当前位置:网站首页>Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly D
Memorizing Normality to Detect Anomaly: Memory-augmented Deep Autoencoder for Unsupervised Anomaly D
2022-06-21 06:04:00 【Wanderer001】
Reference resources Memory-augmented Deep Autoencoder for Unsupervised Anomaly D - cloud + Community - Tencent cloud
Abstract
Deep self coding has been widely used in anomaly detection . Through the training of normal data , The self encoder is expected to produce higher reconstruction error for abnormal input than for normal input , As a criterion for identifying anomalies . However , This assumption is not always true in practice . It was observed , Sometimes automatic encoder “ Generalization ” Well done , It can also reconstruct anomalies very well , Missed inspection leading to abnormality . In order to alleviate the disadvantage of anomaly detection based on self encoder , We recommend using memory modules to add self encoders , And develop an improved self encoder , It is called memory enhanced self encoder , namely MemAE. For a given input ,MemAE First get the encoding from the encoder , It is then used as a query to retrieve the memory items most relevant to the refactoring . In the training phase , The memory contents are updated , And are encouraged to represent prototype elements of normal data . In the test phase , Learning and memory are fixed , Select a small number of memory records from normal data for reconstruction . therefore , Reconstruction will tend to be close to a normal sample . Thus, the abnormal reconstruction error is enhanced , For anomaly detection .MemAE There are no assumptions about data types , So it applies to different tasks . Experiments on various datasets have proved that MemAE
It has good generalization and high effectiveness .
1、 brief introduction
Anomaly detection is an important task , It has important applications in many fields , Like video surveillance . Unsupervised anomaly detection , When only normal data samples are given , Learn a normal profile , Then, the samples that do not conform to the normal profile are identified as abnormal , Due to the lack of artificial Supervision , This is a challenge . It is worth noting that , When the data point is in a high-dimensional space ( The video ) In the middle of the day , The problem becomes more difficult , Because modeling high-dimensional data is notoriously challenging .
Depth auto encoder (Deep autoencoder, AE) It's a powerful tool , High dimensional data under unsupervised settings can be modeled . It consists of encoder and decoder , The former is used to obtain the compression code from the input , The latter is used to reconstruct data from encoding . Coding is essentially an information bottleneck that forces the network to extract typical patterns of high-dimensional data . In the context of anomaly detection ,AE It is usually trained by reconstructing the normal data to minimize the error , Then the reconstruction error is taken as the anomaly index . The reconstruction error of normal input is small , Because it is close to the training data , The reconstruction error of abnormal input is large .
However , This assumption does not always hold , Sometimes AE It can be very good “ Generalization ”, It can also reconstruct abnormal input very well . Assuming that the anomaly brings higher reconstruction error may be problematic in some way, because the input without training sample anomaly and reconstruction behavior anomaly should be unpredictable . If some abnormal and normal training data have the same composition pattern ( Such as the local edge of the image ), Or the decoder's ability to decode some abnormal codes “ Too strong ”,AE It is possible to reconstruct the anomaly well .
In order to reduce AEs The shortcomings of , We propose a memory module to increase the depth of self encoder , A new model memory enhanced self encoder is introduced , namely MemAE. For a given input ,MemAE It is not directly encoded into the decoder , Instead, it is used as a query to retrieve the most relevant items in memory . These items are then aggregated and passed to the decoder . say concretely , The above process is realized by using attention-based memory addressing . We further propose to use a differentiable hard contraction operator to induce the sparsity of memory addressing rights , This implicitly encourages memory items to approach queries in the feature space .
stay MemAE The training phase of , We update the memory contents together with the encoder and decoder . Due to the sparse solution strategy , encourage MemAE Model optimization and efficient use of a limited number of memory slots , Make the memory record the typical normal mode in the normal training data to obtain a lower average reconstruction error ( See chart 3). In the test phase , The content of learning and memory is fixed , And reconstruction will be obtained by using a small number of normal memory items , As the neighborhood of the input code . Since refactoring is to get the normal pattern in memory , So it's closer to normal data . therefore , If the input data is not similar to the normal data , Reconstruction errors are often highlighted , This is an anomaly . Schematic diagram 1 Shown . The proposed MemAE There is no need to make assumptions about data types , So it can usually be used to solve different tasks . We apply the proposed memo to various public anomaly detection data sets for different applications . A large number of experiments have proved that memes have good generalization and high effectiveness .





