当前位置:网站首页>Pytoch learning notes -- seresnet50 construction
Pytoch learning notes -- seresnet50 construction
2022-07-25 15:41:00 【whut_ L】
Catalog
4-- Use of examples SEResNet50 Implement datasets CIFAR10 classification
1--ResNet50 Introduce

analysis : The picture above shows ResNet50 Overall structure , except Input and Output Out of link , Also contains 5 A link :Stem Block link 、Stage1-4 Links and Subsequent Processing link .
1-1--Stem Block link

analysis :Stem Block Link of Input It's a three channel (C = 3, W = 224, H = 224) Image , First pass through Convolution operation (kernel_size = 7 x 7,stride = 2, Number of convolution kernels = 64 )、 Normalization operation 、RELU operation , after Maximum pooling operation obtain Output(C = 64, W = 56, H = 56), This link can be understood as four Stage Pretreatment before , The core code is as follows :
self.Stem = nn.Sequential(
nn.Conv2d(3, 64, kernel_size = 7, stride = 2, padding = 3, bias = False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 1)
)1-2--Stage link

The picture above shows 4 individual Stage Link network structure , Every Stage There are two network structures :Conv Block structure and Identity Block structure .
With Stage1 As an example, the differences between the two structures are analyzed :

Visible from above :Conv Block structure Than Identity Block structure One more on the right Conv and BN operation , Build two Block The core code is as follows :
## Import third-party library
import torch
from torch import nn
# build Conv Block and Identity Block Network structure
class Block(nn.Module):
def __init__(self, in_channels, filters, stride = 1, is_1x1conv = False):
super(Block, self).__init__()
# each Stage The output dimension of each block in the , namely channel(filter1 = filter2 = filter3 / 4)
filter1, filter2, filter3 = filters
self.is_1x1conv = is_1x1conv # Judge whether it is Conv Block
self.relu = nn.ReLU(inplace = True) # RELU operation
# The first piece , stride = 1(stage = 1) or stride = 2(stage = 2, 3, 4)
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, filter1, kernel_size = 1, stride = stride, bias = False),
nn.BatchNorm2d(filter1),
nn.ReLU()
)
# A small piece in the middle
self.conv2 = nn.Sequential(
nn.Conv2d(filter1, filter2, kernel_size=3, stride = 1, padding = 1, bias=False),
nn.BatchNorm2d(filter2),
nn.ReLU()
)
# The last piece , There is no need for ReLu operation
self.conv3 = nn.Sequential(
nn.Conv2d(filter2, filter3, kernel_size = 1, stride = 1, bias=False),
nn.BatchNorm2d(filter3),
)
# Conv Block Input of requires additional Conv and BN operation ( combination Conv Block Network diagram understanding )
if is_1x1conv:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, filter3, kernel_size = 1, stride = stride, bias = False),
nn.BatchNorm2d(filter3)
)
def forward(self, x):
x_shortcut = x # The transmission value on the right in the network diagram
x1 = self.conv1(x) # Execute the first small Block operation
x1 = self.conv2(x1) # Execute the middle small Block operation
x1 = self.conv3(x1) # Execute the last small Block operation
if self.is_1x1conv: # Conv Block Make additional Conv and BN operation
x_shortcut = self.shortcut(x_shortcut)
x1 = x1 + x_shortcut # Add operation
x1 = self.relu(x1) # ReLU operation
return x1Detail analysis :
- Every Stage As the next Stage The input of ;
- Stage1 and Stage2-4 Of Conv Block In structure , The first one on the left and right Block Medium stride Different values .(Stage1: stride = 1; Stage2-4: stride = 2);
- Whether it's Conv Block still Identity Block, The last little Block Of channel Are the first and the middle small Block Of channel Four times the size of .
- Whether it's Conv Block still Identity Block, The last little Block No, RELU operation ( Compared with the previous two small Block)

