbi->s_frag_size == 0)
goto cantfind_ext2;
sbi->s_frags_per_block = sb->s_blocksize / sbi->s_frag_size;
sbi->s_blocks_per_group = le32_to_cpu(es->s_blocks_per_group); // Assign each block group Number of pieces
sbi->s_frags_per_group = le32_to_cpu(es->s_frags_per_group);
sbi->s_inodes_per_group = le32_to_cpu(es->s_inodes_per_group); // Assign each block group inode Number
if (EXT2_INODE_SIZE(sb) == 0)
goto cantfind_ext2;
sbi->s_inodes_per_block = sb->s_blocksize / EXT2_INODE_SIZE(sb);// Assign values to each block inode Number
if (sbi->s_inodes_per_block == 0 || sbi->s_inodes_per_group == 0)
goto cantfind_ext2;
sbi->s_itb_per_group = sbi->s_inodes_per_group /
sbi->s_inodes_per_block;
sbi->s_desc_per_block = sb->s_blocksize /
sizeof (struct ext2_group_desc);// Assign values to each block Number of block group descriptors
sbi->s_sbh = bh;// The superblock buffer read by the assignment
sbi->s_mount_state = le16_to_cpu(es->s_state);// Assignment mount status
sbi->s_addr_per_block_bits =
ilog2 (EXT2_ADDR_PER_BLOCK(sb));
sbi->s_desc_per_block_bits =
ilog2 (EXT2_DESC_PER_BLOCK(sb));
if (sb->s_magic != EXT2_SUPER_MAGIC)
goto cantfind_ext2;
if (sb->s_blocksize != bh->b_size) {
if (!silent)
ext2_msg(sb, KERN_ERR, "error: unsupported blocksize");
goto failed_mount;
}
if (sb->s_blocksize != sbi->s_frag_size) {
ext2_msg(sb, KERN_ERR,
"error: fragsize %lu != blocksize %lu"
"(not supported yet)",
sbi->s_frag_size, sb->s_blocksize);
goto failed_mount;
}
if (sbi->s_blocks_per_group > sb->s_blocksize * 8) {
ext2_msg(sb, KERN_ERR,
"error: #blocks per group too big: %lu",
sbi->s_blocks_per_group);
goto failed_mount;
}
if (sbi->s_frags_per_group > sb->s_blocksize * 8) {
ext2_msg(sb, KERN_ERR,
"error: #fragments per group too big: %lu",
sbi->s_frags_per_group);
goto failed_mount;
}
if (sbi->s_inodes_per_group > sb->s_blocksize * 8) {
ext2_msg(sb, KERN_ERR,
"error: #inodes per group too big: %lu",
sbi->s_inodes_per_group);
goto failed_mount;
}
if (EXT2_BLOCKS_PER_GROUP(sb) == 0)
goto cantfind_ext2;
// Compute the block group descriptor Number
sbi->s_groups_count = ((le32_to_cpu(es->s_blocks_count) -
le32_to_cpu(es->s_first_data_block) - 1)
/ EXT2_BLOCKS_PER_GROUP(sb)) + 1;
db_count = (sbi->s_groups_count + EXT2_DESC_PER_BLOCK(sb) - 1) /
EXT2_DESC_PER_BLOCK(sb);
sbi->s_group_desc = kmalloc (db_count * sizeof (struct buffer_head *), GFP_KERNEL);// Allocate block group descriptors bh Array
if (sbi->s_group_desc == NULL) {
ext2_msg(sb, KERN_ERR, "error: not enough memory");
goto failed_mount;
}
bgl_lock_init(sbi->s_blockgroup_lock);
sbi->s_debts = kcalloc(sbi->s_groups_count, sizeof(*sbi->s_debts), GFP_KERNEL);
if (!sbi->s_debts) {
ext2_msg(sb, KERN_ERR, "error: not enough memory");
goto failed_mount_group_desc;
}
for (i = 0; i < db_count; i++) {// Read block group descriptor
block = descriptor_loc(sb, logic_sb_block, i);
sbi->s_group_desc[i] = sb_bread(sb, block);
if (!sbi->s_group_desc[i]) { // Read the The block group descriptor buffer holds To sbi->s_group_desc[i]
for (j = 0; j < i; j++)
brelse (sbi->s_group_desc[j]);
ext2_msg(sb, KERN_ERR,
"error: unable to read group descriptors");
goto failed_mount_group_desc;
}
}
if (!ext2_check_descriptors (sb)) {
ext2_msg(sb, KERN_ERR, "group descriptors corrupted");
goto failed_mount2;
}
sbi->s_gdb_count = db_count;
get_random_bytes(&sbi->s_next_generation, sizeof(u32));
spin_lock_init(&sbi->s_next_gen_lock);
/* per fileystem reservation list head & lock */
spin_lock_init(&sbi->s_rsv_window_lock);
sbi->s_rsv_window_root = RB_ROOT;
/*
* Add a single, static dummy reservation to the start of the
* reservation window list --- it gives us a placeholder for
* append-at-start-of-list which makes the allocation logic
* _much_ simpler.
