当前位置:网站首页>Groupbykey() and reducebykey() and combinebykey() in spark
Groupbykey() and reducebykey() and combinebykey() in spark
2022-07-05 06:05:00 【YaoYong_ BigData】
One 、groupByKey:
In a (K,V) Of RDD On the call , Return to one (K, Iterator[V]) Of RDD, It's also for each key To operate , But only one sequence,groupByKey The function itself cannot be customized , We need to use it first. groupByKey Generate RDD, And then we can do that RDD adopt map Perform custom function operations .
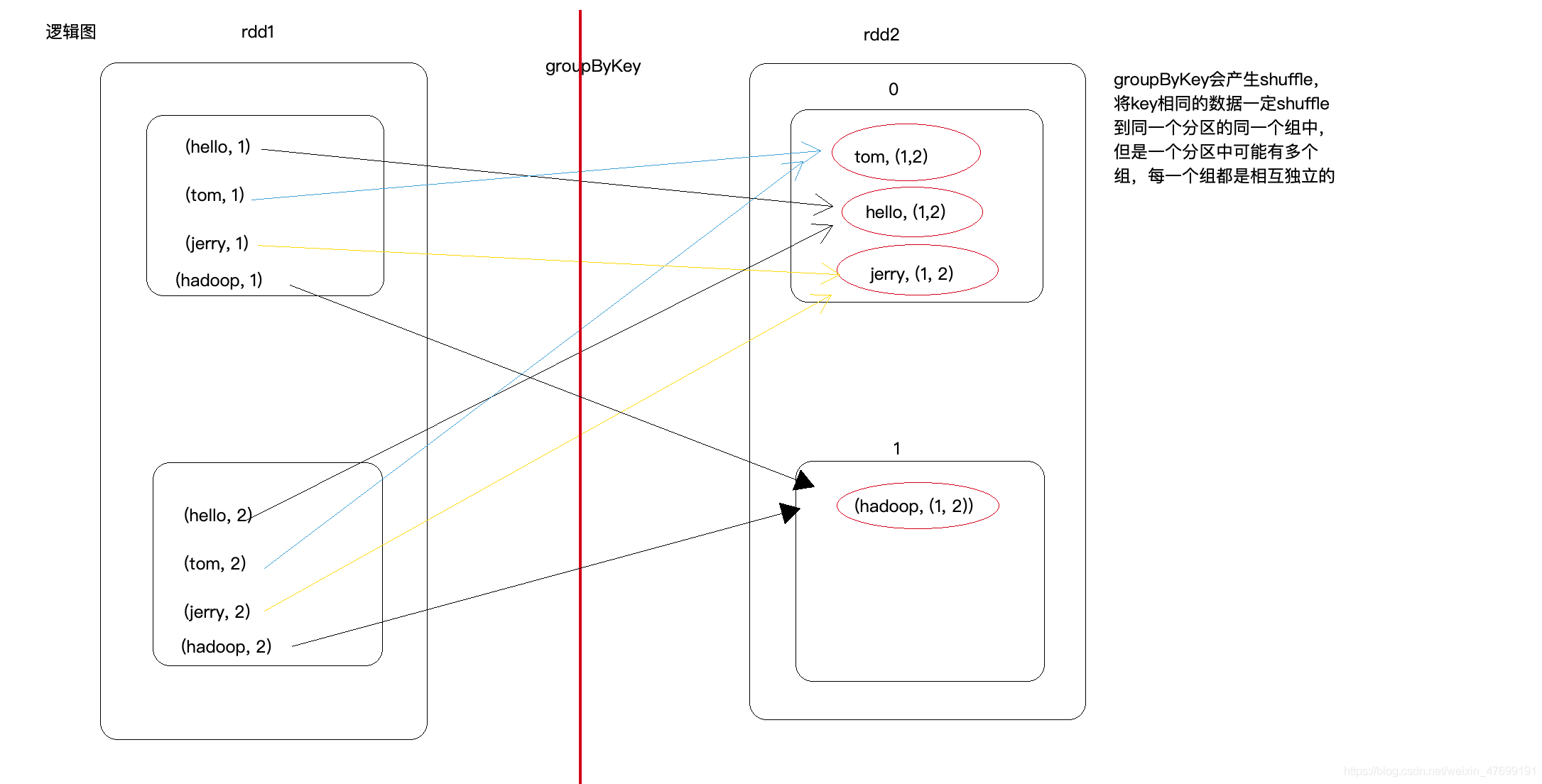
effect :
GroupByKey The main function of the operator is according to Key grouping , and ReduceByKey It's kind of similar , however GroupByKey It's not about aggregation , Just list Key All corresponding Value.
Be careful :
GroupByKey It's a Shuffled.
GroupByKey and ReduceByKey Different , Because you need to list Key All corresponding data , So it can't be in Map End to do Combine, therefore GroupByKey Performance does not ReduceByKey good .
Two 、reduceByKey:
It's right key Of value Conduct merge operation , In a (K,V) Of RDD On the call , Return to one (K,V) Of RDD, Use specified reduce function , Will be the same key The values of , And groupByKey similar ,reduce The number of tasks can be set through the second optional parameter , The most important thing is that it can be done locally first merge operation , also merge Operations can be customized through functions .