1-3--ResNet50 Core code :
# build ResNet50
class Resnet(nn.Module):
def __init__(self, cfg):
super(Resnet, self).__init__()
classes = cfg['classes'] # Category of classification
num = cfg['num'] # ResNet50[3, 4, 6, 3];Conv Block and Identity Block The number of
# Stem Block
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size = 7, stride = 2, padding = 3, bias = False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 1)
)
# Stage1
filters = (64, 64, 256) # channel
self.Stage1 = self._make_layer(in_channels = 64, filters = filters, num = num[0], stride = 1)
# Stage2
filters = (128, 128, 512) # channel
self.Stage2 = self._make_layer(in_channels = 256, filters = filters, num = num[1], stride = 2)
# Stage3
filters = (256, 256, 1024) # channel
self.Stage3 = self._make_layer(in_channels = 512, filters = filters, num = num[2], stride = 2)
# Stage4
filters = (512, 512, 2048) # channel
self.Stage4 = self._make_layer(in_channels = 1024, filters = filters, num = num[3], stride = 2)
# The average pooling
self.global_average_pool = nn.AdaptiveAvgPool2d((1, 1))
# Fully connected layer Here can be understood as four in the network Stage After Subsequent Processing link
self.fc = nn.Sequential(
nn.Linear(2048, classes)
)
# Single form Stage Network structure
def _make_layer(self, in_channels, filters, num, stride = 1):
layers = []
# Conv Block
block_1 = Block(in_channels, filters, stride = stride, is_1x1conv = True)
layers.append(block_1)
# Identity Block Structural superposition ; be based on [3, 4, 6, 3]
for i in range(1, num):
layers.append(Block(filters[2], filters, stride = 1, is_1x1conv = False))
# return Conv Block and Identity Block Set , To form a Stage Network structure
return nn.Sequential(*layers)
def forward(self, x):
# Stem Block link
x = self.conv1(x)
# Carry out four Stage link
x = self.Stage1(x)
x = self.Stage2(x)
x = self.Stage3(x)
x = self.Stage4(x)
# perform Subsequent Processing link
x = self.global_average_pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x2--SENet Introduce
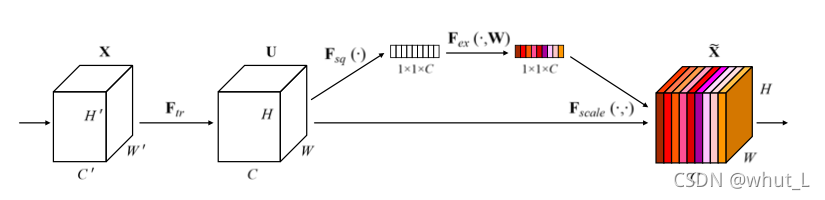
analysis : The above figure is taken from the literature 《Squeeze-and-Excitation Networks》,SENet The intuitive understanding of the original image is all The channel is weighted , The following figure shows the main process of its weighting operation .

analysis : It can be seen from the above figure , Weight the original image , Mainly through Global average pooling 、 Fully connected linear layer 、ReLU operation 、 Fully connected linear layer as well as Sigmoid function Get the weight value of each channel , Re pass Scale( The product of ) operation Complete weighting . In the example , use The convolution layer replaces the full connection layer , Try to reduce the semantic loss of pictures , Calculation The core code of weighting matrix as follows :
# SENet( combination SENet Network diagram understanding )
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)), # Global average pooling
nn.Conv2d(filter3, filter3 // 16, kernel_size=1), # 16 Express r,filter3//16 Express C/r, Here, the convolution layer is used instead of the full connection layer
nn.ReLU(),
nn.Conv2d(filter3 // 16, filter3, kernel_size=1),
nn.Sigmoid()
)3--SEResNet50 Introduce

