当前位置:网站首页>IDEA 中使用 Hudi
IDEA 中使用 Hudi
2022-07-03 09:21:00 【小胡今天有變强嗎】
環境准備
- 創建 Maven 項目
- 創建服務器遠程連接
Tools------Delployment-----Browse Remote Host
設置如下內容: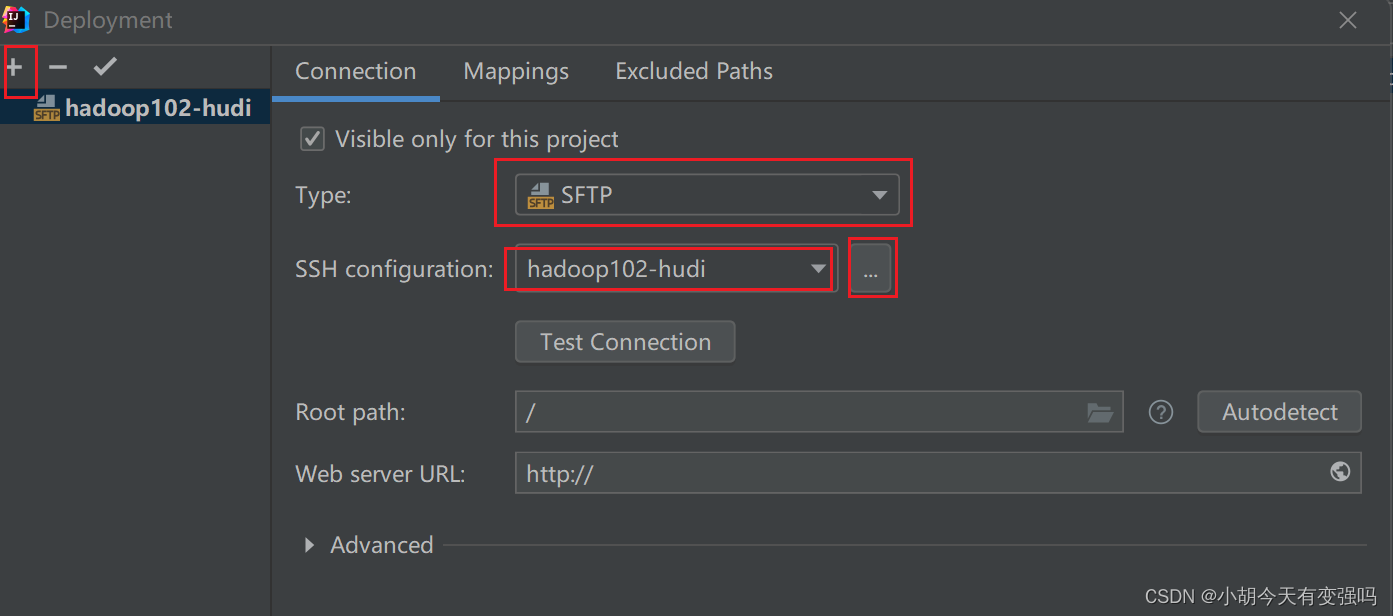
在這裏輸入服務器的賬號和密碼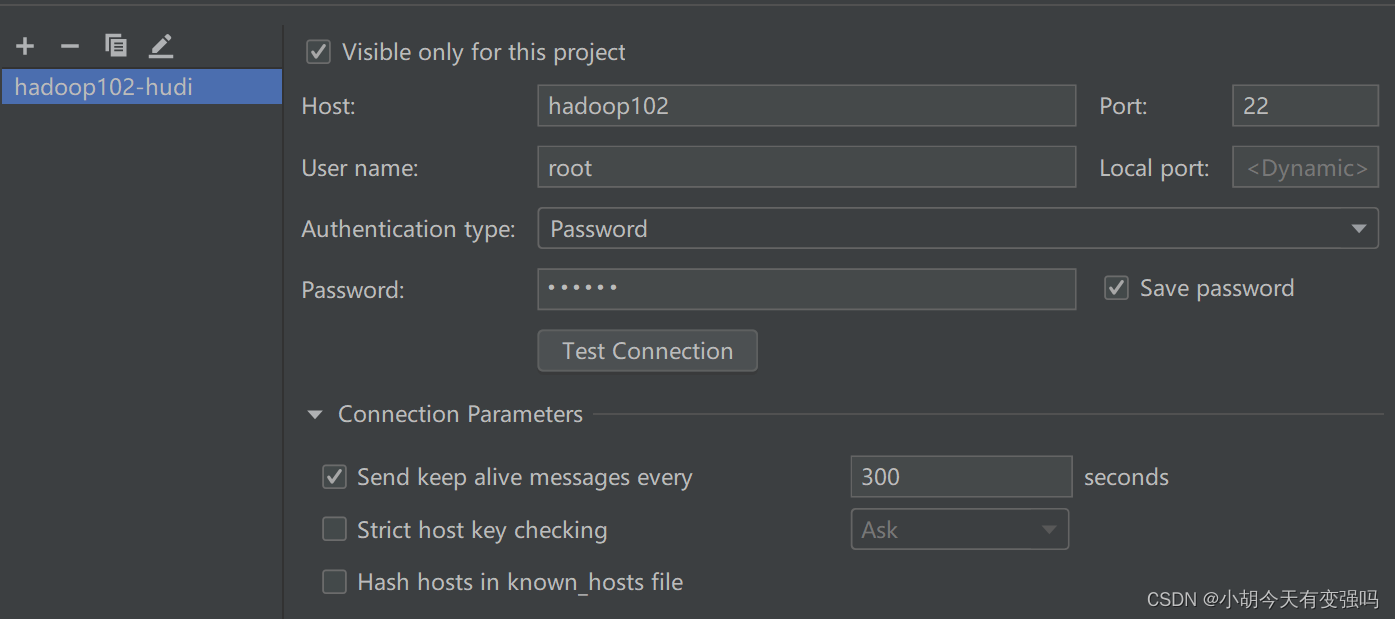
點擊Test Connection,提示Successfully的話,就說明配置成功。
- 複制Hadoop的 core-site.xml、hdfs-site.xml 以及 log4j.properties 三個文件複制到resources文件夾下。
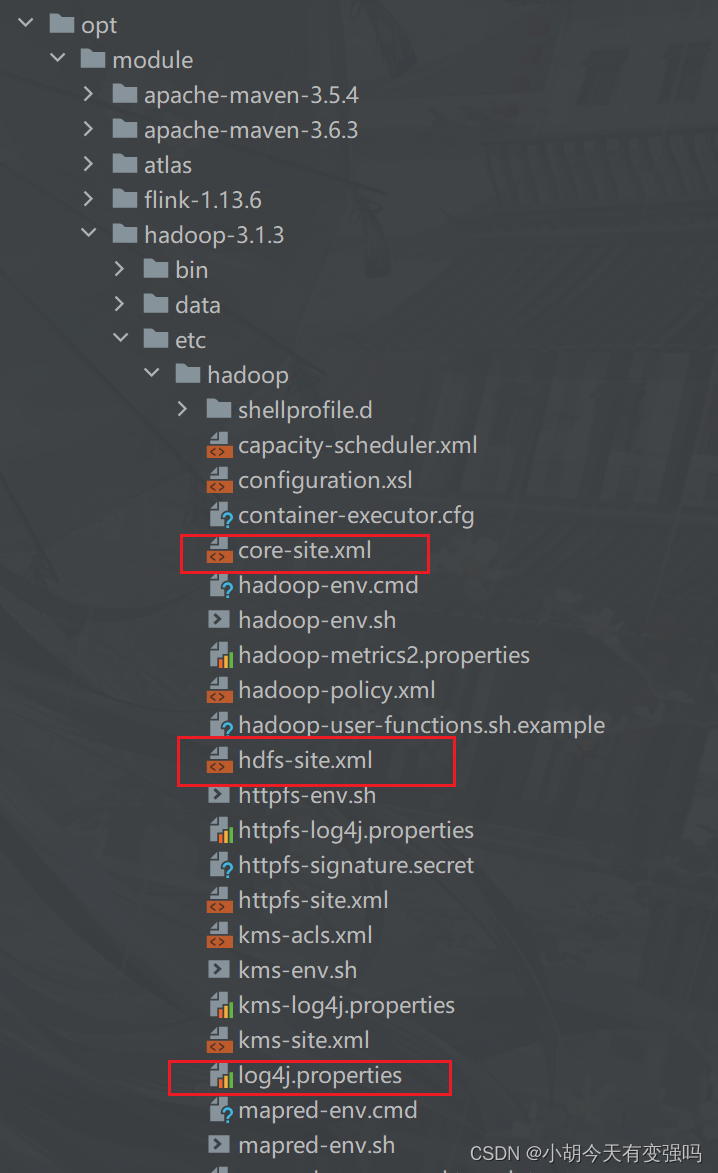
設置 log4j.properties 為打印警告异常信息:
log4j.rootCategory=WARN, console
- 添加 pom.xml 文件
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.0.0</spark.version>
<hadoop.version>2.7.3</hadoop.version>
<hudi.version>0.9.0</hudi.version>
</properties>
<dependencies>
<!-- 依賴Scala語言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依賴 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依賴 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依賴 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- hudi-spark3 -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark3-bundle_2.12</artifactId>
<version>${hudi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 編譯的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
要注釋掉創建項目時的生成的下面的代碼,不然依賴一直報錯:
<!-- <properties>-->
<!-- <maven.compiler.source>8</maven.compiler.source>-->
<!-- <maven.compiler.target>8</maven.compiler.target>-->
<!-- </properties>-->
代碼結構: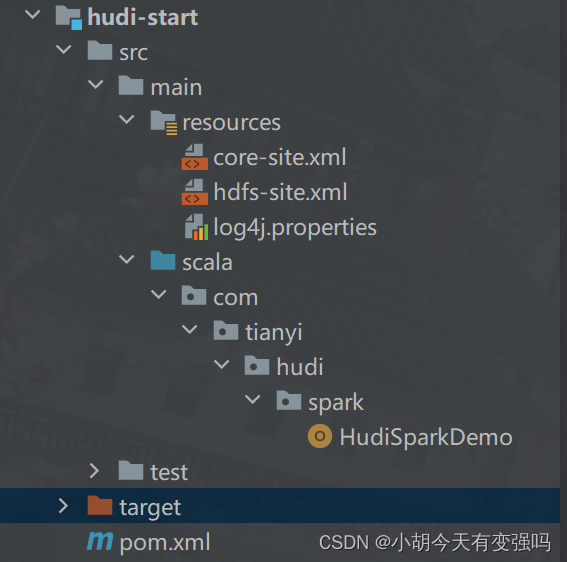
核心代碼
import org.apache.hudi.QuickstartUtils.DataGenerator
import org.apache.spark.sql.{
DataFrame, SaveMode, SparkSession}
/** * Hudi 數據湖的框架,基於Spark計算引擎,對數據進行CURD操作,使用官方模擬賽生成的出租車出行數據 * * 任務一:模擬數據,插入Hudi錶,采用COW模式 * 任務二:快照方式查詢(Snapshot Query)數據,采用DSL方式 * 任務三:更新(Update)數據 * 任務四:增量查詢(Incremental Query)數據,采用SQL方式 * 任務五:删除(Delete)數據 */
object HudiSparkDemo {
/** * 官方案例:模擬產生數據,插入Hudi錶,錶的類型為COW */
def insertData(spark: SparkSession, table: String, path: String): Unit = {
import spark.implicits._