*/
sbi->s_rsv_window_head.rsv_start = EXT2_RESERVE_WINDOW_NOT_ALLOCATED;
sbi->s_rsv_window_head.rsv_end = EXT2_RESERVE_WINDOW_NOT_ALLOCATED;
sbi->s_rsv_window_head.rsv_alloc_hit = 0;
sbi->s_rsv_window_head.rsv_goal_size = 0;
ext2_rsv_window_add(sb, &sbi->s_rsv_window_head);
err = percpu_counter_init(&sbi->s_freeblocks_counter,
ext2_count_free_blocks(sb), GFP_KERNEL);
if (!err) {
err = percpu_counter_init(&sbi->s_freeinodes_counter,
ext2_count_free_inodes(sb), GFP_KERNEL);
}
if (!err) {
err = percpu_counter_init(&sbi->s_dirs_counter,
ext2_count_dirs(sb), GFP_KERNEL);
}
if (err) {
ext2_msg(sb, KERN_ERR, "error: insufficient memory");
goto failed_mount3;
}
#ifdef CONFIG_EXT2_FS_XATTR
sbi->s_mb_cache = ext2_xattr_create_cache();
if (!sbi->s_mb_cache) {
ext2_msg(sb, KERN_ERR, "Failed to create an mb_cache");
goto failed_mount3;
}
#endif
/*
* set up enough so that it can read an inode
*/
sb->s_op = &ext2_sops;// Assign superblock operations
sb->s_export_op = &ext2_export_ops;
sb->s_xattr = ext2_xattr_handlers;
#ifdef CONFIG_QUOTA
sb->dq_op = &dquot_operations;
sb->s_qcop = &dquot_quotactl_ops;
sb->s_quota_types = QTYPE_MASK_USR | QTYPE_MASK_GRP;
#endif
root = ext2_iget(sb, EXT2_ROOT_INO);// Read root inode (ext2 Root root inode Number is 2)
if (IS_ERR(root)) {
ret = PTR_ERR(root);
goto failed_mount3;
}
if (!S_ISDIR(root->i_mode) || !root->i_blocks || !root->i_size) {
iput(root);
ext2_msg(sb, KERN_ERR, "error: corrupt root inode, run e2fsck");
goto failed_mount3;
}
sb->s_root = d_make_root(root); // Create a root dentry And build roots inode And roots dentry Relationship
if (!sb->s_root) {
ext2_msg(sb, KERN_ERR, "error: get root inode failed");
ret = -ENOMEM;
goto failed_mount3;
}
if (EXT2_HAS_COMPAT_FEATURE(sb, EXT3_FEATURE_COMPAT_HAS_JOURNAL))
ext2_msg(sb, KERN_WARNING,
"warning: mounting ext3 filesystem as ext2");
if (ext2_setup_super (sb, es, sb->s_flags & MS_RDONLY))
sb->s_flags |= MS_RDONLY;
ext2_write_super(sb);// Synchronize superblock information to disk Such as mounting time, etc
return 0;
cantfind_ext2:
if (!silent)
ext2_msg(sb, KERN_ERR,
"error: can't find an ext2 filesystem on dev %s.",
sb->s_id);
goto failed_mount;
failed_mount3:
if (sbi->s_mb_cache)
ext2_xattr_destroy_cache(sbi->s_mb_cache);
percpu_counter_destroy(&sbi->s_freeblocks_counter);
percpu_counter_destroy(&sbi->s_freeinodes_counter);
percpu_counter_destroy(&sbi->s_dirs_counter);
failed_mount2:
for (i = 0; i < db_count; i++)
brelse(sbi->s_group_desc[i]);
failed_mount_group_desc:
kfree(sbi->s_group_desc);
kfree(sbi->s_debts);
failed_mount:
brelse(bh);
failed_sbi:
sb->s_fs_info = NULL;
kfree(sbi->s_blockgroup_lock);
kfree(sbi);
failed:
return ret;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
- 153.
