
Reading guide : As a basic data structure , The application scenario of graph data is everywhere , Social interaction 、 Risk control 、 Search and push 、 Protein analysis in bioinformatics, etc . How to efficiently store massive graph data 、 Inquire about 、 Calculation and analysis , It is a popular direction in the current industry . This paper will introduce the graph database of byte jump ByteGraph And its application and challenge within bytes .
This article will focus on the following five points :
- Understanding graph database
- Examples of applicable scenarios
- Data model and query language
- ByteGraph Architecture and implementation
- Analysis of key issues
--
01 Understanding graph database
at present , There are three self-developed graph data products in the following table .

1. Compare graph database with relational database
The basic elements of the graph model include points 、 Edges and attributes . give an example : How many employees does Zhang San's friend work for ? Traditional relational databases require multiple tables join, Graph as semi-structured data , Traversal and attribute filtering on the graph will be more efficient .
2. What is graph database ?
In the past five years , Figure the rising trend of database popularity in the field is very obvious , All major manufacturers and open source communities have launched their own graph databases . Large scale of users 、 Some influential query languages include Cypher、Apache Open source project Gremlin etc. . In terms of cluster size , In the past, there was a stand-alone database , Most graph databases now have distributed capabilities , This requires consideration of data loss prevention 、 Consistency between primary replicas 、 Data on multiple machines shard problem .
Partial graph database combines graph database and graph computing engine , At present, there are two sets of temporarily separated systems used in bytes .
--
02 Examples of applicable scenarios
1. ByteGraph Applicable business data model
ByteGraph The initial project was initiated in 2018 year , The main purpose is to store and replace the user behavior and friends of headlines Mysql;2019 year 6 In June, the company undertook the data storage task of Tiktok user relationship , Then, various microservices within bytes undertake related businesses again .

2. Online business scenario classification
There are 1.5 Ten thousand physical machines , In the service of 600+ Business cluster .

--
03 Data model and query language
1. Directed attribute graph modeling
For now , Graph databases usually fall into two categories , One is attribute graph , The other is RDF chart . The attribute graph has attribute tables on nodes and edges , In a way , It still has the basic features of relational databases , Similar to the form of table structure , In fact, it adopts Key-Value Form to store , Such as user A Focus on users B, user C Like a video, etc , Will focus on the time 、 Like time 、 The contents of comments are stored in the attribute graph with different directed edges , Use diagrams to describe business logic .

2. Gremlin Query language interface
choose Gremlin The language is convenient for graph calculation 、 Figure the two databases are fused , It is a Turing complete graph traversal language , Compare with Cypher Such as SQL Language , For making good use of Python It's easier for data analysts to get started .
give an example : Write a user A The number of fans satisfied in all one hop friends is greater than 100 Subset . First locate the user A Points in the graph , Secondly, find all the neighbors in the one hop query , Judge whether the overall number of in-depth neighbors is greater than 100, Pull all users that meet the conditions .

--
04 ByteGraph Architecture and implementation
1. ByteGraph The overall architecture
ByteGraph The overall architecture is divided into query engine layer (Graph Query Engine, Hereinafter referred to as" GQ)、 Storage engine layer (Graph Storage Engine, Hereinafter referred to as" GS) And disk storage layer , On the whole, computing and storage are separated , Each layer consists of a cluster of multiple process instances .

2. ByteGraph Read and write flow
take “ Reading process ” give an example , Request to get user A My neighbor . First, after a query comes in , from client The client randomly selects a query layer response , Corresponding to GQ2 On , Get which machine the corresponding data is stored on , Then give the request to GS1, Check whether the data is in this layer and whether it is the latest data , If not, go to KV store Pull the required data to GS1 In cache .

