当前位置:网站首页>认识网络模型网络模型概述
认识网络模型网络模型概述
2022-07-27 18:22:00 【华为云】
P2P网络模型
一、常见网络模型
1.随机网络:随机网络的研究是基于随机图理论的。
2.规则网络:常见的规则网络有最近邻耦合网络和星形耦合网络。
3.小世界网络
二、集中目录式P2P网络模型
概念:采用中央目录服务器管理P2P网络各节点,具有中心化的特点,也被称为非纯粹的P2P网络。中央目录服务器只保留索引信息,由对等节点负责保存各自提供服务的全部资料,
此外,服务器与对等节点以及对等节点之间都具有交互能力。
原理:集中目录式P2P网络模型采用星形结构,群组中的对等节点都与中央目录服务器相连,并向其发布分享的文件列表。查询节点可向中央目录服务器发起文件检索请求,得到回
复后,查询节点则依据网络流量和延迟等信息选择合适的节点建立直接连接,此时文件交换即可直接在两个对等节点之间进行。此过程中,中央目录服务器负责记录群组所有参加者的
信息,以进行适当的管理。
优点:
1.维护简单
2.发现资源率高
缺点:
1.可靠性和安全性较低
2.维护成本高
3.存在法律版权和资料浪费问题
所以集中目录式P2P网络模型适合小型网络应用,典型案例:BitTorrent
三、纯分布式P2P网络模型
概念:纯P2P网络模型中,每个节点既是服务器又是客户端,节点之间通信是完全对等的。每个节点都维护一个邻居列表,节点通过和它的邻居进行交互来完成特定的功能。这种网
络结构解决了中心化问题,拓展性和维护性较好。
分类:
1.非结构化覆盖网络
2.结构化覆盖网络
纯P2P非结构化网络模型
概念:也被称为广播式P2P模型,对等节点之间的内容查询和内容分享是通过相邻节点广播接力完成的。每个用户随机接入网络,并与自己相邻的一组邻居节点通过端到端连接,
构成一个逻辑覆盖的网络。查询节点发出一个查询请求并直接广播到所连接的邻居节点,如果邻居节点不能满足请求,则以同样的广播方式请求各自相连的邻居节点,以此类推。
为防止搜索环路的产生,每个节点会记录搜索轨迹。
案例:Gnutella模型是应用最广泛的纯P2P非结构化网络模型,它采用了完全随机图的泛洪发现和随机转发机制,通过IP多播技术让对等节点定期发布资源和传播查询。
优点:
1.完全的分布式使之具有最大的容错性,不会出现单点崩溃现象
2.能潜在的获得最多的查询结果
缺点:
1.整个网络的拓展性较差,随着对等节点的数量增加,网络可能存在过多的查询而发生阻塞
2.由于没有中央目录服务器对用户进行管理,因此缺乏较好的集中控制和策略
3.查询的有效期和正确性都不能保证
4.能力有限的对等节点容易造成系统瓶颈
5.网络中对等节点的查找和定位比较复杂,效率低下
纯P2P结构化网络模型
概念:结构化和非结构化模型的根本区别在于每个节点所维护的邻居是否能按照某种全局方式组织起来以利于快速查找。结构化P2P网络模型是一种采用纯分布式的消息传递
机制和根据关键字进行查找的定位服务。在结构化网络模型中,节点维护的邻居都是由规律的,P2P网络的拓扑结构是严格受到控制的,信息资源将有规则的组织存放到合适的节
点,查询以较少的跳数,路由到负责所查询信息资源的节点上。
目前结构化P2P的主流方法是采用散列表(DHT)技术,这也是目前拓展性最好的P2P路由方式之一。它是在非结构化的P2P系统中加入了人为的控制策略,把整个系统的工作重点
放在如何有效的查找信息上。
优点:
1.由于DHT各节点并不需要维护整个网络的信息,只在节点中存储其邻近的各节点信息,因此较少的路由信息就可以有效的实现到达某个节点
2.取消了泛洪算法,利用分布式散列表进行定位查找,可以有效地减少节点信息的发送数量,从而增强了P2P网络的扩展性
3.出于冗余度以及延时的考虑,大部分DHT总是在节点的虚拟标识与关键字最接近的节点上复制备份冗余信息,这样也避免了单一节点失效的问题
4.使用者匿名,数据传输加密
缺点:
1.维护机制复杂,尤其是节点频繁加入、退出造成的网络波动会极大增加DHT的维护代价
2.仅支持精确关键字匹配查找,无法支持内容/语义等查找
3.结构化P2P网络模型,由于自身算法的限制,不适合超大型的P2P系统
四、分层式P2P网络模型
集中目录式网络模型有利于网络资源的快速检索,但是其中心化的模式容易遭到直接的攻击;纯P2P模型解决了抗攻击问题,但又缺乏快速搜索和可扩展性。所以出现了分层式
P2P网络模型。
概念:在设计和处理能力上进行了优化,根据各节点的处理能力不同(计算能力、内存大小、网络带宽、网络滞留时间等)区分出超级节点和普通节点。在资源共享方面,所有
节点地位相同,区别在于,超级节点上存储了其他部分节点的信息,发现算法仅在超级节点之间进行。超级节点再将查询请求转发给普通节点。
案例:KaZaa
KaZaa协议中,每个节点上线后会寻找一个超级节点挂靠,并和原先挂靠在该超级节点下的其他普通节点相连接,组成一个小的无结构网络。
优点:
1.按性能对节点进行分类。根据节点能力合理分担负载。
2.各簇相对独立。如果一个簇改变了内部查询机制,这对于其他簇和上层的查询机制是独立的;同理,当一个节点失效,只会对其归属簇有影响
3.提高了查询速度。由于划分簇,每个簇的节点数远远少于总节点数,从而减少路由跳数
4.减少了查询消息传播的数量
缺点:
1.实现上比较困难,需要提供能够有效组织节点间关系的搜索网络
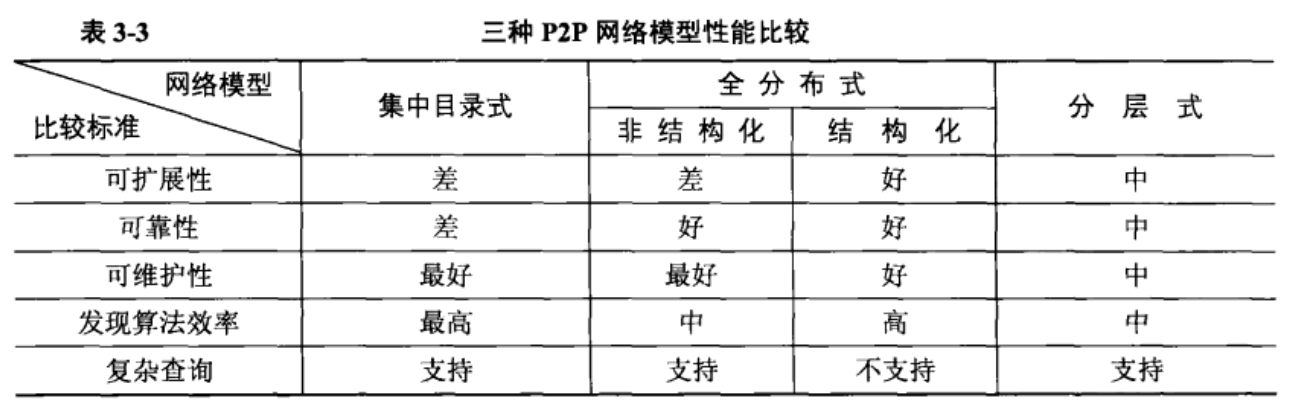
五、三种P2P网络模型性能对比
边栏推荐
猜你喜欢
Introduction to JVs Foundation