2、 Related work
Anomaly detection :
In unsupervised anomaly detection , Only normal samples are used as training data . therefore , Natural selection to deal with this problem is a kind of classification method , Such as a class of support vector machines and a deep class of networks , They try to learn the discriminant hyperplane around the normal sample . Unsupervised clustering method , Such as k-means Method and Gaussian mixture model (GMM), It is also used to build detailed profiles of normal data to identify anomalies . These methods usually encounter poor performance when dealing with high-dimensional data .
The method based on reconstruction assumes that models that only learn from normal data cannot accurately represent and reconstruct anomalies . Different technologies , Such as PCA Methods and sparse representations , Used to learn the representation of normal patterns . say concretely , Sparse representation method combines learning dictionary and sparse representation of normal data to detect anomalies . The restricted characteristic indicates that the performance is limited . Some recent work has trained automatic depth coders for anomaly detection . for example , A deep neural network based on structural energy is used to model the training samples .Zong Et al. Proposed to jointly model the coding characteristics and reconstruction error of the depth self encoder . Although the method based on refactoring has achieved good results , However, due to the unreasonable design of the representation of potential space , Limit its performance .
For key application scenarios , Specially designed a series of video anomaly detection methods .Kim and Grauman Use the probability of mixing PCA (MPPCA) To simulate optical flow characteristics .Mahadevan By blending dynamic textures (MDT) Modeling video .Lu Et al. Proposed an efficient sparse coding method based on multi dictionary .Zhao And others update the dictionary online . A method based on deep learning is proposed , Using information in the spatial and temporal domains .Hasan Et al. Used convolution AE Reconstruction error to detect anomalies .Zhao Et al. Proposed a reconstruction prediction method based on three-dimensional convolution .Luo And so on through a stack of RNN Iteratively update the sparse coefficients to detect anomalies in the video .Liu Et al. Lost through fusion gradient 、 Different techniques such as optical flow and adversarial training are used to train the frame prediction network . However , These methods lack a reliable mechanism to encourage the model to generate large reconstruction errors for anomalies .
Memory network :
Memory enhancement networks have attracted increasing interest in solving different problems .Graves Et al. Used external memory to expand the ability of neural networks , Content-based attention is used to address memory . Considering that memory can record information stably ,Santoro They use memory networks to deal with one-time learning problems . External memory is also used to generate multimodal data , To bypass the modal crash problem and preserve the detailed data structure .
3、 Memory enhanced self encoder
3.1、 overview
Proposed MemAE The model consists of three main components : Encoder ( Used to encode input and generate queries )、 decoder ( For refactoring ) And memory modules ( With memory and associated memory addressing operators ). Pictured 2 Shown , Given an input , The encoder first obtains the input code . By using encoded representations as queries , Memory modules retrieve the most relevant items in memory through attention based addressing operators , These items are then delivered to the decoder for reconstruction . In the process of training , The encoder and decoder are optimized , Minimize reconstruction errors . At the same time, the contents of the memory are updated , To record the prototype elements of the encoded normal data . Given a test sample , The model is reconstructed using only a limited number of normal patterns recorded in memory . therefore , Reconstruction is often close to normal samples , The reconstruction error of normal samples is small , The abnormal reconstruction error is large , Will be used as the criterion for anomaly detection .
3.2、 Encoder and decoder
The encoder is used to represent the input in the potential field of information . The encoded representation is executed as a query , To retrieve related items in memory . In our model , An encoder can be thought of as a query generator . Train the decoder , Take the retrieved memory as input , Reconstruct the sample .
Let's first define  Represents the data sampling domain ,
Represents the data sampling domain , Represents the code field . Make
Represents the code field . Make  For encoder ,
For encoder , Representative decoder . Given a sample
Representative decoder . Given a sample  , The encoder converts it into a coded representation
, The encoder converts it into a coded representation  ; The decoder is trained into a reverse mapping of a potential representation
; The decoder is trained into a reverse mapping of a potential representation  To domain by :
To domain by :