effect :
First of all, in accordance with the Key Group to generate a Tuple, Then execute for each group
reduceoperator .
call :
def reduceByKey(func: (V, V) ⇒ V): RDD[(K, V)]
Parameters :
func → Functions that perform data processing , Pass in two parameters , One is the current value , One is partial aggregation , This function needs to have an output , The output is this Key The summary results of .
Be careful :
ReduceByKey It only works on Key-Value Type data , Key-Value Type data in the current context refers to Tuple2.
ReduceByKey It's a need Shuffled The operation of .
And others Shuffled comparison , ReduceByKey It's efficient , Because of the similar MapReduce Of , stay Map There's one side Cominer, such I/O The data will be reduced .
3、 ... and 、combineByKey()
spark according to key Do aggregate aggregateByKey,groupByKey,reduceByKey And other common operators, whose underlying essence is to call combineByKey Realized , That is all combineByKey A special case of , Here's how combineByKey operator :
There are two ways to source :
/**
*
* @param createCombiner
* @param mergeValue
* @param mergeCombiners
* @tparam C
* @return
*/
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners)(null)
/**
*
* @param createCombiner
* @param mergeValue
* @param mergeCombiners
* @param partitioner
* @param mapSideCombine
* @param serializer
* @tparam C
* @return
*/
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners,
partitioner, mapSideCombine, serializer)(null)
}
}
Parameter description :
1、createCombiner:V => C , Create composite functions in partitions . This function takes the current value as a parameter , At this time, we can do some additional operations ( Type conversion ) And return it to ( This step is similar to the initialization operation ).
explain : In the same zone , The same key, Only for the first time value Will run this function .
2、mergeValue: (C, V) => C, Merge value function in partition . This function puts the element V Merge to previous elements C(createCombiner) On ( This operation is carried out in each partition ).
explain : In the same zone , The same key, Not for the first time value Run this function , among C For the last result ,V Is the current value .
3、mergeCombiners: (C, C) => C, Multi partition merge combiner function . This function takes 2 Elements C Merge .
explain : This operation is performed between different partitions .
4、partitioner: Number of custom partitions , The default is HashPartitioner.
5、mapSideCombine: Whether in map End of Combine operation , The default is true.
Go over the figure below , The logic should be clear :

Add a more detailed figure :