How to solve the problem of missing alarm information and synchronization when Haikang equipment is connected to easycvr?

2022-07-19 advanced network engineering (XX) BGP route optimization, route optimization analysis one by one

程序中的地址如何转换?

做测试, 就得去大厂,内部披露BAT大厂招聘“潜规则”

学术分享 | 清华大学 康重庆:电力系统碳计量技术与应用(Matlab代码实现)

Hcip day 5

Best practices for Oracle kingbasees migration of Jincang database (4. Oracle database migration practice)
JVS基础介绍
![[deep learning] pytoch tensor](/img/72/d3e46a820796a48b458cd2d0a18f8f.png)
[deep learning] pytoch tensor
随机推荐
Management of user organization structure
金仓数据库 Oracle 至 KingbaseES 迁移最佳实践 (4. Oracle数据库移植实战)
vi工作模式(3种)以及模式切换(转换)
用户和权限修改用户密码
关于栈迁移的那些事儿
JVS基础框架功能列表
R语言使用epiDisplay包的lroc函数可视化logistic回归模型的ROC曲线并输出诊断表(diagnostic table)、可视化多条ROC曲线、使用legend函数为可视化图像添加图例
Software test interview question: given a queue, such as: [1, 3, 5, 7], how to put the first number into the third position to get: [3, 5, 1, 7]
MySQL驱动jar包的下载--保姆教程
[Numpy] 数组属性
你了解数据同步吗?
R语言使用dplyr包左连接两个dataframe数据(left join)
用户组织架构的管理
说透缓存一致性与内存屏障
Users and permissions create ordinary users
全局样式与图标
Hcip day 5
走马灯案例
金仓数据库 KingbaseES异构数据库移植指南 (2. 概述)
从0开始写bootloader