 and
and  Separately represented parameter encoder
Separately represented parameter encoder  And decoder
And decoder  Parameters of . At the suggestion of MemAE in , Use
Parameters of . At the suggestion of MemAE in , Use  To retrieve related memory items ;
To retrieve related memory items ; Is obtained using the retrieved item . For standard AE Model , Yes
Is obtained using the retrieved item . For standard AE Model , Yes  , Our method is agnostic to the structure of encoder and decoder , It can be specially selected for different applications .
, Our method is agnostic to the structure of encoder and decoder , It can be specially selected for different applications .
In the test , Given the sample  , We use ‘2- Mean square error of norm (MSE), namely
, We use ‘2- Mean square error of norm (MSE), namely ![]() , To measure the reconstruction quality , As a standard for anomaly detection .
, To measure the reconstruction quality , As a standard for anomaly detection .
3.3、 Memory module , Attention based sparse addressing
The memory module includes a memory for recording the prototype encoding mode and an attention based addressing operator for accessing the memory .
3.3.1、 Memory based representation
The memory is designed as a matrix  Contains fixed dimensions
Contains fixed dimensions  On
On  A real valued vector . For variables , We assume that and
A real valued vector . For variables , We assume that and  Have the same dimension , And make
Have the same dimension , And make  . Make the line vector
. Make the line vector  representative M Of the i That's ok ,
representative M Of the i That's ok ,![i \in [N]](http://img.inotgo.com/imagesLocal/202206/21/202206210550154271_73.gif) , among [N] For from 1 To N The integer set of . Every Represents a memory item . Given a query ( for example , code )
, among [N] For from 1 To N The integer set of . Every Represents a memory item . Given a query ( for example , code ) , The memory network gets
, The memory network gets  , Rely on a soft addressing vector
, Rely on a soft addressing vector  , as follows
, as follows

among  It's a row vector , The sum of its nonnegative terms is 1,
It's a row vector , The sum of its nonnegative terms is 1, Express Of the i term , Weight vector according to Calculation , Such as the type (3) Shown , Access to memory requires addressing rights . Hyperparameters Defines the maximum memory capacity . Although find the best for different data sets It's not easy , but MemAE Yes The setting of is not sensitive , It's lucky ( See 4.2 section ). Big enough N It works well for every data set .
Express Of the i term , Weight vector according to Calculation , Such as the type (3) Shown , Access to memory requires addressing rights . Hyperparameters Defines the maximum memory capacity . Although find the best for different data sets It's not easy , but MemAE Yes The setting of is not sensitive , It's lucky ( See 4.2 section ). Big enough N It works well for every data set .
3.3.2、Attention For memory location
stay MemAE in , memory  It is designed to explicitly record the prototype normal pattern in the training process . We define memory as content addressable memory , Adopt addressing scheme , According to memory items and queries Calculate the attention weight of the similarity . Pictured 1 Shown , We go through softmax Operation calculates each weight :
It is designed to explicitly record the prototype normal pattern in the training process . We define memory as content addressable memory , Adopt addressing scheme , According to memory items and queries Calculate the attention weight of the similarity . Pictured 1 Shown , We go through softmax Operation calculates each weight :

 Represents a similarity measure . Be similar to [32], We defined As cosine similarity :
Represents a similarity measure . Be similar to [32], We defined As cosine similarity :

Such as the type (3)、(4)、(5) Shown , Memory module retrieval and The most similar memory item , Get the expression . Due to the limitation of memory size and sparse addressing technology ( stay 3.3.3 Described in the section ), Only a few memory items can be addressed at a time . therefore , The beneficial behavior of memory modules can be explained as follows .
In the training phase ,MemAE The decoder in is limited to using only a small number of addressed memory items for reconstruction , Thus, the effective utilization of memory items is required . therefore , Reconstruction supervision forces memory to record the most representative prototype pattern in the input normal pattern . In the figure 3 in , We visualized a single memory socket that had been trained , This indicates that each single memory slot records the prototype normal pattern in the training data .
In the test phase , Memory after given training , Only normal patterns in memory can be extracted for reconstruction . therefore , Normal samples can be reconstructed well . contrary , The code of the abnormal input will be replaced by the retrieved normal mode , This leads to significant refactoring errors for exceptions ( See chart 4 Visual examples in ).
3.3.3、 Hard shrinkage of sparse addressing
As mentioned above , Performing a limited number of normal mode reconstructions in memory helps to generate large reconstruction errors in abnormal situations . Attention based addressing tends to approach this natural . However , Some exceptions may still have the opportunity to pass through a dense set of small elements w A complex combination of memory items to reconstruct well . To alleviate this problem , We use a hard shrink operation to promote  The sparsity of :
The sparsity of :

