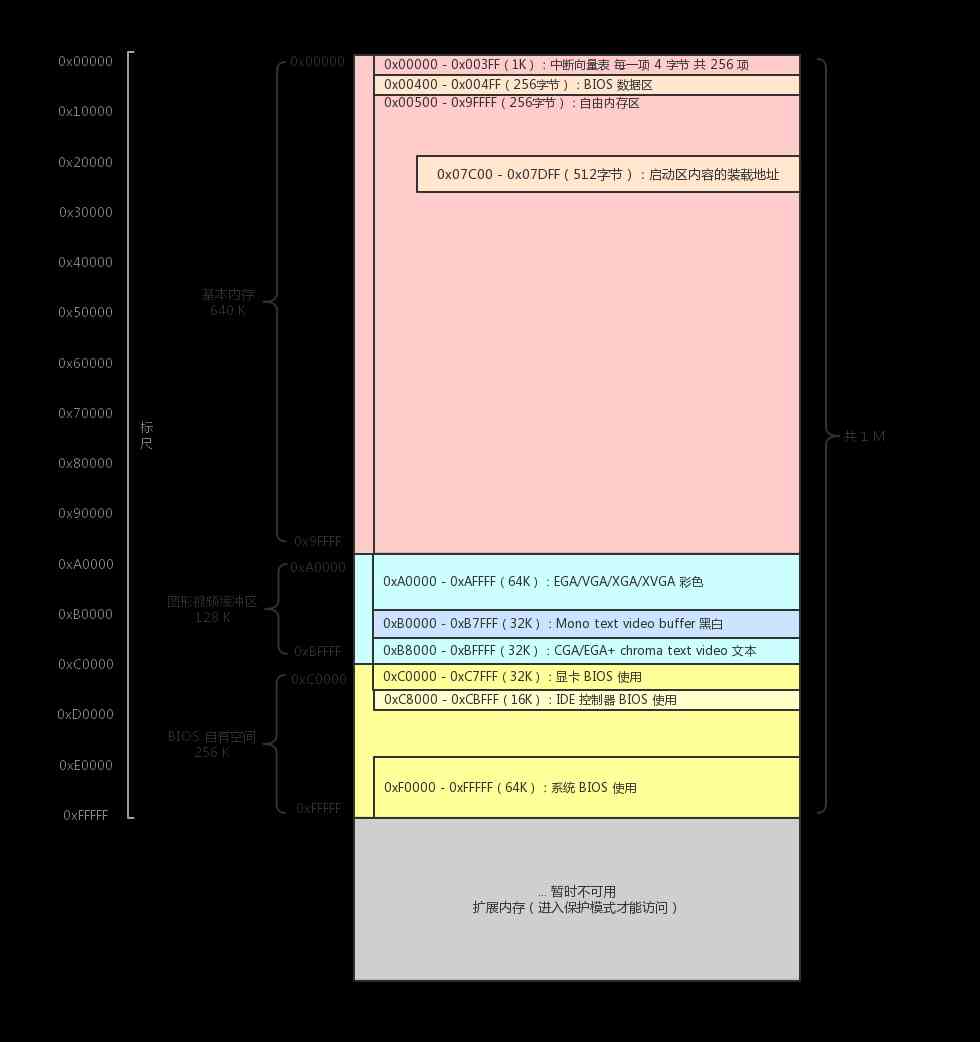
请求日志记录哪些数据
time_local: 请求的时间remote_addr: 客户端的 IP 地址request_method: 请求方法request_schema: 请求协议,常见的 http 和 httpsrequest_host: 请求的域名request_path: 请求的 path 路径request_query: 请求的 query 参数request_size: 请求的大小referer: 请求来源地址,假设你在 a.com 网站下贴了 b.com 的链接,那么当用户从 a.com 点击访问 b.com 的时候,referer 记录的就是 a.com ,这个是浏览器的行为user_agent: 客户端浏览器相关信息status: 请求的响应状态request_time: 请求的耗时bytes_sent: 响应的大小
很多时候我们会使用负载网关去代理转发请求给实际的后端服务,这时候请求日志还会包括以下数据:
upstream_host: 代理转发的 hostupstream_addr: 代理转发的 IP 地址upstream_url: 代理转发给服务的 urlupstream_status: 上游服务返回的 statusproxy_time: 代理转发过程中的耗时
数据衍生
客户端 IP 地址可以衍生出以下数据:
asn 相关信息:
asn_asn: 自治系统编号,IP 地址是由自治系统管理的,比如中国联通上海网就管理了所有上海联通的IPas_org: 自治系统组织,比如中国移动、中国联通
geo 地址位置信息:
geo_location: 经纬度geo_country: 国家geo_country_code: 国家编码geo_region: 区域(省份)geo_city: 城市
user_agent 可以解析出以下信息:
ua_device: 使用设备ua_os: 操作系统ua_name: 浏览器
数据分析
PV/QPS: 页面浏览次数 / 每秒请求数UV: 访问的用户人数,很多网站用户无序登录也能访问,这时可以根据 IP + user_agent 的唯一性确定用户IP数 : 访问来源有多少个 IP 地址
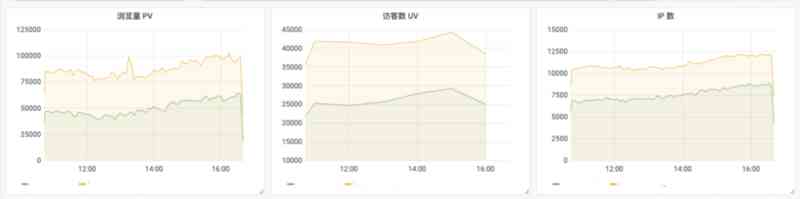
<br/>
- 网络流量 : 根据
request_size请求的大小计数网络流入流量,bytes_sent响应大小计算网络流出流量
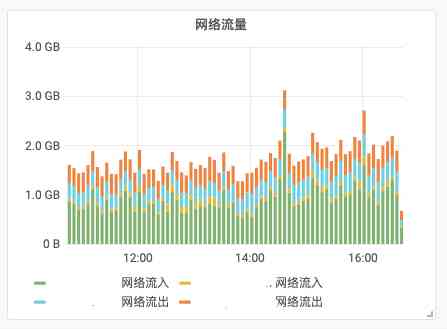
<br/>
referer来源分析