Four 、 example
/**
* ------ Output results ------
* (tim,1)
* (lucy,1)
* (Hello,3)
* (lily,1)
*/
@Test
def reduceByKeyTest():Unit = {
// 1. establish RDD
val rdd1 = sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim"))
// 2. Processing data
val rdd2 = rdd1.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
// 3. Get the results
val result = rdd2.collect()
result.foreach(println(_))
// 4. close sc
sc.stop()
}
/**
* ------ Output results ------
* (a,CompactBuffer(1, 1))
* (b,CompactBuffer(1))
*/
@Test
def groupByKey(): Unit = {
val rdd: RDD[(String, Int)] = sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1)))
val rdd1: RDD[(String, Iterable[Int])] = rdd.groupByKey()
val rdd2: Array[(String, Iterable[Int])] = rdd1.collect()
rdd2.foreach(println(_))
}
/**
* ------ Output results ------
* (zhangsan,97.33333333333333)
* (lisi,97.5)
* --- Ask for the average score of each student
*/
@Test
def combineByKey(): Unit = {
// 1. Ready to assemble
val rdd: RDD[(String, Double)] = sc.parallelize(Seq(
("zhangsan", 99.0),
("zhangsan", 96.0),
("lisi", 97.0),
("lisi", 98.0),
("zhangsan", 97.0))
)
// 2. Operator operation
// 2.1. createCombiner Conversion data
// 2.2. mergeValue Aggregation on partitions
// 2.3. mergeCombiners Aggregate the results on all partitions again , Generate the final result
val combineResult = rdd.combineByKey(
createCombiner = (curr: Double) => (curr, 1),
mergeValue = (curr: (Double, Int), nextValue: Double) => (curr._1 + nextValue, curr._2 + 1),
mergeCombiners = (curr: (Double, Int), agg: (Double, Int)) => (curr._1 + agg._1, curr._2 + agg._2)
)
/**
* ------ Output results ------
* (zhangsan,(292.0,3))
* (lisi,(195.0,2))
*/
//val resultRDD = combineResult
val resultRDD = combineResult.map( item => (item._1, item._2._1 / item._2._2) )
// 3. To get the results , Print the results
resultRDD.collect().foreach(println(_))
}边栏推荐
猜你喜欢

2017 USP Try-outs C. Coprimes
7. Processing the input of multidimensional features
Sword finger offer 09 Implementing queues with two stacks

Educational Codeforces Round 116 (Rated for Div. 2) E. Arena
![[article de jailhouse] jailhouse hypervisor](/img/f4/4809b236067d3007fa5835bbfe5f48.png)
[article de jailhouse] jailhouse hypervisor

Sword finger offer 58 - ii Rotate string left
Sword finger offer 05 Replace spaces
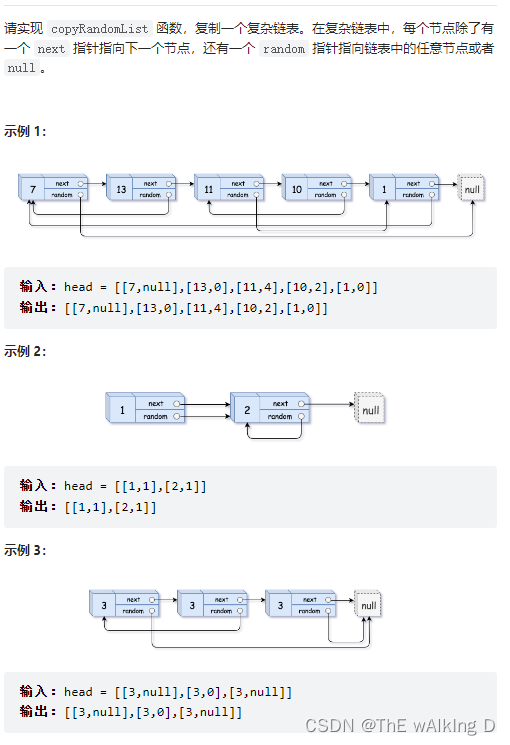
Sword finger offer 35 Replication of complex linked list

中职网络安全技能竞赛——广西区赛中间件渗透测试教程文章

Time of process
随机推荐
Brief introduction to tcp/ip protocol stack
常见的最优化方法
Smart construction site "hydropower energy consumption online monitoring system"
Sword finger offer 05 Replace spaces
Daily question 1688 Number of matches in the competition
“磐云杯”中职网络安全技能大赛A模块新题
1039 Course List for Student
shared_ Repeated release heap object of PTR hidden danger
过拟合与正则化
【Jailhouse 文章】Performance measurements for hypervisors on embedded ARM processors
一些工具的记录2022
R language [import and export of dataset]
AtCoder Grand Contest 013 E - Placing Squares
Bit mask of bit operation
Dichotomy, discretization, etc
【Rust 笔记】16-输入与输出(上)
Sword finger offer 04 Search in two-dimensional array
Wazuh开源主机安全解决方案的简介与使用体验
Sword finger offer 05 Replace spaces
Over fitting and regularization