- 154.
- 155.
- 156.
- 157.
- 158.
- 159.
- 160.
- 161.
- 162.
- 163.
- 164.
- 165.
- 166.
- 167.
- 168.
- 169.
- 170.
- 171.
- 172.
- 173.
- 174.
- 175.
- 176.
- 177.
- 178.
- 179.
- 180.
- 181.
- 182.
- 183.
- 184.
- 185.
- 186.
- 187.
- 188.
- 189.
- 190.
- 191.
- 192.
- 193.
- 194.
- 195.
- 196.
- 197.
- 198.
- 199.
- 200.
- 201.
- 202.
- 203.
- 204.
- 205.
- 206.
- 207.
- 208.
- 209.
- 210.
- 211.
- 212.
- 213.
- 214.
- 215.
- 216.
- 217.
- 218.
- 219.
- 220.
- 221.
- 222.
- 223.
- 224.
- 225.
- 226.
- 227.
- 228.
- 229.
- 230.
- 231.
- 232.
- 233.
- 234.
- 235.
- 236.
- 237.
- 238.
- 239.
- 240.
- 241.
- 242.
- 243.
- 244.
- 245.
- 246.
- 247.
- 248.
- 249.
- 250.
- 251.
- 252.
- 253.
- 254.
- 255.
- 256.
- 257.
- 258.
- 259.
- 260.
- 261.
- 262.
- 263.
- 264.
- 265.
- 266.
- 267.
- 268.
- 269.
- 270.
- 271.
- 272.
- 273.
- 274.
- 275.
- 276.
- 277.
- 278.
- 279.
- 280.
- 281.
- 282.
- 283.
- 284.
- 285.
- 286.
- 287.
- 288.
- 289.
- 290.
- 291.
- 292.
- 293.
- 294.
- 295.
- 296.
- 297.
- 298.
- 299.
- 300.
- 301.
- 302.
- 303.
- 304.
- 305.
- 306.
- 307.
- 308.
- 309.
- 310.
- 311.
- 312.
- 313.
- 314.
- 315.
- 316.
- 317.
- 318.
- 319.
- 320.
- 321.
- 322.
- 323.
- 324.
- 325.
- 326.
- 327.
- 328.
- 329.
- 330.
- 331.
- 332.
- 333.
- 334.
- 335.
- 336.
- 337.
- 338.
- 339.
- 340.
- 341.
- 342.
- 343.
- 344.
- 345.
- 346.
- 347.
- 348.
- 349.
- 350.
- 351.
- 352.
- 353.
- 354.
- 355.
- 356.
- 357.
- 358.
- 359.
- 360.
- 361.
- 362.
- 363.
- 364.
- 365.
- 366.
- 367.
- 368.
- 369.
- 370.
- 371.
- 372.
- 373.
- 374.
- 375.
- 376.
- 377.
- 378.
- 379.
- 380.
- 381.
- 382.
- 383.
- 384.
- 385.
- 386.
- 387.
- 388.
- 389.
- 390.
- 391.
- 392.
- 393.
- 394.
- 395.
- 396.
- 397.
- 398.
- 399.
- 400.
View Code
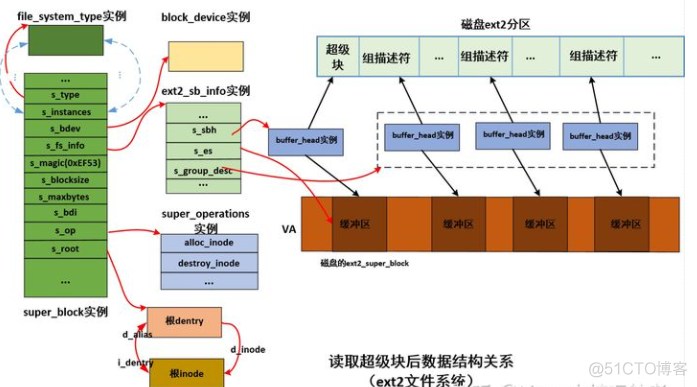
You can see ext2_fill_super The main work is :
- 1. Read superblock on disk ;
- 2. Fill in and associate vfs Superblock ;
- 3. Read block group descriptor ;
- 4. Read disk root inode And establish vfs root inode;
- 5. Create a root dentry Related to the root inode.