analysis : The picture above will SENet Added to the Residual Module , the SENet Add module to ResNet in Conv Block and Identity Block Of The last little Block after . be based on SENet build Conv Block and Identity Block Of Core code as follows :
# Set up based on SENet Of Conv Block and Identity Block Network structure
class Block(nn.Module):
def __init__(self, in_channels, filters, stride = 1, is_1x1conv = False):
super(Block, self).__init__()
# each Stage The output dimension of each block in the , namely channel(filter1 = filter2 = filter3 / 4)
filter1, filter2, filter3 = filters
self.is_1x1conv = is_1x1conv # Judge whether it is Conv Block
self.relu = nn.ReLU(inplace = True) # RELU operation
# The first piece , stride = 1(stage = 1) or stride = 2(stage = 2, 3, 4)
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, filter1, kernel_size = 1, stride = stride, bias = False),
nn.BatchNorm2d(filter1),
nn.ReLU()
)
# A small piece in the middle
self.conv2 = nn.Sequential(
nn.Conv2d(filter1, filter2, kernel_size=3, stride = 1, padding = 1, bias=False),
nn.BatchNorm2d(filter2),
nn.ReLU()
)
# The last piece , There is no need for ReLu operation
self.conv3 = nn.Sequential(
nn.Conv2d(filter2, filter3, kernel_size = 1, stride = 1, bias=False),
nn.BatchNorm2d(filter3),
)
# Conv Block The input of requires additional convolution and normalization ( combination Conv Block Network diagram understanding )
if is_1x1conv:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, filter3, kernel_size = 1, stride = stride, bias = False),
nn.BatchNorm2d(filter3)
)
# SENet( combination SENet Network diagram understanding )
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)), # Global average pooling
nn.Conv2d(filter3, filter3 // 16, kernel_size=1), # 16 Express r,filter3//16 Express C/r, Here, the convolution layer is used instead of the full connection layer
nn.ReLU(),
nn.Conv2d(filter3 // 16, filter3, kernel_size=1),
nn.Sigmoid()
)
def forward(self, x):
x_shortcut = x
x1 = self.conv1(x) # Execute the first Block operation
x1 = self.conv2(x1) # Execute intermediate Block operation
x1 = self.conv3(x1) # Execute the last Block operation
x2 = self.se(x1) # utilize SENet Calculate the weight of each channel
x1 = x1 * x2 # Weight the original channel
if self.is_1x1conv: # Conv Block Perform additional convolution normalization
x_shortcut = self.shortcut(x_shortcut)
x1 = x1 + x_shortcut # Add operation
x1 = self.relu(x1) # ReLU operation
return x1
4-- Use of examples SEResNet50 Implement datasets CIFAR10 classification
Direct running code ( Detailed notes ):
## Import third-party library
from torch import nn
import time
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import torch.optim as optim
# Set up based on SENet Of Conv Block and Identity Block Network structure
class Block(nn.Module):
def __init__(self, in_channels, filters, stride = 1, is_1x1conv = False):
super(Block, self).__init__()
# each Stage The output dimension of each block in the , namely channel(filter1 = filter2 = filter3 / 4)
filter1, filter2, filter3 = filters
self.is_1x1conv = is_1x1conv # Judge whether it is Conv Block
self.relu = nn.ReLU(inplace = True) # RELU operation
# The first piece , stride = 1(stage = 1) or stride = 2(stage = 2, 3, 4)
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, filter1, kernel_size = 1, stride = stride, bias = False),
nn.BatchNorm2d(filter1),
nn.ReLU()
)
# A small piece in the middle
self.conv2 = nn.Sequential(
nn.Conv2d(filter1, filter2, kernel_size=3, stride = 1, padding = 1, bias=False),
nn.BatchNorm2d(filter2),
nn.ReLU()
)
# The last piece , There is no need for ReLu operation
self.conv3 = nn.Sequential(
nn.Conv2d(filter2, filter3, kernel_size = 1, stride = 1, bias=False),
nn.BatchNorm2d(filter3),
)
# Conv Block The input of requires additional convolution and normalization ( combination Conv Block Network diagram understanding )
if is_1x1conv:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, filter3, kernel_size = 1, stride = stride, bias = False),
nn.BatchNorm2d(filter3)
)
# SENet( combination SENet Network diagram understanding )
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)), # Global average pooling
