当前位置:网站首页>【AI4Code】《InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees》ICSE‘21
【AI4Code】《InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees》ICSE‘21
2022-07-25 12:39:00 【chad_ lee】
《InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees》 ICSE 2021
Commit to self-monitoring and training the representation of code , Do not use any labels .
Put forward InferCode, Use self supervised learning from the abstract syntax tree of the code (AST) Learning the representation of code in , By forecasting AST The subtree in constructs the training label , The subtree structure can be constructed AST Automatically generated in the process . Based on the assumption that : Similar code snippets AST Contains similar subtrees , For example, two kinds of bubble sorting codes , Contains a large number of similar code structures :

InferCode Unsupervised downstream tasks of have code clustering 、 Clone detection and cross language code search ; Supervised migration learning includes code classification and code recommendation .
Method
summary

InferCode And Doc2vec similar , take AST Treat as document , Subtree as a word in the document . Given AST aggregate { T 1 , T 2 , … , T n } \left\{T_{1}, T_{2}, \ldots, T_{n\}}\right. { T1,T2,…,Tn}, T i T_i Ti Set of all subtrees of { … , T i j , … } \left\{\ldots, T_{i j}, \ldots\right\} { …,Tij,…}, take T i T_i Ti and T i j T_{ij} Tij Expressed as D Dimension vector , Consider subtree T i j T_{ij} Tij Appear in the T i T_i Ti In the context of , Maximize logarithmic losses : ∑ j log P r ( T i j ∣ T i ) \sum_{j} \log P_{r}\left(T_{i j} \mid T_{i}\right) ∑jlogPr(Tij∣Ti). therefore InferCode The steps are :
- Preprocess the dataset , Generate for each piece of code AST, And identify the set of subtrees . All subtree sets are cumulatively constructed into subtree corpus .
- use TBCNN code AST Generate code vector , Used to predict subtrees .
- encoder Trained for downstream tasks .
Identify subtrees
Traverse AST, Take the node that meets the specified conditions as the root node of the subtree , Identify the subtree . The specified condition is (expr_stmt,decl_stmt,expr,condition). In addition, some key nodes are also considered , for example if,for,while, these A separate The node of is treated as a subtree .
Therefore, the selection condition of subtree is that the subtree structure is relatively small , The author claims that such fine-grained subtrees are easier to appear in code fragments . And coarse-grained subtree , Such as if,while,for Sentence block , These subtrees are too big . As a single word , Appear infrequently in the code base ,encoder It is difficult to learn meaningful expressions directly ; Although the syntax of these large subtrees is different, it does not mean that the function of the code is different ,encoder It's hard to learn their similarities .
This paper gives an example of a subtree recognized by bubble sorting code :
Learn code representation
First of all, we will introduce the multi tree AST Turn into a binary tree , And then use Tree-based CNN(TBCNN) As encoder.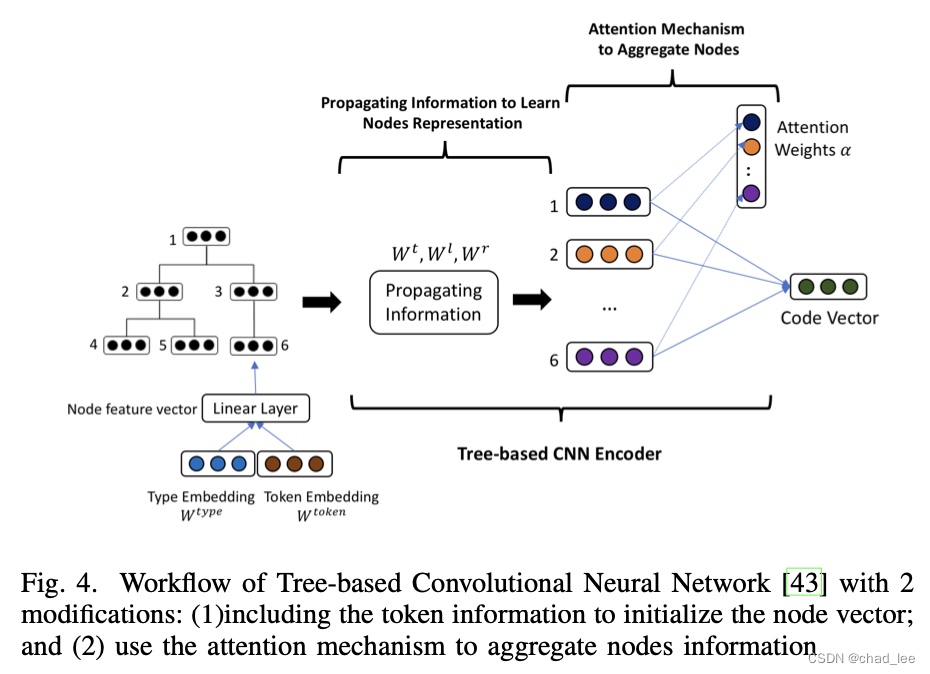
First, the initial of each node embedding yes Type embedding and Token embedding Output through a linear layer .
And then through TBCNN The convolution layer of can learn the information of nodes .
TBCNN (AAAI‘16)