When the mount point is ready , The next step is mount Instance associated mount point and add child mount Instance to the global file system mount tree .
do_add_mount Function analysis
Its main content is :
take mount Instances are associated with mount points ( Will mount Instance join to mount Hashtable , Of the parent file system vfsmount And the real mount point dentry The two tuples are indexes , The path name is easy to find ),
as well as mount Instance and file system dentry Connect ( The pathname is easy to follow dentry To access all the files in this file system )
/*
* add a mount into a namespace's mount tree
*/
static int do_add_mount(struct mount *newmnt, struct path *path, int mnt_flags)
{
struct mountpoint *mp;
struct mount *parent;
int err;
mnt_flags &= ~MNT_INTERNAL_FLAGS;
mp = lock_mount(path);
if (IS_ERR(mp))
return PTR_ERR(mp);
parent = real_mount(path->mnt);// Get the mount instance of the parent mount point
err = -EINVAL;
if (unlikely(!check_mnt(parent))) {
/* that's acceptable only for automounts done in private ns */
if (!(mnt_flags & MNT_SHRINKABLE))
goto unlock;
/* ... and for those we'd better have mountpoint still alive */
if (!parent->mnt_ns)
goto unlock;
}
/* Refuse the same filesystem on the same mount point */
err = -EBUSY;
if (path->mnt->mnt_sb == newmnt->mnt.mnt_sb &&
path->mnt->mnt_root == path->dentry)
goto unlock;
err = -EINVAL;
if (d_is_symlink(newmnt->mnt.mnt_root))
goto unlock;
newmnt->mnt.mnt_flags = mnt_flags;
err = graft_tree(newmnt, parent, mp);
unlock:
unlock_mount(mp);
return err;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
View Code
lookup_mnt(path); //lookup_mnt takes a reference to the found vfsmount. The analysis is as follows
/*
lock_mount Delivered path It wasn't a mount point before :
The call chain is :
lock_mount
->mnt = lookup_mnt(path) // No children mount return NULL
->mp = get_mountpoint(dentry) // Distribute mountpoint Join in mountpoint hash surface (dentry Calculation hash), Set up dentry For mount point
->return mp // Returns the mount point instance found
2)lock_mount Delivered path It used to be a mount point : We are now executing mount -t ext2 /dev/sda4 /mnt
Before /mnt The mount of
mount /dev/sda1 /mnt (1)
mount /dev/sda2 /mnt (2)
mount /dev/sda3 /mnt (3)
The call chain is :
lock_mount
->mnt = lookup_mnt(path) // return (1) Of mount example
->path->mnt = mnt // Next time you look up path->mnt assignment (1) Of mount example
->dentry = path->dentry = dget(mnt->mnt_root) // // Next time you look up path->dentry assignment (1) The root of the dentry
->mnt = lookup_mnt(path) // return (2) Of mount example
->path->mnt = mnt // Next time you look up path->mnt assignment (2) Of mount example
->dentry = path->dentry = dget(mnt->mnt_root) // // Next time you look up path->dentry assignment (2) The root of the dentry
->mnt = lookup_mnt(path) // return (3) Of mount example
->path->mnt = mnt // Next time you look up path->mnt assignment (3) Of mount example
->dentry = path->dentry = dget(mnt->mnt_root) // // Next time you look up path->dentry assignment (3) The root of the dentry
-> mnt = lookup_mnt(path) // No children mount return NULL
->mp = get_mountpoint(dentry) // Distribute mountpoint Join in mountpoint hash surface (dentry Calculation hash), Set up dentry For mount point ((3) The root of the dentry As a mount point )
->return mp // Returns the mount point instance found ( That's the last mount (3) The root of the file system dentry)
*/
static struct mountpoint *lock_mount(struct path *path)
{
struct vfsmount *mnt;
struct dentry *dentry = path->dentry;
retry:
mutex_lock(&dentry->d_inode->i_mutex);
if (unlikely(cant_mount(dentry))) {
mutex_unlock(&dentry->d_inode->i_mutex);
return ERR_PTR(-ENOENT);
}
namespace_lock();
mnt = lookup_mnt(path); //lookup_mnt takes a reference to the found vfsmount.