nn.Conv2d(filter3, filter3 // 16, kernel_size=1), # 16 Express r,filter3//16 Express C/r, Here, the convolution layer is used instead of the full connection layer
nn.ReLU(),
nn.Conv2d(filter3 // 16, filter3, kernel_size=1),
nn.Sigmoid()
)
def forward(self, x):
x_shortcut = x
x1 = self.conv1(x) # Execute the first Block operation
x1 = self.conv2(x1) # Execute intermediate Block operation
x1 = self.conv3(x1) # Execute the last Block operation
x2 = self.se(x1) # utilize SENet Calculate the weight of each channel
x1 = x1 * x2 # Weight the original channel
if self.is_1x1conv: # Conv Block Perform additional convolution normalization
x_shortcut = self.shortcut(x_shortcut)
x1 = x1 + x_shortcut # Add operation
x1 = self.relu(x1) # ReLU operation
return x1
# build SEResNet50
class SEResnet(nn.Module):
def __init__(self, cfg):
super(SEResnet, self).__init__()
classes = cfg['classes'] # Category of classification
num = cfg['num'] # ResNet50[3, 4, 6, 3];Conv Block and Identity Block The number of
# Stem Block
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size = 7, stride = 2, padding = 3, bias = False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 1)
)
# Stage1
filters = (64, 64, 256) # channel
self.Stage1 = self._make_layer(in_channels = 64, filters = filters, num = num[0], stride = 1)
# Stage2
filters = (128, 128, 512) # channel
self.Stage2 = self._make_layer(in_channels = 256, filters = filters, num = num[1], stride = 2)
# Stage3
filters = (256, 256, 1024) # channel
self.Stage3 = self._make_layer(in_channels = 512, filters = filters, num = num[2], stride = 2)
# Stage4
filters = (512, 512, 2048) # channel
self.Stage4 = self._make_layer(in_channels = 1024, filters = filters, num = num[3], stride = 2)
# Adaptive average pooling ,(1, 1) Indicates the size of the output (H x W)
self.global_average_pool = nn.AdaptiveAvgPool2d((1, 1))
# Fully connected layer Here can be understood as four in the network Stage After Subsequent Processing link
self.fc = nn.Sequential(
nn.Linear(2048, classes)
)
# Single form Stage Network structure
def _make_layer(self, in_channels, filters, num, stride = 1):
layers = []
# Conv Block
block_1 = Block(in_channels, filters, stride = stride, is_1x1conv = True)
layers.append(block_1)
# Identity Block Structural superposition ; be based on [3, 4, 6, 3]
for i in range(1, num):
layers.append(Block(filters[2], filters, stride = 1, is_1x1conv = False))
# return Conv Block and Identity Block Set , To form a Stage Network structure
return nn.Sequential(*layers)
def forward(self, x):
# Stem Block link
x = self.conv1(x)
# Carry out four Stage link
x = self.Stage1(x)
x = self.Stage2(x)
x = self.Stage3(x)
x = self.Stage4(x)
# perform Subsequent Processing link
x = self.global_average_pool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# SeResNet50 Parameters of ( Note that calling this function will indirectly call SEResnet, A separate function is written here to facilitate modification to other ResNet The structure of the network )
def SeResNet50():
cfg = {
'num':(3, 4, 6, 3), # ResNet50, four Stage in Block The number of ( among Conv Block by 1 individual , The rest are increased Identity Block)
'classes': (10) # Number of data set classifications
}
return SEResnet(cfg) # call SEResnet The Internet
## Import dataset
def load_dataset(batch_size):
# Download training set
train_set = torchvision.datasets.CIFAR10(
root = "data/cifar-10", train = True,
download = True, transform = transforms.ToTensor()
)
# Download test set
test_set = torchvision.datasets.CIFAR10(
root = "data/cifar-10", train = False,
download = True, transform = transforms.ToTensor()
)
train_iter = torch.utils.data.DataLoader(
train_set, batch_size = batch_size, shuffle = True, num_workers = 4
)
test_iter = torch.utils.data.DataLoader(
test_set, batch_size = batch_size, shuffle = True, num_workers = 4
)
return train_iter, test_iter
# Training models
def train(net, train_iter, criterion, optimizer, num_epochs, device, num_print, lr_scheduler = None, test_iter = None):
net.train() # Training mode
record_train = list() # Record each Epoch Accuracy of lower training set
record_test = list() # Record each Epoch The accuracy of the next test set
for epoch in range(num_epochs):
