当前位置:网站首页>Extract the new Chinese cross modal benchmark zero from 5billion pictures and texts, and Qihoo 360's new pre training framework surpasses many SOTAS
Extract the new Chinese cross modal benchmark zero from 5billion pictures and texts, and Qihoo 360's new pre training framework surpasses many SOTAS
2022-06-12 16:45:00 【PaperWeekly】

author | qihoo 360 Artificial Intelligence Research Institute 、 Tsinghua University
source | Almost Human
For the Chinese community , The large-scale cross modal benchmark data set proposed in this paper is undoubtedly very valuable .
Visual language pre training (VLP) Mainly learn the semantic correspondence between vision and natural language . Thanks to massive data 、Transformer And other excellent architectures 、CLIP Cross modal model and hardware equipment support , A series of pioneering work has explored VLP Model , And has made remarkable progress in various visual language tasks .
With the help of large-scale training corpus ( Mainly English ), A number of VLP The model has been shown to be beneficial for downstream tasks . However, there are few Chinese visual language datasets , And there are various limitations . A classic model for large-scale pre training model and fine tuning of downstream tasks , The Chinese cross modal domain lacks a large number of high-quality data , And the pre training data set is completely defined 、 Data benchmark of multiple downstream task training sets and downstream task test sets .
How to build a complete 、 Chinese cross modal benchmark with fair and high-quality text description has become an urgent problem to be solved .
lately , qihoo 360 In their latest papers, researchers from the Institute of artificial intelligence and Tsinghua University focused on large-scale visual language data sets and cross modal representation learning models . The researchers proposed a large-scale Chinese cross modal benchmark data set Zero, It contains two components called Zero-Corpus Pre training data set and five downstream task data sets , To some extent, it fills the gap in the cross modal domain data set of Chinese graphics and text . further , The researchers also proposed a visual language pre training framework R2D2, For large-scale cross modal learning , Based on the proposed Zero-Corpus Data sets for pre training , And test on multiple downstream tasks ,R2D2 Made a number of breakthroughs SOTA Result . The above data sets and models , All of them are open source .
The researchers also tried to use a larger 2.5 Billion internal data set training R2D2 Model , relative 2300 All the data , The effect of the model is still significantly improved . Especially in the zero sample task , Relative to previous SOTA, stay Flickr30k-CN On dataset ,[email protected] Upgrade to 85.6%( Promoted 4.7%), stay COCO-CN On dataset ,[email protected] Upgrade to 80.5%( Promoted 5.4%), stay MUGE On dataset ,[email protected] Upgrade to 69.5%( Promoted 6.3%).

Paper title :
Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework
Thesis link :
https://arxiv.org/pdf/2205.03860.pdf
Code link :
https://github.com/yuxie11/R2D2
Dataset Links :
https://zero.so.com/
Zero-Corpus The pre training data set consists of a set containing 2300 The complete version of the picture and text pair and one containing 230 A smaller subset of ten thousand image and text pairs . among , Complete pre training data sets are collected from search engines , Contains images and corresponding text descriptions , And according to the user click through rate (CTR) from 50 Hundreds of millions of images and texts are filtered . Train on the full version VLP The model may require a lot of GPU resources , Therefore, for the convenience of academic research , The researchers also provided a complete version 10% A subset of a picture text pair 230 Wan version .
In addition to the two pre training datasets , The researchers also provide five high-quality downstream data sets for the tasks of text retrieval and text matching of long and short texts . In particular, it is worth mentioning Flickr30k-CNA, It is a human - translated comparison Flickr30k-CN More accurate data sets , It can be used to compare the effect of Chinese and English cross modal models , It can also be used to study the influence of the quality of translated corpus on the results .
about VLP Model , Researchers have proposed a new pre training framework for cross modal learning R2D2. This framework combines the two tower model with the single tower model , On the basis of image modal representation and text modal representation , Use the cross attention mechanism , Integrate graphic information , And inspired by the technology of recommendation system and online advertising , Use global comparison to pre sort (Global Contrastive Pre-Ranking, GCPR) To get a cross modal representation , Finally, fine-grained sorting is used (Fine-Grained Ranking, FGR) Further improve model performance .
further , The researchers also introduced a two-way distillation method , Including target directed distillation (Target-guided Distillation,TgD) And feature oriented distillation (Feature-guided Distillation,FgD). among , Goal oriented distillation improves the robustness of learning from noise labels , Feature oriented distillation is designed to improve R2D2 The generalization of .