TBCNN The thought of is similar to GCN,TBCNN Three convolution kernels are designed for tree structured data : W t , W l , W r ∈ R D × D \mathbf{W}^{t}, \mathbf{W}^{l}, \mathbf{W}^{r} \in \mathbb{R}^{D \times D} Wt,Wl,Wr∈RD×D respectively “top”,“left” and “right”, So for AST Convolution window “depth d” Contains K = 2 d − 1 K=2^{d}-1 K=2d−1 Nodes [ x 1 , … , x K ] \left[\mathbf{x}_{1}, \ldots, \mathbf{x}_{K}\right] [x1,…,xK], The final output of this window is :
y = tanh ( ∑ i = 1 K [ η i t W t + η i l W l + η i r W r ] x i + b ) \mathbf{y}=\tanh \left(\sum_{i=1}^{K}\left[\eta_{i}^{t} \mathbf{W}^{t}+\eta_{i}^{l} \mathbf{W}^{l}+\eta_{i}^{r} \mathbf{W}^{r}\right] \mathbf{x}_{i}+\mathbf{b}\right) y=tanh(i=1∑K[ηitWt+ηilWl+ηirWr]xi+b)
That is, for any node in the window , The weight matrix of convolution kernel makes different linear combinations according to the depth and position of the node in the window , To achieve the effect of tree convolution .
After convolution, each node gets an eigenvector ,InferCode Use attention Instead of maxpooling, Aggregate the information of all nodes , Get the vector representation of the code fragment . Through a learnable attention Vector implementation :