print("========== epoch: [{}/{}] ==========".format(epoch + 1, num_epochs))
total, correct, train_loss = 0, 0, 0
start = time.time()
for i, (X, y) in enumerate(train_iter):
X, y = X.to(device), y.to(device) # GPU or CPU function
output = net(X) # Calculate the output
loss = criterion(output, y) # Calculate the loss
optimizer.zero_grad() # Gradient set 0
loss.backward() # Calculate the gradient
optimizer.step() # Optimization parameters
train_loss += loss.item() # Accumulated losses
total += y.size(0) # Cumulative total number of samples
correct += (output.argmax(dim=1) == y).sum().item() # The number of samples with correct cumulative prediction
train_acc = 100.0 * correct / total # Computational accuracy
if (i + 1) % num_print == 0:
print("step: [{}/{}], train_loss: {:.3f} | train_acc: {:6.3f}% | lr: {:.6f}" \
.format(i + 1, len(train_iter), train_loss / (i + 1), \
train_acc, get_cur_lr(optimizer)))
# Adjust the learning rate of gradient descent algorithm
if lr_scheduler is not None:
lr_scheduler.step()
# Output training time
print("--- cost time: {:.4f}s ---".format(time.time() - start))
if test_iter is not None: # Judge whether the test set is empty ( Notice here that test function )
record_test.append(test(net, test_iter, criterion, device)) # Every training one Epoch Model , Use the test set to test the accuracy of the model
record_train.append(train_acc)
# Return to each Epoch The accuracy of test set and training set
return record_train, record_test
# Validate the model
def test(net, test_iter, criterion, device):
total, correct = 0, 0
net.eval() # Test mode
with torch.no_grad(): # Don't calculate the gradient
print("*************** test ***************")
for X, y in test_iter:
X, y = X.to(device), y.to(device) # CPU or GPU function
output = net(X) # Calculate the output
loss = criterion(output, y) # Calculate the loss
total += y.size(0) # Calculate the number of test samples
correct += (output.argmax(dim=1) == y).sum().item() # Calculate the number of samples that the test set predicts accurately
test_acc = 100.0 * correct / total # Test set accuracy
# Loss of output test set
print("test_loss: {:.3f} | test_acc: {:6.3f}%" \
.format(loss.item(), test_acc))
print("************************************\n")
# Training mode ( Because here is because every time I pass by Epoch Just use the test set once , After using the test set , Go to the next Epoch Put the model back into training mode before )
net.train()
return test_acc
# Return to learning rate lr Function of
def get_cur_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
# Draw each Epoch The accuracy of test set and training set
def learning_curve(record_train, record_test=None):
plt.style.use("ggplot")
plt.plot(range(1, len(record_train) + 1), record_train, label = "train acc")
if record_test is not None:
plt.plot(range(1, len(record_test) + 1), record_test, label = "test acc")
plt.legend(loc=4)
plt.title("learning curve")
plt.xticks(range(0, len(record_train) + 1, 5))
plt.yticks(range(0, 101, 5))
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.show()
BATCH_SIZE = 128 # Batch size
NUM_EPOCHS = 12 # Epoch size
NUM_CLASSES = 10 # Number of categories
LEARNING_RATE = 0.01 # Gradient descent learning rate
MOMENTUM = 0.9 # Impulse size
WEIGHT_DECAY = 0.0005 # Weight attenuation coefficient
NUM_PRINT = 100
DEVICE = "cuda" if torch.cuda.is_available() else "cpu" # GPU or CPU function
def main():
net = SeResNet50()
net = net.to(DEVICE) # GPU or CPU function
train_iter, test_iter = load_dataset(BATCH_SIZE) # Import training set and test set
criterion = nn.CrossEntropyLoss() # Loss calculator
# Optimizer
optimizer = optim.SGD(
net.parameters(),
lr = LEARNING_RATE,
momentum = MOMENTUM,
weight_decay = WEIGHT_DECAY,
nesterov = True
)
# Adjust the learning rate (step_size: Every training step_size individual epoch, Update parameters once ; gamma: to update lr Multiplication factor of )
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size = 5, gamma = 0.1)
record_train, record_test = train(net, train_iter, criterion, optimizer, NUM_EPOCHS, DEVICE, NUM_PRINT,
lr_scheduler, test_iter)
learning_curve(record_train, record_test) # Draw the accuracy curve
main()