 It means the first one
It means the first one  Memory addressing weight vectors of entries shrink and shrink thresholds
Memory addressing weight vectors of entries shrink and shrink thresholds  Express . In the type (6) It is not easy to directly implement the backward direction of discontinuous functions in . For the sake of simplicity , in consideration of w All terms in are nonnegative , We use continuous ReLU The activation function rewrites the hard shrink operation to :
Express . In the type (6) It is not easy to directly implement the backward direction of discontinuous functions in . For the sake of simplicity , in consideration of w All terms in are nonnegative , We use continuous ReLU The activation function rewrites the hard shrink operation to :

among ![]() Also known as ReLU Activate ,
Also known as ReLU Activate , Is a very small positive scalar . In practice , Set the threshold Interval of values
Is a very small positive scalar . In practice , Set the threshold Interval of values ![[1/N,3/N]](http://img.inotgo.com/imagesLocal/202206/21/202206210550154271_77.gif) Results that can be rendered . After contraction , We go through
Results that can be rendered . After contraction , We go through ![]() Give Way
Give Way  Back to normal . adopt
Back to normal . adopt ![]() You will get a potential representation .
You will get a potential representation .
Sparse addressing encourages the model to use fewer but more relevant memory items to represent examples , So as to learn more information representation in memory . Besides , Be similar to [43] Sparse representation of , Encouraging sparse resolution weights is beneficial in tests due to memory It is training to adapt to sparsity w. Encourage sparsity  It will also alleviate this problem , Abnormal samples may be quite reconstructed with intensive processing weights . And sparse representation [43,24] comparison , This method obtains the required sparsity by an effective forward operation , Instead of iterative updates .
It will also alleviate this problem , Abnormal samples may be quite reconstructed with intensive processing weights . And sparse representation [43,24] comparison , This method obtains the required sparsity by an effective forward operation , Instead of iterative updates .
3.4、 Training
Given an inclusion  The data set of the sample
The data set of the sample ![]() , Give Way
, Give Way  Indicates that the reconstructed samples correspond to each training sample
Indicates that the reconstructed samples correspond to each training sample  . We first minimize the reconstruction error for each sample :
. We first minimize the reconstruction error for each sample :

among  - Norm is used to measure reconstruction error . set up
- Norm is used to measure reconstruction error . set up  For each sample
For each sample  Memory addressing weight of . In order to further improve
Memory addressing weight of . In order to further improve  The sparsity of , except Eq.(7) Outside the shrink operation in , We are also training to minimize Sparse regulator on . in consideration of All terms of are nonnegative , And
The sparsity of , except Eq.(7) Outside the shrink operation in , We are also training to minimize Sparse regulator on . in consideration of All terms of are nonnegative , And  , We minimize The entropy of :
, We minimize The entropy of :

type (7) Hard contraction operation and entropy loss formula in (9) Together, it promotes the sparsity of the generated addressing rights . For more detailed ablation studies and discussions, see 4.4 section .
Combined (8) Sum formula (9) Medium loss function , We will MemAE The training objectives of are :