// 第1步、模擬乘車數據
import org.apache.hudi.QuickstartUtils._
val dataGen: DataGenerator = new DataGenerator()
val inserts = convertToStringList(dataGen.generateInserts(100))
import scala.collection.JavaConverters._
val insertDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(inserts.asScala, 2).toDS()
)
// insertDF.printSchema()
// insertDF.show(10, truncate = false)
//第二步: 插入數據到Hudi錶
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
insertDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.insert.shuffle.parallelism", 2)
//Hudi錶的屬性設置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
/** * 采用Snapshot Query快照方式查詢錶的數據 */
def queryData(spark: SparkSession, path: String): Unit = {
import spark.implicits._
val tripsDF: DataFrame = spark.read.format("hudi").load(path)
// tripsDF.printSchema()
// tripsDF.show(10, truncate = false)
//查詢費用大於10,小於50的乘車數據
tripsDF
.filter($"fare" >= 20 && $"fare" <=50)
.select($"driver", $"rider", $"fare", $"begin_lat", $"begin_lon", $"partitionpath", $"_hoodie_commit_time")
.orderBy($"fare".desc, $"_hoodie_commit_time".desc)
.show(20, truncate = false)
}
def queryDataByTime(spark: SparkSession, path: String):Unit = {
import org.apache.spark.sql.functions._
//方式一:指定字符串,按照日期時間過濾獲取數據
val df1 = spark.read
.format("hudi")
.option("as.of.instant", "20220610160908")
.load(path)
.sort(col("_hoodie_commit_time").desc)
df1.printSchema()
df1.show(numRows = 5, truncate = false)
//方式二:指定字符串,按照日期時間過濾獲取數據
val df2 = spark.read
.format("hudi")
.option("as.of.instant", "2022-06-10 16:09:08")
.load(path)
.sort(col("_hoodie_commit_time").desc)
df2.printSchema()
df2.show(numRows = 5, truncate = false)
}
/** * 將DataGenerator作為參數傳入生成數據 */
def insertData(spark: SparkSession, table: String, path: String, dataGen: DataGenerator): Unit = {
import spark.implicits._
// 第1步、模擬乘車數據
import org.apache.hudi.QuickstartUtils._