Data set Overview
1.1 Pre training dataset Zero Corpus
There are two main limitations to existing data collection methods . firstly , The correspondence between the images and texts collected only by crawling is weak , There's a lot of noise ; second , Images often contain only one corresponding text , Text data lacks diversity .
To overcome these limitations , Researchers have created a new data set for Chinese text pre training ——Zero Corpus. They are interested in 50 Billion images , Sort by user click , The pictures at the top of the order indicate that the user clicks the most when querying , Explain that the picture is most relevant to the search query text . further , The researchers also deleted inappropriate and harmful text descriptions , And filter out harmful images . The above process , It maximizes the correspondence between image and text data , Filter to get high quality pictures . According to the above methods, the researchers obtained about 2.5 The most relevant and high-quality picture and text pairs , The final random sampling 2300 Ten thousand picture and text pairs are used to build public pre training data sets .
Researchers also provided a variety of text descriptions for each image , Including the title (Title)、 Content (Content) And image query words (ImageQuery) etc. . This information contains multiple texts , Can be used to build different cross modal tasks , It is convenient to model and study the cross modal relationship between graphics and text more comprehensively . The following figure shows some specific examples .

▲ Zero-Corpus Examples of picture text pairs
1.2 Downstream data sets
To evaluate the performance of the pre training model , Most of the work will be done on various downstream data sets . Compared with the existing downstream datasets with English descriptions , Few downstream datasets with Chinese text .
So , The researchers constructed four Chinese graphic data sets , Namely ICM、IQM、ICR and IQR. On the basis of pre training data processing ( Sorted by hits , And quality content filtering ), Further, manually label these downstream tasks , Ensure the accuracy of data . For each downstream task dataset , according to 8:1:1 The training set is divided into two parts 、 Validation set and test set . Different from the pre training data , Data sets for these downstream tasks , Each image retains only one corresponding text .
Image title matching dataset (Image-Caption Matching Dataset, ICM) It is used for long text text matching and classification tasks . Each image has a corresponding title text , Describe the image in detail . The researchers first used CTR Select the most relevant pair , Then calibrate by manual marking , We have gained 40 Ten thousand picture and text pairs , Include 20 Ten thousand positive samples and 20 Ten thousand counter samples .
Image query matching data set (Image-Query Matching Dataset, IQM) It is used for short text text matching and classification tasks . And ICM Data collection methods are similar , Instead of detailed description text, a search query is used .IQM Also contains 20 Ten thousand positive samples and 20 Ten thousand counter samples .
Image title retrieval dataset (Image-Caption Retrieval Dataset, ICR) It is used for long text mutual inspection . The researchers used the same method as ICM The same rules collect 20 Ten thousand picture and text pairs .
Image query retrieval dataset (Image-Query Retrieval Dataset, IQR) It is used for short text mutual inspection . The researchers used the same method as IQM The same rules collect 20 Ten thousand picture and text pairs .

From left to right ICM、IQM、ICR and IQR Examples of graphics and text in a dataset .
Previous Flickr30k-CN Translated with machinetranslation Flickr30k Training set and verification set , But there are two kinds of problems in the results of machinetranslation . One side , There are some translation errors in some sentences ; On the other hand , The Chinese meaning of some sentences is not smooth .
therefore , The researcher invited six Chinese and English linguists to retranslate Flickr30k All data for , And double check each sentence , Finally, a new data set is generated Flickr30k-Chinese All(Flickr30k-CNA), Used for cross modal task evaluation .

▲ Flickr30k、Flickr30k-CN And the Flickr30k-CNA Example comparison of

Methods an overview
2.1 Model architecture
The figure below 1 by R2D2 An overview of the architecture of the pre training framework , It contains a text encoder 、 One image encoder and two cross encoders . among , Text encoder and image encoder convert text and image into a sequence of hidden states respectively . then , The text and image hiding states interact with each other in two cross encoders through cross attention .