 It's a hyper-parameter In the training . In practice ,
It's a hyper-parameter In the training . In practice , Leading to ideal results in all our experiments . In the process of training , Update memory through back propagation and gradient descent optimization M. In passing back , Only with non-zero addressing weight The gradient of a memory item can be non-zero .
Leading to ideal results in all our experiments . In the process of training , Update memory through back propagation and gradient descent optimization M. In passing back , Only with non-zero addressing weight The gradient of a memory item can be non-zero .
4、 experiment
In this section , We will verify the proposed anomaly detection MemAE. In order to prove the generality and applicability of the model , We performed experiments on five data sets of three different tasks . The result is different from baseline The model is compared with the most advanced technology . In the previous section , Suggested MemAE Apply to all datasets .MemAE And its variants PyTorch[28] Realization , And use the optimizer Adam[15] Training , The learning rate is 0.0001. We associate them with VAE Other codec models have similar model capacity .
4.1、 Experiments on image data
We first detect outliers in images [31] The experiment of , And two image data sets MNIST and CIFAR-10 The performance of the system is evaluated , Both data sets contain data belonging to 10 Class . For each data set , We extract images from each class as normal samples , Take exception samples from the rest of the classes , structure 10 Exception detection ( That is, a class of classification ) Data sets . Normal data is divided into training and test sets , The ratio is 2:1. according to [42,47] Set up , The training set contains only normal samples , There is no overlap with the test set , Abnormal propositions are controlled in 30% about . Of the original training data 10% For verification .
In this experiment , We focus on verifying the proposed memory module , The encoder and decoder are implemented as pure convolutional neural network . We first define Conv2( ,
, ,
, ) Represents a two-dimensional convolution layer , among 、、 Respectively kernel size、stride size and kernel Number . about MNIST, We use three convolution layers to implement the encoder :Conv2(1,2,16)-Conv2(3,2,32)-Conv2(3,2,64). The decoder is implemented as Dconv2(3,2,64)-Dconv2(3,2,32)-Dconv2(3,2,1), among Dconv2 It is a two-dimensional deconvolution layer . Except for the last one Dconv2 Outside , There is a batch standardization behind each layer (BN)[11] and ReLU Activate [26]. This design applies to all of the following datasets . consider CIFAR-10 Higher data complexity , The encoders and decoders we use are powerful :Conv2 (3 2 64) -Conv2 (3 2 128) -Conv2 (3 2 128) -Conv2(3 2, 256) and Dconv2 (3 2 256) -Dconv2 (3 2 128) -Dconv2 (3 2 128) -Dconv2(3 2 3). We deal with MNIST CIFAR-10 Gray image and RGB Image data set , , respectively, .MNIST and CIFAR-10 The memory size of N Set as 100 and 500.
) Represents a two-dimensional convolution layer , among 、、 Respectively kernel size、stride size and kernel Number . about MNIST, We use three convolution layers to implement the encoder :Conv2(1,2,16)-Conv2(3,2,32)-Conv2(3,2,64). The decoder is implemented as Dconv2(3,2,64)-Dconv2(3,2,32)-Dconv2(3,2,1), among Dconv2 It is a two-dimensional deconvolution layer . Except for the last one Dconv2 Outside , There is a batch standardization behind each layer (BN)[11] and ReLU Activate [26]. This design applies to all of the following datasets . consider CIFAR-10 Higher data complexity , The encoders and decoders we use are powerful :Conv2 (3 2 64) -Conv2 (3 2 128) -Conv2 (3 2 128) -Conv2(3 2, 256) and Dconv2 (3 2 256) -Dconv2 (3 2 128) -Dconv2 (3 2 128) -Dconv2(3 2 3). We deal with MNIST CIFAR-10 Gray image and RGB Image data set , , respectively, .MNIST and CIFAR-10 The memory size of N Set as 100 and 500.
We compare this model with several traditional and general anomaly detection methods based on deep learning as a baseline , Including seeing below SVM (OCSVM), Nuclear density estimates (KDE), Deep variation autoencoder (VAE), Deep autoregressive model generation PixCNN And deep structure energy model (DSEBM). say concretely , For density estimation methods ( Such as KDE and PixCNN) And refactoring based approaches ( Such as VAE and DSEBM), Separate use log-likelihood And reconstruction error to calculate the regularity score . Be careful , In order to make a fair comparison with other methods , We only calculate based on reconstruction error VAE Regularity score . We also work with some MemAE The baseline variables were compared , To show the importance of the main components , Include antueocoder No memory module (AE) and MemAE The variant of has no sparse shrinkage and entropy loss (MemAE- nonspar). In all the experiments ,AE、MemAE- nonspar and VAE Use the same encoder and decoder , And the whole MemAE Models have similar capabilities . In the test , We extend the reconstruction error to [0; As a criterion for identifying exceptions . stay [25,24,1] after , We use AUC (Area Under Curve) As a measure of performance ,AUC By calculating the operating characteristics of the receiver with variable threshold (Receiver Operation Characteristic, ROC) The area under the . surface 1 Shows 10 Average of sampled data sets AUC value .

As shown in the table 1 Shown , The proposed MemAE Usually better than the method of comparison . The memory enhancement model was significantly better than that without memory AE Model . With sparse addressing MemAE The model gets good results .MNIST The image in contains only simple patterns , The digital , Easy to modeling .VAE A simple Gaussian distribution is used to model the potential space , Satisfactory results can be obtained . All the ways in MNIST The performance is better than CIFAR-10, because CIFAR-10 Images in have more complex content , And show greater intra class variance on multiple classes , This led to the ACU The unevenness of . But in the comparison model of similar capacity ,MemAE Better performance than competitors , The validity of the proposed memory module is proved .
4.1.1、 Imagine how memory works
in consideration of MNIST The image in contains patterns that are easy to recognize , We use it to show how the proposed memory module can be used for exception detection .
Remember what you learned :
We start by randomly sampling a single memory slot and decoding it , Thus, the memory is changed from MNIST Visualize what you've learned . chart 3 What will be learned MNIST Numbers “9” As a normal sample for visual processing . because MemAE Refactoring is usually done by a combination of several addressing terms , Therefore, the decoded single slot will appear fuzzy and noisy . However , Pictured 3(b) Shown , Memory slots record different prototype patterns of normal training samples ( The digital “9”).