val inserts = convertToStringList(dataGen.generateInserts(100))
import scala.collection.JavaConverters._
val insertDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(inserts.asScala, 2).toDS()
)
// insertDF.printSchema()
// insertDF.show(10, truncate = false)
//第二步: 插入數據到Hudi錶
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
insertDF.write
//更換為Overwrite模式
.mode(SaveMode.Overwrite)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", 2)
.option("hoodie.insert.shuffle.parallelism", 2)
//Hudi錶的屬性設置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
/** * 模擬產生Hudi錶中更新數據,將其更新到Hudi錶中 */
def updateData(spark: SparkSession, table: String, path: String, dataGen: DataGenerator):Unit = {
import spark.implicits._
// 第1步、模擬乘車數據
import org.apache.hudi.QuickstartUtils._
//產生更新的數據
val updates = convertToStringList(dataGen.generateUpdates(100))
import scala.collection.JavaConverters._
val updateDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(updates.asScala, 2).toDS()
)
// TOOD: 第2步、插入數據到Hudi錶
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
updateDF.write
//追加模式
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 錶的屬性值設置
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
}
/** * 采用Incremental Query增量方式查詢數據,需要指定時間戳 */
def incrementalQueryData(spark: SparkSession, path: String): Unit = {
import spark.implicits._
// 第1步、加載Hudi錶數據,獲取commit time時間,作為增量查詢數據閾值
import org.apache.hudi.DataSourceReadOptions._
spark.read
.format("hudi")
.load(path)
.createOrReplaceTempView("view_temp_hudi_trips")
val commits: Array[String] = spark
.sql(
""" |select | distinct(_hoodie_commit_time) as commitTime |from | view_temp_hudi_trips |order by | commitTime DESC |""".stripMargin
)
.map(row => row.getString(0))
.take(50)
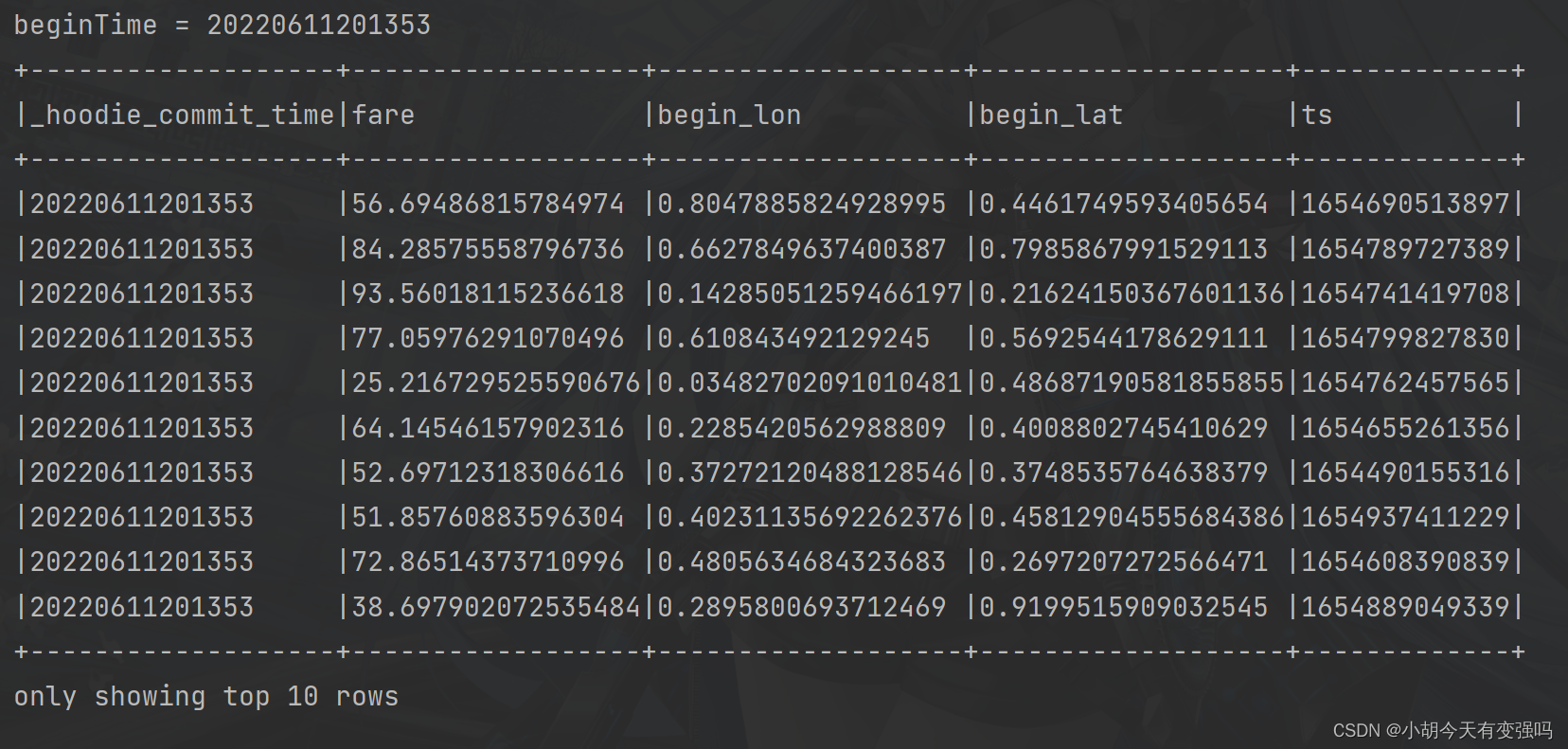
val beginTime = commits(commits.length - 1) // commit time we are interested in
