当前位置:网站首页>Graphic data analysis | data cleaning and pretreatment
Graphic data analysis | data cleaning and pretreatment
2022-06-12 02:01:00 【ShowMeAI】

author : Han Xinzi @ShowMeAI
Tutorial address :http://www.showmeai.tech/tutorials/33
This paper addresses :http://www.showmeai.tech/article-detail/138
Statement : copyright , For reprint, please contact the platform and the author and indicate the source

The core steps of data analysis are divided into : Business cognition and data exploration 、 Data preprocessing 、 Business cognition and data exploration Wait for three core steps . This article introduces the second step —— Data preprocessing .
Data cannot be taken for granted to be valid .
In the real world , Data is generally heterogeneous 、 There is something missing 、 Dimensional . Some data is obtained from multiple different data sources , These heterogeneous data , They're all right in their own systems , It's just a lot of “ personality ”.
for example , Some systems use 0 and 1, For gender ; And some systems use f and m For gender .
- Before using the data , First of all, the data should be regularized , Use consistent units 、 Use unified text to describe objects, etc .
- Some data contains a lot of duplicate data 、 Missing data 、 Or outlier data , Before we start analyzing the data , You have to check that the data is valid , And preprocess the data .
- Judge the outlier value , And analyze it , Sometimes it leads to major discoveries .
One 、 The data is regular
1.1 dimension
The so-called dimension , Simply speaking , That's the unit of data . Some data are dimensional , For example, height ; And some data are dimensionless , for example , The male to female ratio . Different evaluation indexes often have different dimensions , The difference between the data can be big , No processing will affect the results of data analysis .

1.2 Data standardization
In order to eliminate the influence of dimension and value range differences between indicators on data analysis results , Data needs to be standardized . That is to say , Scale the data to scale , Make it fall into a specific area , It is convenient for comprehensive analysis .
1.3 Data normalization
Normalization is the simplest way of data standardization , The purpose is to change numbers into [0, 1] Decimal between , Convert dimensional data into dimensionless pure quantity . Normalization can avoid the influence of range and dimension on data , It is convenient for comprehensive analysis of data .
Illustrate with examples
A simple example , In an exam , Xiao Ming's Chinese achievement is 100 branch 、 The English score is 100 branch , Just from the test results , Xiao Ming is as good at Chinese as he is at English . however , If you know the total score of Chinese is 150 branch , And the total score of English is only 120 branch , Do you still think Xiao Ming's Chinese and English scores are the same ?
Make a simple normalization of Xiao Ming's achievements :
Using the method of deviation normalization , Formula is :y = (x-min) / range, Set here min=0, that range = max - min = max, It can be inferred that Xiaoming's Chinese achievement is 4/6, The English score is 5/6. therefore , Xiao Ming's English is better than his Chinese .
Return to the real scene , The difficulty of each subject is different , The lowest score of Chinese in the class is min Chinese language and literature = 60, The lowest score in English is min English = 85, It is estimated that Xiaoming's Chinese achievement is 0.44 =(100-60)/(150-60), The English score is 0.43 = (100-85)/(120-85), Accordingly , It can be judged that Xiao Ming's English is slightly worse than his Chinese .
Normalized so that it has a different range of values 、 There is comparability between data of different dimensions , Make the results of data analysis more comprehensive , Closer to the truth .
Two 、 Data outliers detection and analysis
The full name of abnormal value in statistics is suspected abnormal value , Also called outliers (outlier), The analysis of outliers is also called outlier analysis .
Outlier analysis is to check whether there are unreasonable data in the data , In data analysis , The existence of outliers cannot be ignored , Nor can we simply eliminate outliers from data analysis . Pay attention to the occurrence of outliers , Analyze the causes , It often becomes an opportunity to discover new problems and improve decision-making .
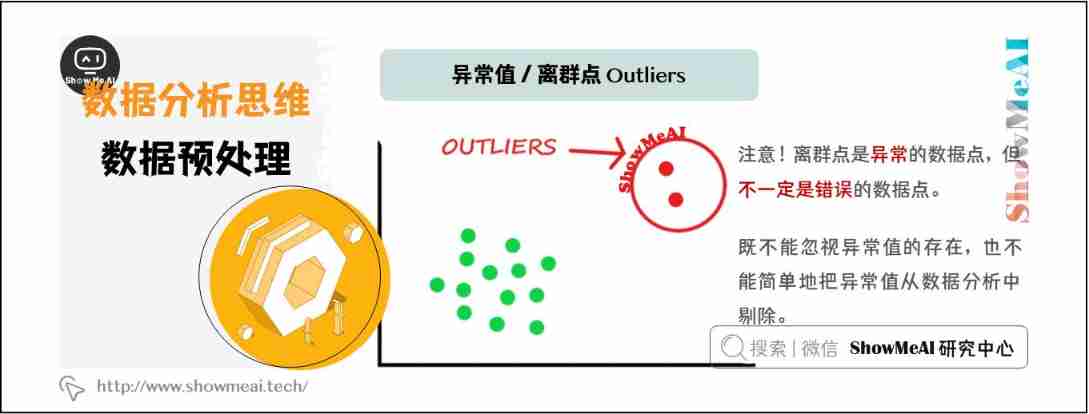
In the diagram above , outliers (outlier) The deviation from other observation points is very large . Be careful , Outliers are abnormal data points , But not necessarily the wrong data point .
2.1 Outlier detection
(1) Descriptive analysis methods
In data processing , You can do a descriptive analysis of the data , And then look at what data is unreasonable . The commonly used statistics are maximum and minimum , It is used to judge whether the value of the variable exceeds the reasonable range . for example , The maximum age of the customer is 199, The value is abnormal .
(2)Z-Score Method