How memories can be enhanced and reconstructed
In the figure 4 in , We visualized the process of image reconstruction under memory enhancement . Because the memory after training only records the normal prototype pattern , When the input exception is “9” when , After training MemAE take “5” Refactor to “5”, The reconstruction error resulting in abnormal input is significant . Be careful ,MemAE Reconstructed “5” With input “9” Shape similarity , Because the memory module retrieves the most similar normal mode . Memoryless AE models tend to learn some representations locally . therefore , Abnormal samples can also be well reconstructed .

4.2、 Experiments on video anomaly detection
The purpose of video anomaly detection is to identify abnormal content and movement patterns in video , It is an indispensable work in video surveillance . We are in UCSD-Ped2、CUHK Avenue and ShanghaiTech Experiments are carried out on three real video anomaly detection data sets . say concretely , The latest benchmark data set ShanghaiTech Contains more than 270,000 Training frames and more than 42,000 Test frames ( Which about 17,000 Exception frames ), covers 13 A different scene . In the data set , Pedestrian exclusion ( Such as vehicle ) And vigorous exercise ( Such as fighting and chasing ) Objects outside are considered abnormal .
In order to keep the time information of the video , We use three-dimensional convolution to realize the encoder and decoder to extract the spatiotemporal features of video . therefore , The input to the network is a function of 16 A box formed by superimposing gray levels of adjacent frames . The structure design of encoder and decoder is :Conv3(3,2,96)-Conv3(3,2,128)-Conv3(3,2,256)-Conv3(3,2,256)-Dconv3(3,2,256)-Dconv3(3,2,128)-Dconv3(3,2,1), among Conv3 and Dconv3 Represent three-dimensional convolution and deconvolution respectively .BN and ReLU The activation of follows each layer ( Except for the last floor ). set up N = 2000. Considering the complexity of video data , We let each memory slot record the characteristics of a pixel , Corresponding to a sub region of the video clip . therefore , Memory is a 2000×256 Matrix . In the test , The normality of each frame is evaluated by the reconstruction error of the box centered on it . stay [9,24] after , By normalizing the error to [0,1] To get the second  The abnormal score of the frame
The abnormal score of the frame  :
:

In style , Represents the video clip No Frame reconstruction error . The closer the value is. 0, It indicates that the frame is more likely to be an abnormal frame . From the picture 5 It can be seen that , When an exception occurs in a video frame ,MemAE The normality score will immediately decrease .
Represents the video clip No Frame reconstruction error . The closer the value is. 0, It indicates that the frame is more likely to be an abnormal frame . From the picture 5 It can be seen that , When an exception occurs in a video frame ,MemAE The normality score will immediately decrease .
Because of the complexity of video data , Many general anomaly detection methods without specific design can not be well applied to video . Displays the validity of the memory module , We suggest that MemAE Many well-designed state-of-the-art methods based on reconstruction include AE And 2D and 3D Convolution (AE-Conv2D and AE-Conv3D),temporally-coherent Sparse coding method (TST), A bunch of recurrent neural networks (StackRNN), Many video anomaly detection baselines .MemAE The variant of is also used as baseline Compare .

surface 2 Shows... On the video dataset AUC value .MemAE The result is better than TSC and StackRNN It's much better , These two methods also use sparse regularization . And AE and MemAE-nonSpar The comparison shows that , Memory modules with sparse addressing are beneficial . chart 6 Shows UCSD-Ped2 Reconstruction error of an abnormal frame in .MemAE The error map of clearly highlights the abnormal events ( Vehicles and bicycles move on the sidewalk ), Results in lower normality scores . but AE It can better reconstruct the anomaly , And produce some random errors .
Compared with other methods , What this article puts forward MemAE Have better or comparable performance , Our model solves a more general problem , It can be flexibly applied to different types of data . This method only uses reconstruction error , With the least knowledge of specific applications , You can get better results . Even with methods that use many non reconstruction techniques for video data [22]( It's a watch 2 Medium frame - pred) comparison , Such as optical flow 、 Frame prediction 、 Resistance loss, etc , The proposed MemAE The performance of is still comparable . Please note that , Our experimental goal is not to pursue the highest accuracy in some applications , But to demonstrate AE( namely MemAE) The advantages of the improved scheme in general anomaly detection . Our research and [22] It is orthogonal. , Can be easily incorporated into their systems , To further improve performance . On the other hand ,[22] The techniques in can also be used in the proposed MemAE.
Memory Dimensional robustness :
We use UCSD-Ped2 The research puts forward MemAE For memory size n The robustness of . We experimented with different memory size settings , And in the picture 7 It shows that AUC value . Given a large enough memory size ,MemAE It can steadily produce plausible results .