println(s"beginTime = ${
beginTime}")
// 第2步、設置Hudi數據CommitTime時間閾值,進行增量數據查詢
val tripsIncrementalDF = spark.read
.format("hudi")
// 設置查詢數據模式為:incremental,增量讀取
.option(QUERY_TYPE.key(), QUERY_TYPE_INCREMENTAL_OPT_VAL)
// 設置增量讀取數據時開始時間
.option(BEGIN_INSTANTTIME.key(), beginTime)
.load(path)
// 第3步、將增量查詢數據注册為臨時視圖,查詢費用大於20數據
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
spark
.sql(
""" |select | `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts |from | hudi_trips_incremental |where | fare > 20.0 |""".stripMargin
)
.show(10, truncate = false)
}
/** * 删除Hudi錶數據,依據主鍵uuid進行删除,如果是分區錶,指定分區路徑 */
def deleteData(spark: SparkSession, table: String, path: String): Unit = {
import spark.implicits._
// 第1步、加載Hudi錶數據,獲取條目數
val tripsDF: DataFrame = spark.read.format("hudi").load(path)
println(s"Raw Count = ${
tripsDF.count()}")
// 第2步、模擬要删除的數據,從Hudi中加載數據,獲取幾條數據,轉換為要删除數據集合
val dataframe = tripsDF.limit(2).select($"uuid", $"partitionpath")
import org.apache.hudi.QuickstartUtils._
val dataGenerator = new DataGenerator()
val deletes = dataGenerator.generateDeletes(dataframe.collectAsList())
import scala.collection.JavaConverters._
val deleteDF = spark.read.json(spark.sparkContext.parallelize(deletes.asScala, 2))
// 第3步、保存數據到Hudi錶中,設置操作類型:DELETE
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
deleteDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// 設置數據操作類型為delete,默認值為upsert
.option(OPERATION.key(), "delete")
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), table)
.save(path)
// 第4步、再次加載Hudi錶數據,統計條目數,查看是否减少2條數據
val hudiDF: DataFrame = spark.read.format("hudi").load(path)
println(s"Delete After Count = ${
hudiDF.count()}")
}
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","hty")
//創建SparkSession示例對象,設置屬性
val spark: SparkSession = {
SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
// 設置序列化方式:Kryo