if (likely(!mnt)) {
struct mountpoint *mp = get_mountpoint(dentry);
if (IS_ERR(mp)) {
namespace_unlock();
mutex_unlock(&dentry->d_inode->i_mutex);
return mp;
}
return mp;
}
namespace_unlock();
mutex_unlock(&path->dentry->d_inode->i_mutex);
path_put(path);
path->mnt = mnt;
dentry = path->dentry = dget(mnt->mnt_root);
goto retry;
}
/*
* lookup_mnt - Return the first child mount mounted at path
*
* "First" means first mounted chronologically. If you create the
* following mounts:
*
* mount /dev/sda1 /mnt
* mount /dev/sda2 /mnt
* mount /dev/sda3 /mnt
*
* Then lookup_mnt() on the base /mnt dentry in the root mount will
* return successively the root dentry and vfsmount of /dev/sda1, then
* /dev/sda2, then /dev/sda3, then NULL.
*
* lookup_mnt takes a reference to the found vfsmount.
*/
struct vfsmount *lookup_mnt(struct path *path)
{
struct mount *child_mnt;
struct vfsmount *m;
unsigned seq;
rcu_read_lock();
do {
seq = read_seqbegin(&mount_lock);
child_mnt = __lookup_mnt(path->mnt, path->dentry);
m = child_mnt ? &child_mnt->mnt : NULL;
} while (!legitimize_mnt(m, seq));
rcu_read_unlock();
return m;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
View Code
/*
* @source_mnt : mount tree to be attached
* @nd : place the mount tree @source_mnt is attached
* @parent_nd : if non-null, detach the source_mnt from its parent and
* store the parent mount and mountpoint dentry.
* (done when source_mnt is moved)
*
* NOTE: in the table below explains the semantics when a source mount
* of a given type is attached to a destination mount of a given type.
* ---------------------------------------------------------------------------
* | BIND MOUNT OPERATION |
* |**************************************************************************
* | source-->| shared | private | slave | unbindable |
* | dest | | | | |
* | | | | | | |
* | v | | | | |
* |**************************************************************************
* | shared | shared (++) | shared (+) | shared(+++)| invalid |
* | | | | | |
* |non-shared| shared (+) | private | slave (*) | invalid |
* ***************************************************************************
* A bind operation clones the source mount and mounts the clone on the
* destination mount.
*
* (++) the cloned mount is propagated to all the mounts in the propagation
* tree of the destination mount and the cloned mount is added to
* the peer group of the source mount.
* (+) the cloned mount is created under the destination mount and is marked
* as shared. The cloned mount is added to the peer group of the source
* mount.
* (+++) the mount is propagated to all the mounts in the propagation tree
* of the destination mount and the cloned mount is made slave
* of the same master as that of the source mount. The cloned mount
* is marked as 'shared and slave'.
* (*) the cloned mount is made a slave of the same master as that of the
* source mount.
*
* ---------------------------------------------------------------------------
* | MOVE MOUNT OPERATION |
* |**************************************************************************
* | source-->| shared | private | slave | unbindable |
* | dest | | | | |
* | | | | | | |
* | v | | | | |
* |**************************************************************************
* | shared | shared (+) | shared (+) | shared(+++) | invalid |
* | | | | | |
* |non-shared| shared (+*) | private | slave (*) | unbindable |
* ***************************************************************************
*
* (+) the mount is moved to the destination. And is then propagated to
* all the mounts in the propagation tree of the destination mount.
* (+*) the mount is moved to the destination.
* (+++) the mount is moved to the destination and is then propagated to
* all the mounts belonging to the destination mount's propagation tree.
* the mount is marked as 'shared and slave'.
* (*) the mount continues to be a slave at the new location.
*
* if the source mount is a tree, the operations explained above is
* applied to each mount in the tree.
* Must be called without spinlocks held, since this function can sleep
* in allocations.
*/
static int attach_recursive_mnt(struct mount *source_mnt,
struct mount *dest_mnt,
struct mountpoint *dest_mp,
struct path *parent_path)
{
HLIST_HEAD(tree_list);
struct mnt_namespace *ns = dest_mnt->mnt_ns;
struct mountpoint *smp;
struct mount *child, *p;
struct hlist_node *n;
int err;
/* Preallocate a mountpoint in case the new mounts need
* to be tucked under other mounts.