3. ByteGraph Realization :GQ
GQ Same as MySQL Of SQL The layers are the same , Be responsible for query parsing and processing , Among them “ Handle ” It can be divided into the following three steps :
- Parser Stage : The recursive descent parser is used to parse the query language into a query syntax tree .
- Generate query plan : take Parser The query syntax tree obtained in the stage follows the query optimization strategy (RBO&CBO) Convert to execution plan .
- Execute query plan : understand GS Data points Partition The logic of , Find the corresponding data and push down some operators , Ensure that the network overhead is not too large , Finally, merge the query results , Complete the query plan .
RBO Based mainly on Gremlin Self contained optimization rules in open source implementation 、 For operators in byte application, push down 、 Custom operator optimization (fusion) Three rules .CBO In essence, it is to make statistics on the access of each point , Quantify the cost with an equation .

Use different strategies for different support scenarios , The choice and of graph partition algorithm workload Strong correlation , Graph partition algorithm can effectively reduce the number of network communications .
- Brute force Hash partition : That is, consistent hash partitioning is performed according to the type of starting point and edge , Most scenario requirements can be queried , Especially for one-time query scenarios .
- Knowledge map scenario : spot 、 There are many edge types , However, the number of edges of each type is relatively small , In this case, hash partition is performed according to the edge type , Distribute data of the same edge type in a partition .
- Social scene : It is more likely to appear large V, utilize facebook On 2016 Put forward in social hash Algorithm , Try to place the related data in the same partition through offline calculation , Reduce latency .
4. ByteGraph Realization :GS

- Storage structure
Single Partition Defined as a starting point + One hop neighbors for a particular edge type fan out . stay GS in , Will a Partition Press the sort key ( It can be explicitly set or maintained by default ) Organized into Btree. Each tree Btree There are independent ones WAL Sequence , Independent maintenance is self increasing logid. This design helps support GNN scene , Do distributed sampling .
Edge Page、Meta Page They are located in Btree Leaf nodes in 、 Non leaf node ( act as index effect ), It is used to store the edge data in the graph and Key.Meta page The length is fixed , But one meta page How much will you put edge page It's matching , It is usually configured as 2000 a slice . Pictured above ,Partition Place each on disk page Are stored as a separate key value pair ( Hereinafter referred to as" KV To ).meta page Of key Starting point + Edge type ,edge page Of key There is meta page For a specific edge page Lookup .
The single machine memory engine as a whole adopts hash map Structure ,partition and page Load into memory on demand , according to LRU Strategy (Least Recent Used),swap To disk ; Some page After being modified ,WAL Synchronous write to disk ,page Will be inserted into dirty In the list , Consider the current machine state , Write back asynchronously .

- Log management : Single starting point + Edge types form a tree Btree, Each node is a KV Yes .
Each tree Btree Single writer , Prevent concurrent writes from causing incompleteness ; Each tree has its own WAL Log stream , And only... Is written in the write request processing flow WAL, And modify the data in memory ,compaction And then drop the data onto the disk , Solve for each KV Write amplification that may be caused by multiple edges . Even if memory data is lost , You can still use the updated logid On disk WAL And write .
- Cache implementation : According to different scenes and the present cpu There are different strategies for the cost of .
Figure native cache : be relative to Memcached For directly caching binary data , To better understand the semantics of graphs , It also supports some calculation and push down functions in one-time query .
High performance LRU Cache: Support cache eviction , The expulsion frequency and trigger threshold are adjustable ; use numa aware and cpu cacheline aware Design , Improve performance ; Support Intel AEP Wait for new hardware .
Write-through cache: Support multiple modes to synchronize data with the underlying storage , You can write each time or drop the disk regularly ; Support regular verification of data with underlying storage , Prevent data from getting too old ; Support common optimization strategies such as negative cache .
Cache and storage are separated : When the data scale remains unchanged 、 When the request traffic increases , The mode of separating cache from storage can quickly expand cache to improve service capability .
--
05 Analysis of key issues
1. Indexes
Local index : Given a start point and an edge type , Index the attributes on the edge
characteristic : All the edge elements can be used as index entries , Can speed up query , Improve property filtering and sorting performance ; However, an additional index data will be maintained , Use the same log stream as the corresponding original data , Guarantee consistency .Global index : Currently, only the attribute global index of points is supported , That is, specify an attribute value to query the corresponding point .
Data is stored on different machines , The consistency of index data is solved by distributed transaction .
2. Hot reading and writing
- Hot reading
Examples of scenes : A hot video is frequently refreshed , Check their likes .
Application mechanism :GQ Multiple layers are used bgdb Concurrent processing of read requests from the same hotspot , Single node cache hit read performance can reach 20 All the above ;GS The layer adopts copy on write( Copy first , Then write and replace ) Ensure reading and writing 、 It can be read concurrently .
- Hot writing
Examples of scenes : A hot video was frantically forwarded in a short time 、 give the thumbs-up .
Problem tracing : stand-alone cpu The utilization rate has been increased , Disk write iops Upper limit , When the client writes qps> disk iops when , A request queue will occur .
Coping mechanism : use group commit Mechanism , Combine multiple write requests into one batch write in KV, And then return in batch , Lower the disk tier iops Upper limit .