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
}
//定義變量:錶名稱、保存路徑
val tableName: String = "tbl_trips_cow"
val tablePath: String = "/hudi_warehouse/tbl_trips_cow"
//構建數據生成器,模擬產生業務數據
import org.apache.hudi.QuickstartUtils._
//任務一:模擬數據,插入Hudi錶,采用COW模式
//insertData(spark, tableName, tablePath)
//任務二:快照方式查詢(Snapshot Query)數據,采用DSL方式
//queryData(spark, tablePath)
//queryDataByTime(spark, tablePath)
// 任務三:更新(Update)數據,第1步、模擬產生數據,第2步、模擬產生數據,針對第1步數據字段值更新,
// 第3步、將數據更新到Hudi錶中
val dataGen: DataGenerator = new DataGenerator()
//insertData(spark, tableName, tablePath, dataGen)
//updateData(spark, tableName, tablePath, dataGen)
//任務四:增量查詢(Incremental Query)數據,采用SQL方式
//incrementalQueryData(spark, tablePath)
//任務五:删除(Delete)數據
deleteData(spark, tableName,tablePath)
//應用結束,關閉資源
spark.stop()
}
}
測試
執行 insertData(spark, tableName, tablePath) 方法後對其用快照查詢的方式進行查詢:
queryData(spark, tablePath)

增量查詢(Incremental Query)數據:
incrementalQueryData(spark, tablePath)
參考資料
https://www.bilibili.com/video/BV1sb4y1n7hK?p=21&vd_source=e21134e00867aeadc3c6b37bb38b9eee
边栏推荐
- 【点云处理之论文狂读前沿版12】—— Adaptive Graph Convolution for Point Cloud Analysis
- Education informatization has stepped into 2.0. How can jnpf help teachers reduce their burden and improve efficiency?
- Vs2019 configuration opencv3 detailed graphic tutorial and implementation of test code
- 2022-2-13 learning xiangniuke project - version control
- Go language - JSON processing
- The method of replacing the newline character '\n' of a file with a space in the shell
- 精彩回顾|I/O Extended 2022 活动干货分享
- AcWing 785. Quick sort (template)
- CSDN markdown editor help document
- Computing level network notes
猜你喜欢

Jenkins learning (III) -- setting scheduled tasks
传统办公模式的“助推器”,搭建OA办公系统,原来就这么简单!

【点云处理之论文狂读经典版9】—— Pointwise Convolutional Neural Networks
![[set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)](/img/fd/c0f885cdd17f1d13fdbc71b2aea641.jpg)
