当前位置:网站首页>[Prometheus] an optimization record of Prometheus Federation
[Prometheus] an optimization record of Prometheus Federation
2022-06-21 05:50:00 【Meepoljd】
Prometheus An optimization record of the Federation
Preface
Under the current network environment , my Prometheus It uses the federated feature , This is because the monitored servers exist in multiple physical locations , At the same time, there are many servers , Only after comprehensive consideration, the federal ; But at that time, the servers were scattered , A single collection node does not need to monitor too many servers , It's probably in 500 I can't find it , Therefore, the performance problem has never occurred , I also thought there would be no pit .
During this period , It is necessary to carry out unified management for the data midrange cluster node-exporter Index collection of , The cluster size is about 2600 platform , For some special reason , End use 1 Federation nodes and 2 Acquisition nodes , The data obtained by the front end can be directly connected to the federated node .
The ideal is beautiful , Reality is often cruel , Each of my collection endpoints is the default pull interval , namely scrape_interval yes 15s,scrape_timeout yes 10s, However, each pull of the federated node must exceed 20s, Even 30s, This has directly led to the inevitable omission of some indicators , In response to this question , I still hope to optimize it :
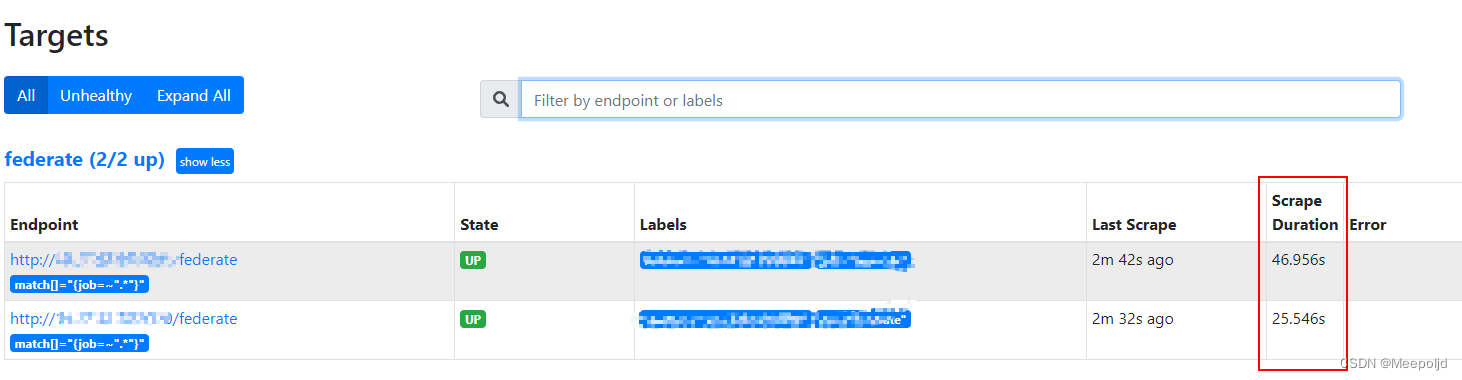
Text
Regroup labels
First of all, my idea is , Put the labels printed at the collection node into the Federation node for unified marking , In this way, you can optimize the time of each pull ?
therefore , I'll start with cluster The tag is placed on the federated node and tested :
Seems to have some effect , But this obviously can not meet the demand .
Useless indicator filtering
A lot of information , In fact, the first determinant of pull time is the number of indicators pulled each time , In fact, I can reduce the burden of pulling to a certain extent by re marking for optimization , But after all, there is no real reduction in the number of indicators ; So I might as well try to reduce the number of indicators ?