[1] 3σ principle
Introducing Z-score Before method , So let's see 3σ principle —— If the data follows a normal distribution , stay 3σ In principle , Outliers are defined as 『 Of a set of measured values , A value that deviates from the mean by more than three times the standard deviation 』.
Under normal distribution , Distance average 3σ The probability of occurrence of values other than P(|x-μ|>3σ)<=0.003, It belongs to a very small probability event . stay 3σ In principle , If the difference between the observed value and the average value exceeds 3 Times the standard deviation , Then you can treat it as an outlier .
[2] Z-Score
If the data does not obey the normal distribution , You can use 『 How many times the standard deviation is the distance from the mean 』 To describe , This multiple is Z-scor.
Z-Score In standard deviation (σ) In units of , To measure an original score (X) Deviation from the average (μ) Distance of . Z-Score It needs to be decided according to experience and actual situation , It is usually far from the standard deviation 3 Data points more than times the distance are regarded as outliers .
Python The implementation of the code is as follows :
import numpy as np
import pandas as pd
def detect_outliers(data,threshold=3):
mean_d = np.mean(data)
std_d = np.std(data)
outliers = []
for y in data_d:
z_score= (y - mean_d)/std_d
if np.abs(z_score) > threshold:
outliers.append(y)
return outliers
(3)IQR Anomaly detection
Interquartile distance (Inter-Quartile Range,IQR), It means in the 75 Percentage points vs 25 Percent difference , Or say , The difference between the upper quartile and the lower quartile .

IQR Is a measure of statistical dispersion , The degree of dispersion depends on the box diagram (Box Plot) To observe . Usually less than Q1-1.5_IQR Or greater than Q3+1.5_IQR Data points are treated as outliers .
The following important characteristics of the dataset can be seen visually from the box diagram :
Center position : The position of the median is the center of the data set , Look up or down from the center , You can see the inclination of the data .
The degree of dispersion : The box diagram is divided into several sections , The interval is short , Indicates that the points falling in this interval are concentrated ;
symmetry : If the median is in the middle of the box , Then the data distribution is more symmetrical ; If the extreme value is far from the median , That means the data distribution is skewed .
outliers : Outliers are distributed outside the upper and lower edges of the box graph .
Use Python Realization , Parameters sr yes Series Variable of type :
def detect_outliers(sr):
q1 = sr.quantile(0.25)
q3 = sr.quantile(0.75)
iqr = q3-q1 #Interquartile range
fence_low = q1-1.5*iqr
fence_high = q3+1.5*iqr
outliers = sr.loc[(sr < fence_low) | (sr > fence_high)]
return outliers
2.2 Exception handling
In data processing , How to handle outliers , It depends on the circumstances . Sometimes , Outliers can also be normal values , It's just abnormally large or small , therefore , In many cases , First analyze the possible causes of outliers , Then determine how to handle outliers . Common methods for handling outliers are :
Delete records with outliers .
interpolation , Treat outliers as missing values , Handle with missing values , The advantage is to replace outliers with existing data , Or imputation .
Don't deal with , Perform data analysis directly on data sets containing outliers .
3、 ... and 、 Processing of missing values
Not all data is complete , Some observations may be missing . For missing values , The usual treatment is to delete the data row where the missing value is located 、 Fill in missing values 、 Impute missing values .