Researchers use RoBERTa As a text encoder . Given a sequence of text , They use it first RoBERTa-wwm-ext Of tokenizer Conduct tokenize Handle . ad locum , special [CLS] token Attached to tokenized Textual head, meanwhile [SEP] token Attached to tail. then ,tokenized The text is input into the text encoder .
Researchers use ViT As an image encoder . They first scale the input image to standard size , And divide the image into multiple patch. Then each patch Do linear mapping and add positional embedding . Besides , A learnable [CLS] token And patch Vector concatenation . Last , The sequence vector is input into the standard Transformer Model to get the image hidden state vector .
Researchers fuse the image and text hidden vectors and input them into the cross coder . say concretely , They use a linear mapping layer to change the dimensions of each text feature and image feature to make them consistent . Multi-storey Transformer With the help of cross attention, the characteristic information of the two modes is fused , And produce the final cross modal output .
2.2 Pre training methods
In order to explore the matching relationship between picture and text pairs , The researchers designed a preorder + Sorting mechanism , That is, global comparison pre sorting (GCPR) And fine-grained sorting (FGR). They also use mask language to model (MLM) Effectively learn the representation of cross modal models .
The first is the global comparison preorder . Traditional contrastive learning aims to align the representation of multimodal data ( Such as paired pictures and texts ), It maximizes the similarity score of positive pairs and minimizes the score of negative pairs . Researchers use global contrast learning to complete the pre - sorting task , They are k individual GPU Perform complete back propagation on . For each image And the corresponding text , Graphics and text softmax The normalized similarity score can be defined as follows :

Global comparison pre ordering loss through cross entropy loss To calculate , The following formula (2) Shown :

Then there is fine-grained sorting . As mentioned above , Researchers use global comparison preorder to obtain a single representation of images and text . Based on these representations , Further, fine-grained sorting tasks are performed with the help of fine-grained sorting losses . This is a binary classification task , To predict whether the picture and text match .
The researchers will and As the output of two cross encoders . Given an image representation And a text representation , Researchers input them into a full connectivity layer To get their respective prediction probabilities . Make y Expressed as a binary classification ground-truth label , The researchers calculated the fine-grained sorting loss as follows .
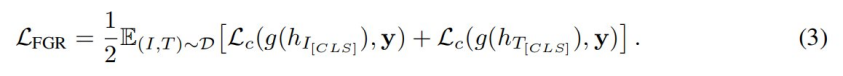
The researchers apply mask language modeling loss to text graph cross coder , To improve in token Level the ability to model the relationship between text and images .15% The text of token Masked in input , All of these token Replaced with [MASK] token.
In the researcher's model , The mask language modeling task uses the mask text and the corresponding image to denoise , Thus, the interaction between text and image is enhanced . Because fine-grained sorting relies heavily on this interactive capability , Therefore, the researchers proposed the reinforcement training (ET), It integrates the modeling task of mask language into the fine-grained sorting forward operation of forward picture text pairs .
2.3 Two way distillation
Most of the pre training data are collected by semi-automatic program , Thus, the data is noisy . Inaccurate labeling may mislead model training . So , The researchers proposed target oriented distillation (TgD), A teacher based approach with soft goals - Students' distillation . In order to further improve the generalization performance of the pre training model , The researchers introduced characteristic directed distillation (FgD). For convenience , They call the combination of these two kinds of distillation bidirectional distillation (TwD).
Target oriented distillation : To reduce the risk of learning from noise tags , The researchers suggest that the soft target generated by the momentum update encoder (soft target). here , Momentum update encoder as a teacher model of distillation , From the exponential moving average weight .
The researcher passes the coefficient Score the similarity s(·,·) And one-hot label y(·,·) Combination , To produce the final soft label . take and Express as final soft label . With For example , Can be defined as :

Considering that the effectiveness of the features in the queue decreases with the increase of the time step , The researchers also maintained a weighted cohort w To mark the reliability of the corresponding location feature . say concretely , In addition to the newly transferred items , Each iteration of the study decays each element in the queue 0.99 times . therefore , The researchers will Replace with equation 2 Weighted cross entropy loss in . Use target directed distillation , Defined as :

