当前位置:网站首页>[multimodal] transferrec: learning transferable recommendation from texture of modality feedback arXiv '22
[multimodal] transferrec: learning transferable recommendation from texture of modality feedback arXiv '22
2022-07-25 12:00:00 【chad_ lee】
《TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback》 Arxiv’22
NLP and CV Domain pre training and large models have become very popular , Come forth BERT、GPT-3、ViT etc. , Realized one4all normal form , That is, a general large model serves almost all downstream tasks . But the development of recommendation system in this direction is slow , The mobility range of the model is limited , It is usually only applicable to the business scenario within a company , It is impossible to achieve portability and versatility in a broad sense .
The article first points out : This is mainly because RS Over reliance on users ID With items ID Information , be based on ID Collaborative filtering paradigm makes RS Break away from complex content modeling , also DL+GCN It makes CF The performance of has experienced a period of improvement , Has dominated the field of recommendation systems . But based on ID Of RS There has been a serious bottleneck in the performance of , Approaching the ceiling , and ID Its unshareable nature leads to almost no migration .
Therefore, it is proposed that ID Back to content-based recommendations , Realization General recommendation system for large-scale mixed mode .
Mixed mode scene

The implementation of general recommendation is based on a common recommendation scenario , That is, the interaction behavior of users' items is determined by ** Mixed mode (MoM: Mixture-of-modality)** Composition of items , The object of user interaction can be text (text) form , Vision (vision)( Images / Video etc. ) form , Or both modes exist . This paper begins with MoM Of source domain Next pre training model , This allows you to migrate to any domain Downstream tasks of .
The dataset is QQ News recommendation scenario of browser ,7 A record of days .
TransRec