<br/>
- 客户请求的地理位置分析:根据 IP 地址衍生的
geo数据


<br/>
- 客户设备分析:根据
user_agent提取数据
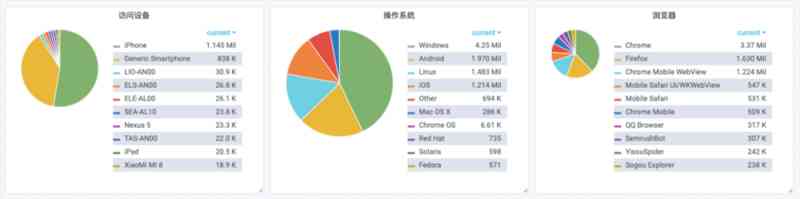
<br/>
请求耗时统计:根据
request_time数据- p99、p95、p90 延迟(前多少百分比请求的耗时,比如 p99 就是前 99% 请求的耗时)
- 长耗时异常监控
<br/>
响应状态监控:根据
status数据- 各个状态码的响应占比
- 5xx 服务端异常数量
<br/>
结合业务分析:请求的
request_path地址和request_query参数一定是对应具体业务的,例如- 请求某个相册的地址是 /album/:id ,那么日志中的
request_path对应的就是对相册进行了一次访问 - 进行站内搜索的地址是
/search?q=<关键词>,那么统计request_path是/search的日志条数就可以知道进行了多少次搜索,统计request_query中q的参数就可以知道搜索关键词的情况
- 请求某个相册的地址是 /album/:id ,那么日志中的
通用架构

日志系统使用 ELK + kafka 构建是业界比较主流的方案,beats、 logstash 进行日志采集搬运,kafka 存储日志等待消费,elasticsearch 进行数据的聚合分析,grafana 和 kibana 进行图形化展示。