Final v ⃗ \vec{v} v Is the vector representation of this code .
Prediction subtree
Note that we have extracted several subtree structures in data preprocessing , These subtree structures will form a dictionary L L L( The size in the source code is 10w), Each subtree is assigned a learnable vector representation , And then use softmax Structure represents the probability of the subtree in the code fragment :
for l i ∈ L : q ( l i ) = exp ( v ⃗ T ⋅ W i subtrees ) ∑ l j ∈ L exp ( v ⃗ T ⋅ W i subtrees ) \text { for } l_{i} \in L: q\left(l_{i}\right)=\frac{\exp \left(\vec{v}^{T} \cdot \mathbf{W}_{i}^{\text {subtrees }}\right)}{\sum_{l_{j} \in L} \exp \left(\vec{v}^{T} \cdot \mathbf{W}_{i}^{\text {subtrees }}\right)} for li∈L:q(li)=∑lj∈Lexp(vT⋅Wisubtrees )exp(vT⋅Wisubtrees )
So the essence here is to regard subtree as label, By judging the subtree label Whether it exists in the code , This will detect whether the vector representation learned from the code contains the information of the subtree , Or say The learned code represents the combination of subtree information .
therefore InferCode The training parameters are W type , W token , W t , W l , W r ∈ R D × D , a ∈ R D , W subtrees ∈ R ∣ L ∣ × D \mathbf{W}^{\text {type }}, \quad \mathbf{W}^{\text {token }}, \mathbf{W}^{t}, \mathbf{W}^{l}, \mathbf{W}^{r} \in \mathbb{R}^{D \times D}, a \in \mathbb{R}^{D}, \mathbf{W}^{\text {subtrees }} \in \mathbb{R}^{|L| \times D} Wtype ,Wtoken ,Wt,Wl,Wr∈RD×D,a∈RD,Wsubtrees ∈R∣L∣×D, The parameters are still very light .
assessment
Three unsupervised tasks : Code clustering 、 Clone detection and Cross language code search ; Two have supervisory tasks : Code classification 、 Code recommendation .
Code clustering
Two data sets :OJ dataset, contain 52000 individual C code snippet , Belong to 104 Classes ;Sortting Algorithm dataset,10 class Java Sort code , Each category contains 1000 Segment code .
Indicators to evaluate the clustering effect Adjusted Rand Index: use C Represents the actual classification ,K Represents the clustering result . Definition a For in C Are divided into the same category , stay K The number of instance pairs divided into the same cluster in . Definition b For in C Are divided into different categories , stay K The number of instance pairs divided into different clusters in . Definition Rand Index( Rand coefficient ):
R I = a + b ( n 2 ) R I=\frac{a+b}{\left(\begin{array}{l} n \\ 2 \end{array}\right)} RI=(n2)a+b
That is, choose any two samples from all samples , Clustering results and GroudTruth Agreement .**RI The closer to 1 The better .**Rand Index The clustering result of random partition cannot be guaranteed RI It's close to 0. therefore , Put forward Adjusted Rand index( Adjusted Rand coefficient ):
A R I = R I − E [ R I ] max ( R I ) − E [ R I ] A R I=\frac{R I-E[R I]}{\max (R I)-E[R I]} ARI=max(RI)−E[RI]RI−E[RI]
Clone detection
constructed 50000 Clone code pairs and 50000 Non cloned code pairs are used as positive samples and negative samples .
Cross language code search
Collected Java、C、C++、C# Code samples of specific algorithm implementation 3000 From left to right Rosetta Code, Random for each language 5000 Code files from Github in .
Code classification
Oversight tasks , stay InferCode Add a classifier to fine tune .
Code recommendation
Oversight tasks , stay InferCode Add one to the base softmax Layer fine tuning .
Agent task tab selection

In addition to the option of using subtrees as labels , You can also choose code token、 The method name is used as the prediction label of the pre training task
边栏推荐
- MySQL implements inserting data from one table into another table
- Table partition of MySQL
- 485通讯( 详解 )
- 【七】图层显示和标注
- 什么是CI/CD?
- Visualize the training process using tensorboard
- 软件测试面试题目:请你列举几个物品的测试方法怎么说?
- R language Visual scatter diagram, geom using ggrep package_ text_ The rep function avoids overlapping labels between data points (set the min.segment.length parameter to inf and do not add label segm
- 【高并发】通过源码深度分析线程池中Worker线程的执行流程
- shell基础知识(退出控制、输入输出等)
猜你喜欢

3.2.1 what is machine learning?

Alibaba cloud technology expert Qin long: reliability assurance is a must - how to carry out chaos engineering on the cloud?

Visualize the training process using tensorboard

Interviewer: "classmate, have you ever done a real landing project?"

PyTorch项目实战—FashionMNIST时装分类
Pytorch project practice - fashionmnist fashion classification

More accurate and efficient segmentation of organs-at-risk in radiotherapy with Convolutional Neural

Dr. water 2

2022.07.24(LC_6125_相等行列对)
![SSTI 模板注入漏洞总结之[BJDCTF2020]Cookie is so stable](/img/19/0b943019fe1c959c4b79035a814410.png)
SSTI 模板注入漏洞总结之[BJDCTF2020]Cookie is so stable
随机推荐
水博士2
MySQL exercise 2
Script set random user_ agent
Ansible
Feign use
logstash
1.1.1 welcome to machine learning
2022.07.24(LC_6124_第一个出现两次的字母)
Jenkins configuration pipeline
基于Caffe ResNet-50网络实现图片分类(仅推理)的实验复现
Create directories and subdirectories circularly
Does MySQL have flush privileges
mysql有 flush privileges 吗
Spirng @Conditional 条件注解的使用
Is the securities account opened by qiniu safe? How to open an account
[shutter -- layout] stacked layout (stack and positioned)
【Flutter -- 实例】案例一:基础组件 & 布局组件综合实例
【十一】矢量、栅格数据图例制作以及调整
WPF项目入门1-简单登录页面的设计和开发
[micro service ~sentinel] sentinel degradation, current limiting, fusing