Item Encoder
First item encoder It's pre training BERT and ResNet-18, That is, the yellow and green color block in the above figure .
For the text item i, take word token Sequence t = [ t 1 , t 2 , … , t k ] \boldsymbol{t}=\left[t_{1}, t_{2}, \ldots, t_{k}\right] t=[t1,t2,…,tk] Input BERT, And then pass by self- attention pooling Get the text item The final characterization of :
Z i , t = SelfAtt ( BERT ( t ) ) Z_{i, t}=\operatorname{SelfAtt}(\operatorname{BERT}(\boldsymbol{t})) Zi,t=SelfAtt(BERT(t))
For the picture item i, take ResNet Output. feature map Have a time MLP, Get pictures item The final characterization of :
Z i , v = MLP ( ResNet ( v ) ) . \boldsymbol{Z}_{\boldsymbol{i}, \boldsymbol{v}}=\operatorname{MLP}(\operatorname{ResNet}(\boldsymbol{v})) \text {. } Zi,v=MLP(ResNet(v)).
User Encoder
The user is represented by his item interaction sequence , therefore User Encoder The input of is user interaction item Of embedding, And then use BERT( Write it down as B E R T u BERT_u BERTu) Get the representation of user interaction sequence , As a user embedding, And then item embedding Calculate similarity , there BERT Is one-way , Use the last item The output of as a representation of the sequence :
S u = Z u + P u U u = E u ( S u ) = BERT u ( S u ) \begin{aligned} &\boldsymbol{S}^{u}=\boldsymbol{Z}^{u}+\boldsymbol{P}^{u} \\ &\boldsymbol{U}^{u}=E_{u}\left(\boldsymbol{S}^{u}\right)=\operatorname{BERT}_{\mathrm{u}}\left(\boldsymbol{S}^{u}\right) \end{aligned} Su=Zu+PuUu=Eu(Su)=BERTu(Su)
Training methods
Two stage pre training
User Encoder Preliminary training
Conduct self-monitoring on user encoder pretraining . say concretely , The generation pre training from left to right is used to predict the next in the user interaction sequence item, That is, pre training one-way BERT Use softmax Cross entropy loss as objective function
y ~ t = Softmax ( RELU ( S ′ t W U + b U ) ) L UEP = − ∑ u ∈ U ∑ t ∈ [ 1 , … , n ] ( y t log ( y ~ t ) ) \begin{aligned} &\tilde{\boldsymbol{y}}_{t}=\operatorname{Softmax}\left(\operatorname{RELU}\left(\boldsymbol{S}^{\prime}{ }_{t} \boldsymbol{W}^{\boldsymbol{U}}+\boldsymbol{b}^{\boldsymbol{U}}\right)\right) \\ &\mathcal{L}_{\text {UEP }}=-\sum_{u \in U} \sum_{t \in[1, \ldots, n]}\left(\boldsymbol{y}_{\boldsymbol{t}} \log \left(\tilde{\boldsymbol{y}}_{\boldsymbol{t}}\right)\right) \end{aligned} y~t=Softmax(RELU(S′tWU+bU))LUEP =−u∈U∑t∈[1,…,n]∑(ytlog(y~t))
there W U , b U W^U, b^U WU,bU Then discarded , Because it uses inner product as similarity matching . S ′ t S^{\prime}{ }_{t} S′t It is the representation of sequence .
End-to-End Twin tower training
Training at the same time item encoder and user encoder, The purpose is similar to that of previous hybrid experts , In order to make the characteristics of text and pictures encoder Adapt to the current situation as soon as possible domain. utilize Contrastive Predictive Coding (CPC) Method training , The idea is shown in the figure above , Divide a sequence into two segments , According to the prediction of the previous paragraph, all in the next paragraph item, Therefore, it is the same as the task scenario of collaborative filtering :
L C P C = − ∑ u ∈ U [ ∑ t = n + 1 n + l log ( σ ( r u , t ) ) + ∑ g = 1 j log ( 1 − σ ( r u , g ) ) ] \mathcal{L}_{\mathbf{C P C}}=-\sum_{u \in U}\left[\sum_{t=n+1}^{n+l} \log \left(\sigma\left(\boldsymbol{r}_{\boldsymbol{u}, \boldsymbol{t}}\right)\right)+\sum_{g=1}^{j} \log \left(1-\sigma\left(\boldsymbol{r}_{\boldsymbol{u}, \boldsymbol{g}}\right)\right)\right] LCPC=−u∈U∑[t=n+1∑n+llog(σ(ru,t))+g=1∑jlog(1−σ(ru,g))]
g g g Is a random negative sample .
experiment
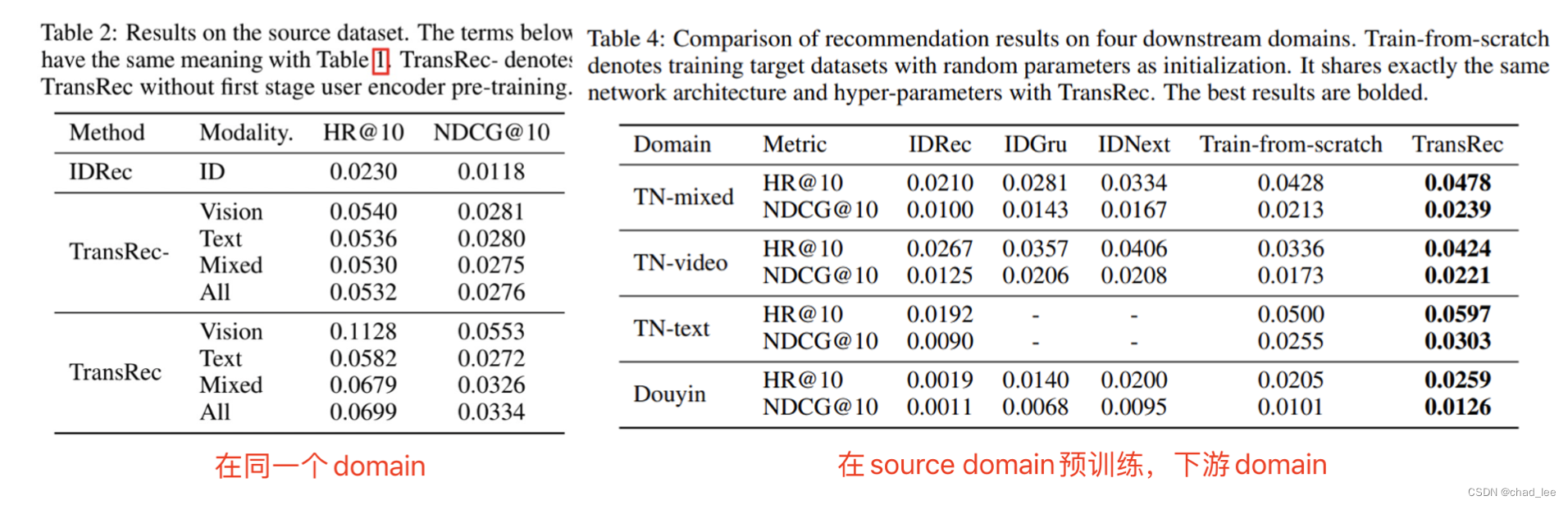
be based on ID The method of domain The effect is not as good as the method based on modal content , Pre training is also better than direct training .
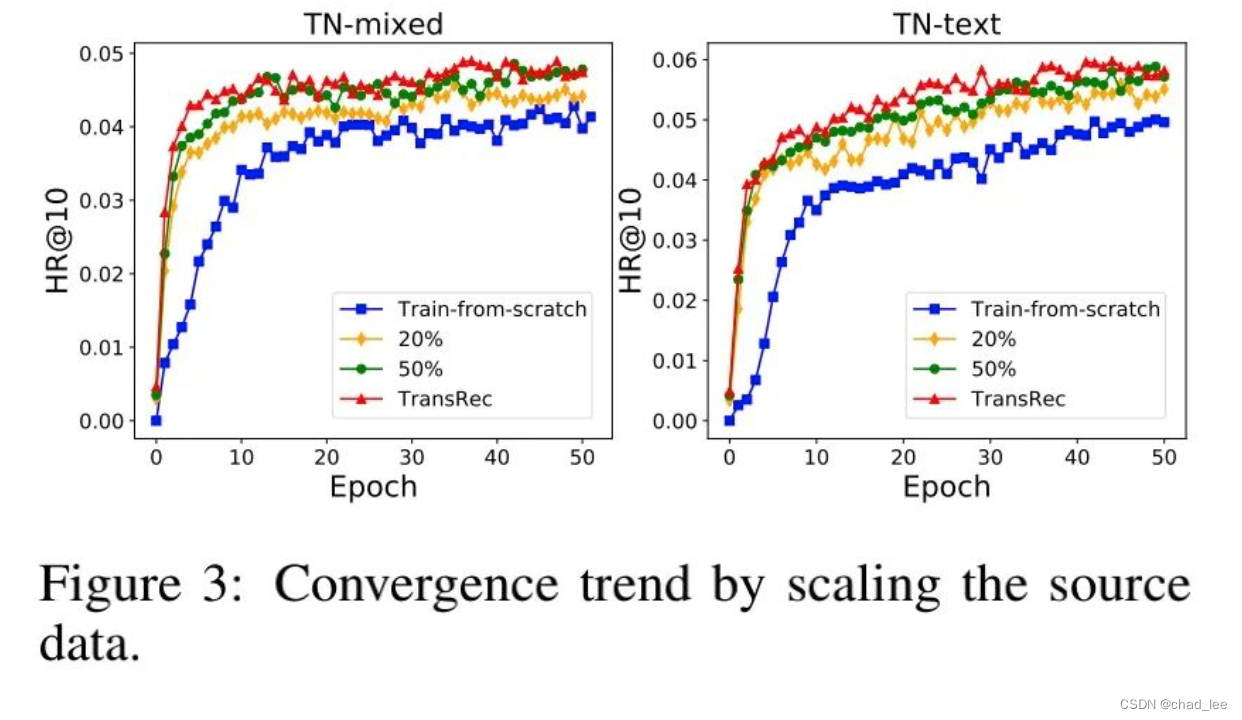
The paper also verifies the upper limit of the data to the model , More pre training data for TransRec The greater the performance improvement of , There is an endless stream of data in industry that can be expanded .
边栏推荐
- Solutions to the failure of winddowns planning task execution bat to execute PHP files
- 微星主板前面板耳机插孔无声音输出问题【已解决】
- Menu bar + status bar + toolbar ==pyqt5
- [high concurrency] Why is the simpledateformat class thread safe? (six solutions are attached, which are recommended for collection)
- Multi-Label Image Classification(多标签图像分类)
- 微信公众号开发 入手
- JS 面试题:手写节流(throttle)函数
- W5500通过上位机控制实现调节LED灯带的亮度
- flink sql client 连接mysql报错异常,如何解决?
- JS数据类型以及相互转换
猜你喜欢