Data and code download
The code for this tutorial series can be found in ShowMeAI Corresponding github Download , Can be local python Environment is running , Access to Google Your baby can also use google colab One click operation and interactive operation learning Oh !
The quick look-up tables involved in this series of tutorials can be downloaded and obtained at the following address :
Expand references
ShowMeAI Recommended articles
- Introduction to data analysis
- Data analysis thinking
- Mathematical basis of data analysis
- Business cognition and data exploration
- Data cleaning and preprocessing
- Business analysis and data mining
- Data analysis tool map
- Statistical and data science computing tool library Numpy Introduce
- Numpy And 1 Dimension array operations
- Numpy And 2 Dimension array operations
- Numpy And high-dimensional array operation
- Data analysis tool library Pandas Introduce
- The illustration Pandas A complete collection of core operating functions
- The illustration Pandas Data transformation advanced functions
- Pandas Data grouping and operation
- Principles and methods of data visualization
- be based on Pandas Data visualization
- seaborn Tools and data visualization
ShowMeAI A series of tutorials are recommended
- The illustration Python Programming : From introduction to mastery
- Graphical data analysis : From introduction to mastery
- The illustration AI Mathematical basis : From introduction to mastery
- Illustrate big data technology : From introduction to mastery

边栏推荐
- 商城开发知识点
- MySQL advanced knowledge points
- Huawei intermodal game or application review rejected: the application detected payment servicecatalog:x6
- 括号生成(回溯)
- Operation of simulated examination platform of diazotization process examination question bank in 2022
- Comprehensive quality of teaching resources in the second half of 2019 - subjective questions
- Knowledge points of mall development
- 如何定位关键词使得广告精准投放。
- Leetcode 55 jump game
- Websocket is closed after 10 seconds of background switching
猜你喜欢

Dataset how to use dataset gracefully. After reading this article, you can fully understand the dataset in c7n/choerodon/ toothfish UI

"It's safer to learn a skill!" The little brother of Hangzhou campus changes to software testing, and likes to mention 10k+ weekend!

Kmeans from 0 to 1

Linux(CentOS6)安装MySQL5.5版本数据库

如何让杀毒软件停止屏蔽某个网页?以GDATA为例

Design practice of rongyun Im on electron platform

华为联运游戏或应用审核驳回:应用检测到支付serviceCatalog:X6

通用树形结构的迭代与组合模式实现方案

PyGame alien invasion
“還是學一門技術更保險!”杭州校區小哥哥轉行軟件測試,喜提10K+雙休!
随机推荐
php开发 博客系统的公告模块的建立和引入
How to improve the advertising rating of advertising, that is, the quality score?
How to automatically color cells in Excel
Websocket is closed after 10 seconds of background switching
[从零开始学习FPGA编程-19]:快速入门篇 - 操作步骤4-1- Verilog 软件下载与开发环境的搭建- Altera Quartus II版本
Several visualization methods of point cloud 3D object detection results (second, pointpillars, pointrcnn)
2022最全面的Redis事务控制(带图讲解)
Redis实现消息队列的4种方案
决定广告质量的三个主要因素
Linux(CentOS6)安装MySQL5.5版本数据库
小程序111111
如何提高广告的广告评级,也就是质量得分?
Introduction to SVM
C language programming classic games - minesweeping
Invert words in a string (split, double ended queue)
What are the advantages of adaptive search advertising?
聯調這夜,我把同事打了...
Three main factors determining advertising quality
Huawei, this is too strong
Dataset how to use dataset gracefully. After reading this article, you can fully understand the dataset in c7n/choerodon/ toothfish UI