[set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)
AcWing 787. Merge sort (template)

LeetCode 715. Range module
![[point cloud processing paper crazy reading frontier version 10] - mvtn: multi view transformation network for 3D shape recognition](/img/94/2ab1feb252dc84c2b4fcad50a0803f.png)
[point cloud processing paper crazy reading frontier version 10] - mvtn: multi view transformation network for 3D shape recognition
![[point cloud processing paper crazy reading classic version 14] - dynamic graph CNN for learning on point clouds](/img/7d/b66545284d6baea2763fd8d8555e1d.png)
[point cloud processing paper crazy reading classic version 14] - dynamic graph CNN for learning on point clouds

教育信息化步入2.0,看看JNPF如何帮助教师减负,提高效率?

What is an excellent fast development framework like?
随机推荐
Beego learning - Tencent cloud upload pictures
MySQL installation and configuration (command line version)
What are the stages of traditional enterprise digital transformation?
浅谈企业信息化建设
LeetCode 438. 找到字符串中所有字母异位词
【点云处理之论文狂读前沿版8】—— Pointview-GCN: 3D Shape Classification With Multi-View Point Clouds
We have a common name, XX Gong
LeetCode 30. Concatenate substrings of all words
教育信息化步入2.0,看看JNPF如何帮助教师减负,提高效率?
The less successful implementation and lessons of RESNET
Instant messaging IM is the countercurrent of the progress of the times? See what jnpf says
即时通讯IM,是时代进步的逆流?看看JNPF怎么说
AcWing 787. Merge sort (template)
The method of replacing the newline character '\n' of a file with a space in the shell
State compression DP acwing 291 Mondrian's dream
Build a solo blog from scratch
[point cloud processing paper crazy reading cutting-edge version 12] - adaptive graph revolution for point cloud analysis
LeetCode 57. 插入区间
2022-2-14 learning xiangniuke project - generate verification code
The difference between if -n and -z in shell