LeetCode 50. Pow(x,n)

软件缺陷的管理

brpc源码解析(五)—— 基础类resource pool详解

Meta-learning(元学习与少样本学习)

任何时间,任何地点,超级侦探,认真办案!

The first C language program (starting from Hello World)

MySQL historical data supplement new data

Differences in usage between tostring() and new string()

PHP curl post x-www-form-urlencoded

Learning to Pre-train Graph Neural Networks(图预训练与微调差异)
随机推荐
PHP uploads the FTP path file to the curl Base64 image on the Internet server
Application and innovation of low code technology in logistics management
[leetcode brush questions]
奉劝那些刚参加工作的学弟学妹们:要想进大厂,这些并发编程知识是你必须要掌握的!完整学习路线!!(建议收藏)
LeetCode 50. Pow(x,n)
JS interview question: handwriting throttle function
[high concurrency] I summarized the best learning route of concurrent programming with 10 diagrams!! (recommended Collection)
'C:\xampp\php\ext\php_ zip. Dll'-%1 is not a valid Win32 Application Solution
知识图谱用于推荐系统问题(MVIN,KERL,CKAN,KRED,GAEAT)
Experimental reproduction of image classification (reasoning only) based on caffe resnet-50 network
GPT plus money (OpenAI CLIP,DALL-E)
程序员送给女孩子的精美礼物,H5立方体,唯美,精致,高清
Review in the middle of 2022 | understand the latest progress of pre training model
Layout management ==pyqt5
小程序image 无法显示base64 图片 解决办法 有效
Brpc source code analysis (VI) -- detailed explanation of basic socket
剑指 Offer 22. 链表中倒数第k个节点
brpc源码解析(六)—— 基础类socket详解
[MySQL learning 09]
pycharm连接远程服务器ssh -u 报错:No such file or directory