3. Light and heavy query resource allocation
Separate the resource pool of light and heavy queries , Light query walk light Thread pool , Responsible for a large number of small queries ; If you re query, you will go heavy Thread pool , Responsible for a small number of re queries . When heavy When the thread pool is idle , Light query can also go .

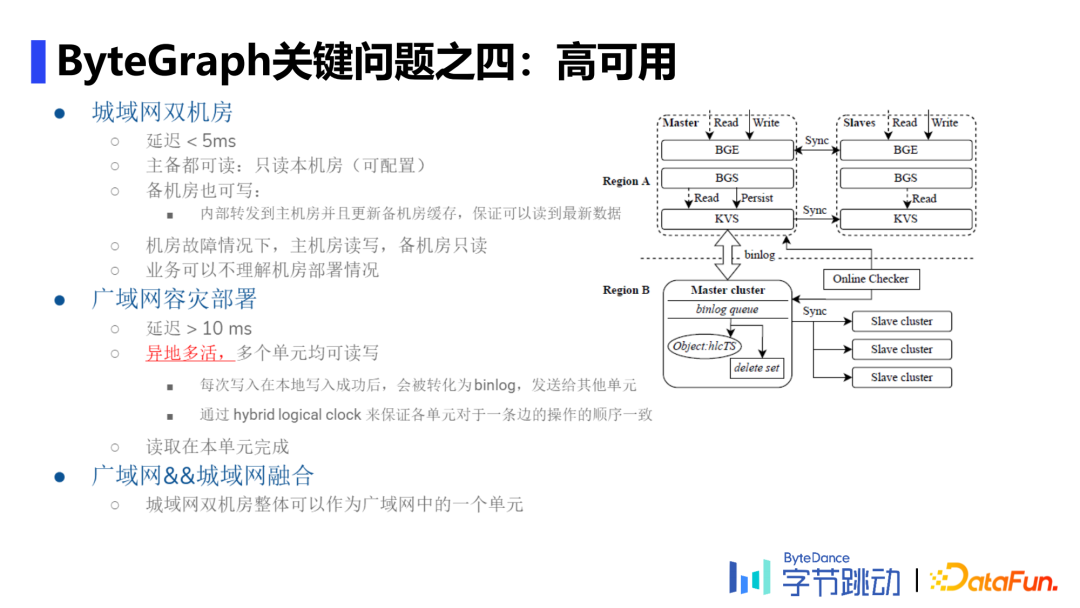
4. High availability
Man dual machine rooms , For example, there are two computer rooms in China , Low latency .follow One write multiple read strategy , The standby machine room transfers the write traffic to the host machine room , Only the main engine room will WAL Update to KV On storage .
Wan disaster recovery deployment , Such as two machines in Singapore and the United States , High latency .follow 了 mysql Thought , Each write is successful after the local write , Will be converted to binlog, And then send it to other units ; And pass hybrid logical clock Ensure that the operation sequence of each unit for one edge is consistent .
5. Offline and online data stream fusion

Import stock data 、 Write online data , Integrate the two into the company's internal data platform for offline data analysis , The specific process is shown in the figure .
Today's sharing is here , Thank you. .
This article was first published on WeChat public “DataFunTalk”.









![[tcaplusdb knowledge base] Introduction to tcaplusdb tcapulogmgr tool (II)](/img/46/e4a85bffa4b135fcd9a8923e10f69f.png)