*/
smp = get_mountpoint(source_mnt->mnt.mnt_root);
if (IS_ERR(smp))
return PTR_ERR(smp);
/* Is there space to add these mounts to the mount namespace? */
if (!parent_path) {
err = count_mounts(ns, source_mnt);
if (err)
goto out;
}
if (IS_MNT_SHARED(dest_mnt)) {
err = invent_group_ids(source_mnt, true);
if (err)
goto out;
err = propagate_mnt(dest_mnt, dest_mp, source_mnt, &tree_list);
lock_mount_hash();
if (err)
goto out_cleanup_ids;
for (p = source_mnt; p; p = next_mnt(p, source_mnt))
set_mnt_shared(p);
} else {
lock_mount_hash();
}
if (parent_path) {
detach_mnt(source_mnt, parent_path);
attach_mnt(source_mnt, dest_mnt, dest_mp);
touch_mnt_namespace(source_mnt->mnt_ns);
} else {
/**
child_mnt->mnt_mountpoint = mp->m_dentry; // Correlator mount To the mount point dentry
child_mnt->mnt_parent = mnt; // Son mount->mnt_parent Point to father mount
child_mnt->mnt_mp = mp; // Son mount->mnt_mp Point to mount point
hlist_add_head(&child_mnt->mnt_mp_list, &mp->m_list); //mount Add to mount point list */
mnt_set_mountpoint(dest_mnt, dest_mp, source_mnt);
commit_tree(source_mnt);// Submit mount tree
/*/----->/*__attach_mnt(mnt, parent)
-> hlist_add_head_rcu(&mnt->mnt_hash,
¦ m_hash(&parent->mnt, mnt->mnt_mountpoint)); // Add to mount hash surface , Through the parent mount point vfsmount And mount point dentry As index ( As in the example above <(3) Of vfsmount , (3) The root of the dentry>)
list_add_tail(&mnt->mnt_child, &parent->mnt_mounts); // Add to parent mount Linked list
*/
}
hlist_for_each_entry_safe(child, n, &tree_list, mnt_hash) {
struct mount *q;
hlist_del_init(&child->mnt_hash);
q = __lookup_mnt(&child->mnt_parent->mnt,
child->mnt_mountpoint);
if (q)
mnt_change_mountpoint(child, smp, q);
commit_tree(child);
}
put_mountpoint(smp);
unlock_mount_hash();
return 0;
out_cleanup_ids:
while (!hlist_empty(&tree_list)) {
child = hlist_entry(tree_list.first, struct mount, mnt_hash);
child->mnt_parent->mnt_ns->pending_mounts = 0;
umount_tree(child, UMOUNT_SYNC);
}
unlock_mount_hash();
cleanup_group_ids(source_mnt, NULL);
out:
ns->pending_mounts = 0;
read_seqlock_excl(&mount_lock);
put_mountpoint(smp);
read_sequnlock_excl(&mount_lock);
return err;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
View Code
do_add_mount after vfs Diagram between object data structures ps:/mnt It wasn't the mount point before

In the figure /dev/sda1 Mount the child file system in to the parent file system /mnt Under the table of contents . When mounted, it creates mount、super_block、 Follow inode、 Follow dentry Four big data structures and build relationships , Put the sub file system's mount Add to (Vp, Dp3) Two tuples are indexed mount In the hash table , By setting mnt Catalog entry for (Dp3) Of DCACHE_MOUNTED To mark it as a mount point , And establish a kinship with the parent file system, and the mount is completed .
When you need to access a file in a child file system , It will be resolved to mnt Catalog , It was found to be a mount point , Would pass (Vp, Dp3) The binary is in mount Found in the hash table for the child file system mount example (Mc), And then it starts from the sub file system dentry(Dc1) Start to go down and continue to search , Finally access to the file on the sub file system
Diagram of the relationship between multiple file systems and single mount point

In the figure, the block device /dev/sda1 Sub file systems in 1 Mount to /mnt Catalog , And then put the block device /dev/sdb1 Sub file systems in 2 Mount to /mnt In the catalogue .