The elapsed time :
We use NVIDIA GeForce 1080 Ti Graphics card pair UCSDPed2 The computational complexity of video data sets is studied . What this article puts forward MemAE Average per frame ( namely 38 frame ) The video anomaly detection time of is 0.0262 second , Compared with the previous advanced method based on deep learning ( If you use 0.04s Of 、 Use 0.02s Of [24] And use 0.05s1 Of [36]) comparison , Reaching the standard or faster . Besides , And every frame 0.0266s Baseline AE The model compares , Our memory modules ( stay MemAE in ) There is little extra computing time ( That is, every frame 4×10−4 second ).
4.3、 Network security data experiment
In order to further verify the generality of this method , We have conducted experiments on a widely used network security dataset other than computer vision applications , From UCI Knowledge base KDDCUP99 10% Data sets . according to [47] Settings in , The original dataset is marked as “ attack ” In a sample of 80% Is considered a normal sample . Each sample can be organized into one with 120 dimension [47] Vector . We use the full layer (FC) Point out the implementation of encoder and decoder FC(120 year 60)FC (60, 30)、FC (30、10)、FC(10, 3) and FC (3, 10)、FC (10、30)、FC (30、60)、FC(120), stay FC (,  ) Express FC Layer input and output sizes and . Expect the last , Every FC The layer is immediately followed by a hyperbolic tangent activation . This structure is related to [47] Models in have similar capacities . set up
) Express FC Layer input and output sizes and . Expect the last , Every FC The layer is immediately followed by a hyperbolic tangent activation . This structure is related to [47] Models in have similar capacities . set up  , Memory size is 50×3.
, Memory size is 50×3.
just as [42,47] Proposed , We randomly selected 50% Data for training , The rest is for testing . Only use the data samples of normal classes for training . stay KDDCUP On dataset , We compare the proposed method with the most advanced method before , Include OC-SVM、 Deep clustering network (DCN)、DSEBM、DAGMM and MemAE Of baseline Variable . According to the standard [47] agreement , Use 20 Average accuracy after times of operation 、 Recall rate and F1 Score to evaluate these methods . Because data modeling is more effective ,DAGMM And the proposed model has good performance . This method can explicitly remember “ attack ” The behavior pattern of the sample , It has good performance .
4.4、 Melting research
In the previous chapter , Yes MemAE And its variants , namely AE and MemAE- nonspar The importance of the main components of the proposed approach has been demonstrated by extensive comparisons of . In this section , We will conduct further ablation studies , To study other different ingredients in detail .
4.4.1、 Research involving sparse components
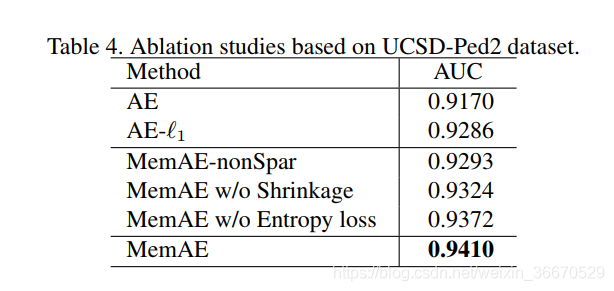
As mentioned earlier , We use two components to induce the sparsity of memory addressing rights , Namely in form (6) The hard threshold contraction defined in and is expressed in (10) Entropy loss as defined in  . We did experiments , Study the importance of each component by removing another component . surface 4 Data sets are recorded UCSD-Ped2 Upper AUC. As shown in the table 4 Shown , Removing the contraction operator or entropy loss will degrade the performance . No hard shrinkage , Models do not directly encourage sparsity in testing , This may cause too much noise in the non sparse memory addressing weights . When the under trained model produces the non optimized addressing weight at the initial stage of training , Entropy loss plays a crucial role .
. We did experiments , Study the importance of each component by removing another component . surface 4 Data sets are recorded UCSD-Ped2 Upper AUC. As shown in the table 4 Shown , Removing the contraction operator or entropy loss will degrade the performance . No hard shrinkage , Models do not directly encourage sparsity in testing , This may cause too much noise in the non sparse memory addressing weights . When the under trained model produces the non optimized addressing weight at the initial stage of training , Entropy loss plays a crucial role .
4.4.2、 And sparse regularization
MemAE Sparse memory addressing in derives a style of automatic encoder , This leads to the sparsity of the encoder output ( Activate ). So we do a simple experiment to compare with sparse regularization autoencoder MemAE Characteristics of coding , This is achieved directly through minimization “ -norm Latent compression properties , namely
-norm Latent compression properties , namely  、 During training , be called AE - , This is related to MemAE Share the same encoder and decoder . As shown in the table 4 Shown ,AE- Its performance is close to MemAE-nonSpar, Due to its sparsity, regularization is induced , Its performance is better than AE. However ,AE- There is still a lack of a clear mechanism to encourage large reconstruction errors for exceptions , Or lack a powerful module to model the prototype pattern of normal samples , Resulting in a performance ratio MemAE And others MemAE Variation is poor .
、 During training , be called AE - , This is related to MemAE Share the same encoder and decoder . As shown in the table 4 Shown ,AE- Its performance is close to MemAE-nonSpar, Due to its sparsity, regularization is induced , Its performance is better than AE. However ,AE- There is still a lack of a clear mechanism to encourage large reconstruction errors for exceptions , Or lack a powerful module to model the prototype pattern of normal samples , Resulting in a performance ratio MemAE And others MemAE Variation is poor .
5、 Conclusion
In order to improve the performance of self encoder based on unsupervised anomaly detection , A memory enhanced self encoder is proposed . For a given input , Suggested MemAE First, use the encoder to obtain the encoded representation , Then use the encoding as a query to retrieve the most relevant schema in memory for reconstruction . Because memory training is used to record typical normal patterns , The proposed MemAE The normal sample can be reconstructed well , And amplify the abnormal reconstruction error , This makes the reconstruction error the criterion of anomaly detection . Through experiments on different application datasets , The generality and effectiveness of the method are verified . some time , We will study how to use addressing rights for exception detection . Considering that the proposed memory module is universal , And do not know the structure of encoder and decoder , We will integrate it into a more complex basic model , And apply it to more challenging applications .
边栏推荐
- 代码生成器文件运行出错:The server time zone value ‘�й���ʱ��‘ is unrecognized or represents more than one time
- 微生物生态排序分析——CCA分析
- TF. Auto Fonction de réserve
- MySQL MySQL mysqldump data backup and incremental backup
- Detailed explanation of balanced binary tree is easy to understand
- 用代码生成器 生成代码后复制完成,在网页上不显示模块
- DP背包总结
- 三维引擎软件Vizard入门
- Do you want to manually implement CSDN dark mode for web page '?
- Touch chip applied in touch screen of washing machine
猜你喜欢