therefore , Try to change the... Of the federated node prometheus.yml The configuration file :
scrape_configs:
- job_name: 'federate'
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{__name__=~"node_*"}' # Collect only node Relevant indicators
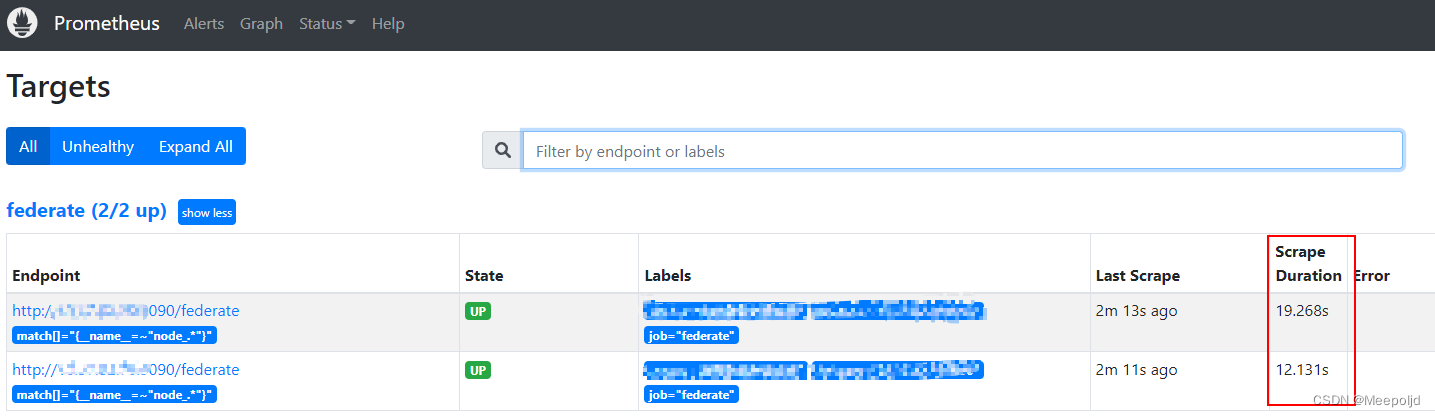
cool! This time it will be shortened to 20 About a second , Actually, from my point of view, it's already very good . In addition to this method , It can also separate and manage the collected index data , For example, use different job Distinguish ;
For details, please refer to the link of this article on the Internet : Federating Prometheus Effectively
边栏推荐
- Global and Chinese markets without regenerative dryers 2022-2028: Research Report on technology, participants, trends, market size and share
- The Mac OS MAMP installs redis with an error/ common. h:12:10: fatal error: ‘zend_ smart_ str.h‘ file not found
- [graduation season] nine year program ape has something to say
- Program optimization with multi-core and multi thread
- CANopen cob-id enable PDO function
- Global and Chinese markets of X-ray generators 2022-2028: Research Report on technology, participants, trends, market size and share
- Object.assign() 对象合并和Object.keys()获取对象名
- 397-链表(206.反转链表 & 24. 两两交换链表中的节点 & 19. 删除链表的倒数第 N 个结点 & 面试题 02.07. 链表相交 & 142.环形链表II)
- OracleLinux6.5图形化安装Oracle11g
- Emotron Elton soft starter maintenance msf370/msf450
猜你喜欢








随机推荐
build opencv3.4.16
[open source tutorial] DIY tutorial of 2020 new version of brushless power regulation [Author: I love loli love loli] (brief introduction and circuit construction)
Common storage types
Things to think about before using mysqldump
armcm3权威指南笔记
Embedded programming complexity
[introduction to practice] CRM project practice tutorial -- CRM project based on SSM framework
base64格式的图片转成文件格式的图片并上传到服务器
Attention based seq2seq model
应用在LED植物照明中的LED照明灯
Globally in top15, fintech recruitment go
Canvas makes classic Snake
新零售品牌“三只松鼠”遇挫,摆脱困境的两大方法
Django database and module models (4)
Mac MAMP Pro installation PHP extension method
Interview questions_ V1.0
VMware new oraclelinux6.5 virtual machine
At the codeless Explorer conference, Qingliu invites you to discuss the way of digital transformation practice
Li Kou ----- result array after removing letter ectopic words
Types de stockage courants