When the sub file system 1 When you mount it , Will create mount、super_block、 Follow inode、 Follow dentry Four data structures ( They correspond to Mc1、Sc1、Dc1、Ic1) And build relationships , Put the sub file system's Mc1 Add to (Vp, Dp3) Two tuples are indexed mount In the hash table , By setting /mnt Of the directory entry DCACHE_MOUNTED To mark it as a mount point , And establish a kinship with the parent file system, and the mount is completed .
When the sub file system 2 When you mount it , Will create mount、super_block、 Follow inode、 Follow dentry Four data structures ( They correspond to Mc2、Sc2、Dc4、Ic2) And build relationships , At this time, you will find /mnt The directory is the mount point , Then the sub file system 1 Root directory (Dc1) As a file system 2 The mount point , Put the sub file system's Mc2 Add to (Vc1, Dc1) Two tuples are indexed mount In the hash table , By setting Dc1 Of DCACHE_MOUNTED To mark it as a mount point , And establish a kinship with the parent file system, and the mount is completed .
here , Sub file system 1 It's been replaced by a sub file system 2 It's hidden , When the pathname finds /mnt Catalog time , It was found to be a mount point , Through (Vp, Dp3) Binary is the index in mount Found in hash table Mc1, It's going to go to the file system 1 It's the same as the catalog (Dc1) Start to go down and continue to search , Find out Dc1 It's also a mount point , be ( adopt Vc1, Dc1) Binary is the index in mount Found in hash table Mc2, It's going to go to the file system 1 It's the same as the catalog (Dc4) Start to go down and continue to search , So you access the file system 2 Documents in . Unless , file system 2 uninstalled , file system 1 The heel of dentry(Dc1) No longer a mount point , At this point, the file system 1 In order to be accessed again .

The mounting relationship between father and son mounting points
Suppose that /mnt There's a file system on it , According to the above conditions, we take /dev/sda1 Mount to /mnt/a For example , To explain /mnt/a On this mount instance and /mnt The relationship between the mount instance of , As shown in the figure below :

The parent file system represents /mnt File system on , The sub file system represents /mnt/a File system on ( The place with color is the key point ). Parent child file system through mnt_parent, mount_child, mnt_mounts Wait for members to connect , Of each mounted instance mnt_sb All point to the file system of the mounted instance super_block. Of each mounted instance mnt_root All point to the root of this file system dentry.
root dentry Is the beginning of a path to a file system , That is to say "/". Like a pathname /mnt/a/dir/file. stay /mnt/a In this file system, this file is /dir/file, This starts with "/" representative /mnt/a The root of the mounted file system , That is, as shown in the red above dentry, It's the beginning of this file system dentry. When you find the root of a file system , If you want to continue to explore the complete path, you should follow /mnt/a The mount instance of finds its parent file system up , That is to say /mnt File system mounted under ./dev/sda1 It's on /mnt/a On , there /mnt/a representative /mnt A child of the next file system dentry, As shown in the green part of the picture . Note that red and green are two different... In two file systems dentry, Although it is not appropriate to say that they are a pathname from a global point of view . So from /mnt Look at the file system /mnt/a Namely /a. Finally, it's up there rootfs file system , It's the top root "/". So we said before , Indicates that the path to a file needs <mount, dentry> Two tuples to determine .
Of the sub file system mnt_mountpoint It points to one of the parent file systems dentry, This dentry That's the real mount point of the sub file system . It can be said that the sub file system will create a new one after mounting dentry, And build the path structure under this file system .
According to the above ,/mnt/a This newly mounted file system creates a new mount, super_block, root inode And roots dentry. After understanding a simple parent-child file system mount relationship , Let's see what it looks like when multiple file systems are mounted to the same pathname
The mount relationship of multiple mount points in a single file system

One file system corresponds to one super_block, So of course, there is only one file system in the same file system super_block. But because it was mounted twice , Each mount corresponds to a mount instance struct mount, There are two mount example . In addition, the same file system has only one root , That is, two mount instances share one root dentry. But because it's mounted on two different routes , So each mount instance has mnt_mountpoint Point to different dentry. because /mnt/a and /mnt/x They belong to two subdirectories of the same file system , So two people mount To the same father mount
Important rules
1) After the file system is mounted, there will be the following vfs Object created :
super_block
mount
root inode
root dentry
notes : among mount Objects constructed for pure software ( Embedded vfsmount object ), Other objects depend on the file system type , It may involve disk operations .
super_block Superblock instance , Information describing a file system , Some need disk read to fill in memory to build ( Such as disk file system ), Some are built directly in memory .
mount Mount instance , Describe a mount of a file system , Mainly associated with a file system to mount point , Important preparation for pathname lookup .
root inode Every file system has roots inode, Some need disk read to fill in memory to build ( Such as disk file system , root inode The number one is known ), Some are built directly in memory .
root dentry Every file system has roots dentry, According to the root inode To build , Pathname lookup steps to the root of the file system dentry To access the files of this file system .