应用在电视触摸屏中的十四通道智能触摸芯片
![[MySQL] SQL statement execution process of MySQL](/img/c8/76726de7ae3521f709e336a60ae3a2.png)
[MySQL] SQL statement execution process of MySQL
![[MYSQL] MYSQL文件结构,页与行记录](/img/e3/8b6c39f299679522d84cad64af7a42.png)
[MYSQL] MYSQL文件结构,页与行记录

After the code is generated by the code generator, the copy is completed, and the module is not displayed on the web page

【数据挖掘】期末复习 第二章

浅谈美国ESS音频DAC解码芯片ES9023

深度理解RNN的梯度消失和LSTM为什么能解决梯度消失

Sub-Category Optimization for Multi-View Multi-Pose Object Detection

构建和保护小型网络考试

C language course design (detailed explanation of clothing management system)
随机推荐
Interprocess communication (IPC): semaphores
C common chart components
Connection refused : no futher information : localhost/127.0.0.1:6379
直击2022互联网大裁员:繁花落地,一地鸡毛
Do you want to manually implement CSDN dark mode for web page '?
浅谈美国ESS音频DAC解码芯片ES9023
Microbial ecological data analysis - redundancy analysis
pyshark使用教程
Improve the determination of the required items of business details. When the error information is echoed according to the returned status code, the echoed information is inconsistent with the expecta
Touch chip applied in touch screen of washing machine
Laravel
Leetcode刷题 ——— (4)字符串中的第一个唯一字符
C language course design (detailed explanation of clothing management system)
FPGA - 7系列 FPGA SelectIO -04- 逻辑资源之IDELAY和IDELAYCTRL
Metasploit intrusion win7
[MySQL] SQL statement execution process of MySQL
数字式温度传感器工作原理以及测温原理分析
【JVM】方法区
You have an error in your SQL syntax; check the manual that corresponds to your MYSQL server
tf.compat.v1.MetaGraphDef