5-- Reference resources
SENet Reference resources
边栏推荐
- PAT甲级1152 Google Recruitment (20 分)
- I want to ask whether the variable configuration function can only be used in SQL mode
- Qtime definition (manual waste utilization is simple and beautiful)
- Games101 review: 3D transformation
- C # fine sorting knowledge points 10 generic (recommended Collection)
- MySQL optimization summary II
- Brain racking CPU context switching
- 2019浙江省赛C-错排问题,贪心
- CF685B-求有根树每颗子树的重心
- Games101 review: Transformation
猜你喜欢

JVM - classloader and parental delegation model

LeetCode - 707 设计链表 (设计)

Leetcode - 303 area and retrieval - array immutable (design prefix and array)

No tracked branch configured for branch xxx or the branch doesn‘t exist. To make your branch trac

使用cpolar建立一个商业网站(如何购买域名)

Pytorch学习笔记-Advanced_CNN(Using Inception_Module)实现Mnist数据集分类-(注释及结果)

解决vender-base.66c6fc1c0b393478adf7.js:6 TypeError: Cannot read property ‘validate‘ of undefined问题

matlab---错误使用 var 数据类型无效。第一个输入参数必须为单精度值或双精度值
LeetCode - 303 区域和检索 - 数组不可变 (设计 前缀和数组)

LeetCode - 225 用队列实现栈
随机推荐
LeetCode - 379 电话目录管理系统(设计)
Leetcode - 379 telephone directory management system (Design)
2019陕西省省赛K-变种Dijstra
Cf685b find the center of gravity of each subtree of a rooted tree
P4552 differential
2019 Shaanxi Provincial race K-variant Dijstra
Take you to learn more about JS basic grammar (recommended Collection)
JVM—类加载器和双亲委派模型
Understanding the difference between wait() and sleep()
死锁杂谈
JVM knowledge brain map sharing
LeetCode - 303 区域和检索 - 数组不可变 (设计 前缀和数组)
Pat grade a 1151 LCA in a binary tree (30 points)
Pytorch学习笔记--Pytorch常用函数总结1
2021江苏省赛A. Array-线段树,维护值域,欧拉降幂
Brain racking CPU context switching
MySQL optimization summary II
活动回顾|7月6日安远AI x 机器之心系列讲座第2期|麻省理工教授Max Tegmark分享「人类与AI的共生演化 」
Matlab randInt, matlab randInt function usage "recommended collection"
Graph theory and concept