2) A directory can be mounted by multiple file systems . The first time to mount it is to directly mount it to this directory , The newly mounted file system is actually mounted at the root of the previous file system dentry On .
3) When a directory is mounted by multiple file systems , The new mount causes the previous mount to be hidden .
4) When a directory is mounted by the file system , Other subdirectories or files contained in the original directory are hidden .
5) Every time you mount it, there's one mount The example describes this mount .
6) A file system on a fast device can be mounted to multiple directories , There are many. mount example , But there will only be one super_block、 root dentry And roots inode.
7)mount Instance is used to associate mount points dentry And file system , When it comes to pathname lookup “ route ” The role of .
8) Mounting a file system must ensure that the type of file system to be mounted has been registered .
9) The file system type will be queried when mounting fs_type->fs_supers Linked list , Check if there is super_block Be added to the list , If not, the disk superblock will be allocated and read .
10) Object level : One fs_type->fs_supers Linked lists can be attached to mounted superblocks belonging to the same file system , Hyperblock list can be linked to the same hyperblock mount example fs_type -> super_block -> mount From high to low levels of inclusion .
http proxy server (3-4-7 Layer of the agent )- Network event library common component 、 kernel kernel drive Camera drive tcpip Network protocol stack 、netfilter、bridge Seems to have seen !!!! But he that doeth good Don't ask future -- Height and weight 180 Fat man
边栏推荐
- Overview of new features in mongodb5.0
- How accurate are the two common methods of domain name IP query
- Oceanus kudu sink summary
- Five minute run through 3D map demo
- WordPress pill applet build applet from zero to one [pagoda panel environment installation]
- Implementation of code rate and frame rate statistics in easyplayer RTSP player
- How to give full play to the advantages of Internet of things by edge computing intelligent gateway
- How long will it take for us to have praise for Shopify's market value of 100 billion yuan?
- Another authoritative recommendation! Tencent zero trust was recognized by omdia Report
- Record -- about the problem of garbled code when JSP foreground passes parameters to the background
猜你喜欢

Rockscache schematic diagram of cache operation

数据库 存储过程 begin end

解读AI机器人产业发展的顶层设计
缓存操作rockscache原理图

记录--关于JSP前台传参数到后台出现乱码的问题

leetcode:85. Max rectangle

基于三维GIS系统的智慧水库管理应用
![Command ‘[‘where‘, ‘cl‘]‘ returned non-zero exit status 1.](/img/2c/d04f5dfbacb62de9cf673359791aa9.png)
Command ‘[‘where‘, ‘cl‘]‘ returned non-zero exit status 1.

leetcode:1856. 子数组最小乘积的最大值

Record -- about the method of adding report control to virtual studio2017 -- reportview control
随机推荐
leetcode:85. 最大矩形
Record -- about the method of adding report control to virtual studio2017 -- reportview control
Domain name purchase method good domain name selection principle
About Stacked Generalization
What transmission modes does the IOT data gateway support
The gadgets developed by freshmen are popular. Netizen: my food is good
Word cannot copy and paste processing method
Come on, it's not easy for big factories to do projects!
Overview of new features in mongodb5.0
Code scanning | a sharp tool for controlling code quality
Tencent security apkpecker launched dex-vmp automatic shelling service
Distributed cache breakdown
When easynvs is deployed on the project site, easynvr cannot view the corresponding channel. Troubleshooting
Microsoft Security, which frequently swipes the network security circle, gives us some enlightenment this time?
Papamelon 11 number of calculation permutation [combinatorics]
WordPress pill applet build applet from zero to one [install and configure WordPress site]
In Tencent, my trial period summary
虚拟文件系统
Go current limiting component package rate source code analysis
Basic knowledge of wechat applet cloud development literacy chapter (I) document structure