Feature oriented distillation : And TgD similar , The researchers used teachers - Students' paradigm carries out feature oriented distillation . Take the text encoder as an example , The student model is a text coder , The teacher model is an encoder updated by momentum .
In order to further improve the performance of the model , The researchers used a mask strategy for the input . In the implementation , Provide complete input to the teacher model , Provide masked input to students . Depending on the momentum mechanism , The goal is to bring the characteristics of students closer to those of teachers . Formally , The predicted distributions of the teacher and student models are defined as follows :

The researchers used the cross entropy loss to carry out characteristic oriented distillation , Loss Defined as :

Finally, the model is trained with the overall pre training target :


experimental result
From the table below 2 It can be seen that , The model proposed by the researchers surpasses the previous one in most tasks SOTA, Even if only 2.3M sample ( about Wukong Data size 2.3%) The same goes for training . Yes 23M When the sample is pre trained , The results are better . At the model level ,R2D2ViT-L Also better than... In all data sets R2D2ViT-B, It shows that as the pre training model becomes larger , The algorithm will be better .

The researchers also conducted experiments on the proposed downstream data sets , These experimental results become the baseline of the proposed data set . Specially , stay Flickr30k-CNA When experimenting on , Researchers use Flickr30k-CNA Training set fine tuning pre training model , And in Flickr30k-CN For fair comparison . From the table 2 It can be seen that , stay Flickr30k-CNA Fine tuned R2D2 Better than in Flickr30k-CN Fine tuned R2D2, Because of human translation Flickr30k-CNA The quality of is much higher than that of machinetranslation Flickr30k-CN.
Different from image and text retrieval , Picture and text matching in Chinese (ITM) There are very few data sets for the task . The researchers put forward a proposal for Chinese ITM The image title of the task matches the dataset (ICM) Matching data sets with image queries (IQM), The corresponding results are given .
The researchers used AUC As an evaluation indicator . From the table below 1 It can be seen that ,R2D2ViT-L Than R2D2ViT-B Better results . Besides ,R2D2ViT-L (23M) stay ICM and IQM The performance is better than R2D2ViT-L (2.3M) Above the limit 4.97% 、5.68%. This means that more Chinese high-quality data can be improved R2D2 Generalization ability .
To further improve performance , The researchers used from 50 Billion samples 2.5 100 million picture and text pairs for pre training . From the table 2 It can be seen that , With the most comprehensive evaluation index [email protected] To measure , The model is in Flickr30k-CN、COCO-CN、AIC-ICC、MUGE、Flickr30k-CNA、ICR、IQR And all the results of the data set exceed 23M Data training model , This means that increasing the amount of data can enhance the ability of the pre training model . meanwhile , These results also significantly exceed those disclosed by public results WenLan2.0 as well as WuKong Result , Become the latest SOTA. The following table 1 The data in shows the picture and text matching task ICM、IQM in , The pre training model trained with more data will achieve better results .

To show the role of each mechanism , Researchers at Zero-Corpus On a subset of (230 Wan graphic pre training data ) Perform ablation experiments . For convenience , In the ablation experiment, the researchers will R2D2ViT-L Defined as R2D2.
Fine grained sorting (FGR) The effect of . First , The researchers used global comparison to pre sort (GCPR) And two-way distillation (TwD) Training models , And defined as PRD2.PRD2 The setting of is similar to CLIP. From the table below 3 You can see in the first and second lines of ,R2D2 The performance of image and text retrieval task is significantly better than PRD2, It can be inferred that the result is significantly better than CLIP, This illustrates the proposed global comparison preorder + The effectiveness of the fine-grained sorting framework .
Strengthen your training (ET) The effect of . The researchers compared the results after removing reinforcement training . From the table below 3 You can see in the third line of ,R2D2 ( belt ET) Make... On the task of image and text retrieval [email protected] Improved 0.95%,AUC from 80.27% Up to 80.51%.R2D2 Another advantage of is that it is better than R2D2 w/o ET Use less computing resources .R2D2 need 154.0 GFLOPs Amount of computation , To be able to 1.4 Run at the speed of iterations , Without intensive training R2D2 You need to 168.8 GFLOPs Amount of computation , Only... Can be run per second 1.1 Sub iteration . The above results prove the effectiveness of reinforcement training .
Effect of two-way distillation . The two-way distillation proposed by the researchers includes target oriented distillation and characteristic oriented distillation . When removing bidirectional distillation (TwD) when ,[email protected] from 74.06% drop to 73.10%,AUC from 80.51% drop to 80.31%. When removing feature directed distillation (FgD) when ,[email protected] from 74.06% drop to 73.29%, Obvious performance degradation , It shows that feature alignment is very important in training . meanwhile , Remove target directed distillation (TgD) It will also lead to the performance degradation of the model . The above results show that bidirectional distillation is an effective method to improve the generalization of the pre training model .

Zero sample task . In order to prove the generalization performance of the model , The researchers also conducted a zero sample transfer experiment . From the table below 4 It can be seen that , And current SOTA The performance of the WukongViT-L comparison ,R2D2ViT-L(23M) Less than 1/4 The data of , But in the Flickr30k-CN、COCO-CN Better performance has been achieved on . When introducing 2.5 Billion level of pre training data ,R2D2 The accuracy of is further improved , relative WukongViT-L, stay Flickr30k-CN On dataset ,[email protected] Upgrade to 85.6%( Promoted 4.7%), stay COCO-CN On dataset ,[email protected] Upgrade to 80.5%( Promoted 5.4%), stay MUGE On dataset ,[email protected] Upgrade to 69.5%( Promoted 6.3%).

Entity based image attention visualization . In this experiment , The researchers tried to COCO-CN Visual image on the attention . say concretely , They first extract an entity from the Chinese text , And calculate the attention score of image and entity pairs . The figure below 2 It shows the visual interpretation of four different entities on the image . This shows that R2D2 You've learned to align text with the correct content in the image .

Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
- Canvas advanced functions (Part 2)
- Joint recruitment notice of ganfei research group of Wuhan University and xuzhenjiang research group of Nanchang University
- std::set compare
- PostgreSQL source code (53) plpgsql syntax parsing key processes and function analysis
- \Begin{algorithm} notes
- generate pivot data 1
- 【树莓派】:(四)Camera 进阶
- h t fad fdads
- Probation period and overtime compensation -- knowledge before and after entering the factory labor law
- acwing 790. The cubic root of a number (floating-point number in half)
猜你喜欢

The process of "unmanned aquaculture"
![[MySQL] Cartesian product - multi table query (detailed explanation)](/img/46/6a9a62b35eaa538232da1d738b3931.jpg)
[MySQL] Cartesian product - multi table query (detailed explanation)

generate pivot data 0

pbootcms的if判断失效直接显示标签怎么回事?

Leetcode 2194. Excel 錶中某個範圍內的單元格(可以,已解决)
![[Hunan University] information sharing of the first and second postgraduate entrance examinations](/img/15/298ea6f7367741e1e085007c498e51.jpg)
[Hunan University] information sharing of the first and second postgraduate entrance examinations

acwing 790. The cubic root of a number (floating-point number in half)

How to base on CCS_ V11 new tms320f28035 project

MySQL interview arrangement
Leetcode 2194. Cellules dans une plage dans un tableau Excel (OK, résolu)
随机推荐
Probation period and overtime compensation -- knowledge before and after entering the factory labor law
Understand go modules' go Mod and go sum
从50亿图文中提取中文跨模态新基准Zero,奇虎360全新预训练框架超越多项SOTA
Anfulai embedded weekly report no. 268: May 30, 2022 to June 5, 2022
MySQL - server configuration related problems
Leetcode 2194. Excel 錶中某個範圍內的單元格(可以,已解决)
深入理解 Go Modules 的 go.mod 與 go.sum
34-【go】Golang channel知识点
Project training of Shandong University rendering engine system (III)
Postgresql错误码是如何构造的
idea如何设置导包不带*号
generate pivot data 2
generate pivot data 2
<山东大学项目实训>渲染引擎系统(七)
\begin{algorithm} 笔记
890. find and replace mode / Sword finger offer II 080 Combination with k elements
【树莓派】:(四)Camera 进阶
Three paradigms of database
canvas 高级功能(下)
CVPR 2022 | 元学习在图像回归任务的表现