当前位置:网站首页>【kaggle】Spaceship Titanic - 预测哪些乘客被运送到另一个维度【CatBoost - 10%】
【kaggle】Spaceship Titanic - 预测哪些乘客被运送到另一个维度【CatBoost - 10%】
2022-07-29 12:34:00 【白曦(Bessie)】
一、赛题
Spaceship Titanic - 预测哪些乘客被运送到另一个维度:https://www.kaggle.com/competitions/spaceship-titanic
结果:


二、代码(可以直接放到kaggle运行)
有看不懂的地方直接评论区私聊即可,看到就会回复
# K折
from sklearn.model_selection import KFold
# 基础包
import pandas as pd
import numpy as np
# 模型
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
import xgboost as xgb
import lightgbm as lgb
from catboost import CatBoostClassifier
# 评价指标
from sklearn.metrics import mean_squared_error
train = pd.read_csv('../input/spaceship-titanic/train.csv')
test = pd.read_csv('../input/spaceship-titanic/test.csv')
sample = pd.read_csv('../input/spaceship-titanic/sample_submission.csv')
# 用前一行的值填补空值
train.fillna(method='pad',axis=0,inplace=True)
test.fillna(method='pad',axis=0,inplace=True)
# 类型转换
train['Cabin'] = train['Cabin'].astype(str)
train['PassengerId'] = train['PassengerId'].astype(str)
cabin = train['Cabin']
PassengerId = train['PassengerId']
# 分割数据,插入数据集
from sqlalchemy import null
cabin_list = []
PassengerId_list = []
deck_list = []
num_list = []
side_list = []
Passenger_list = []
Id_list = []
# 分割数据,插入数据集
for i in cabin:
cabin_list.append(i.split('/'))
for i_1 in cabin_list:
# 处理cabin
deck = i_1[0]
num = int(i_1[1])
side = i_1[2]
deck_list.append(deck)
num_list.append(num)
side_list.append(side)
for j in PassengerId:
PassengerId_list.append(j.split('_'))
for j_1 in PassengerId_list:
Passenger = int(j[0])
Id = int(j[1])
Passenger_list.append(Passenger)
Id_list.append(Id)
train.insert(0,'deck',deck_list)
train.insert(1,'num',num_list)
train.insert(2,'side',side_list)
train.insert(3,'Passenger',Passenger_list)
train.insert(4,'Id',Id_list)
# 类型转换
test['Cabin'] = test['Cabin'].astype(str)
test['PassengerId'] = test['PassengerId'].astype(str)
cabin = test['Cabin']
PassengerId = test['PassengerId']
# 分割数据,插入数据集
from sqlalchemy import null
cabin_list = []
PassengerId_list = []
deck_list = []
num_list = []
side_list = []
Passenger_list = []
Id_list = []
# 分割数据,插入数据集
for i in cabin:
cabin_list.append(i.split('/'))
for i_1 in cabin_list:
# 处理cabin
deck = i_1[0]
num = int(i_1[1])
side = i_1[2]
deck_list.append(deck)
num_list.append(num)
side_list.append(side)
for j in PassengerId:
PassengerId_list.append(j.split('_'))
for j_1 in PassengerId_list:
Passenger = int(j[0])
Id = int(j[1])
Passenger_list.append(Passenger)
Id_list.append(Id)
test.insert(0,'deck',deck_list)
test.insert(1,'num',num_list)
test.insert(2,'side',side_list)
test.insert(3,'Passenger',Passenger_list)
test.insert(4,'Id',Id_list)
drop_columns = ['Name','HomePlanet','Destination','Cabin','PassengerId']
train.drop(drop_columns,axis=1,inplace=True)
test.drop(drop_columns,axis=1,inplace=True)
# 处理train字符串
for i in range(8693):
train['deck'][i] = ord(train['deck'][i])
train['side'][i] = ord(train['side'][i])
# 处理test字符串
for j in range(4277):
test['deck'][j] = ord(test['deck'][j])
test['side'][j] = ord(test['side'][j])
train['CryoSleep'] = train['CryoSleep'].astype('int')
train['VIP'] = train['VIP'].astype('int')
train['deck'] = train['deck'].astype('int')
train['side'] = train['side'].astype('int')
test['CryoSleep'] = test['CryoSleep'].astype('int')
test['VIP'] = test['VIP'].astype('int')
test['deck'] = test['deck'].astype('int')
test['side'] = test['side'].astype('int')
train['Transported'] = train['Transported'].astype('int')
c = ['deck','num','side','Passenger','Id', 'CryoSleep', 'Age','VIP','RoomService',
'FoodCourt','ShoppingMall','Spa','VRDeck']
target = train['Transported']
from sklearn.model_selection import train_test_split
#划分训练集、测试集
train_data, test_data, train_target, test_target = train_test_split(train[c],target, test_size = 0.3)
clf = CatBoostClassifier()
clf.fit(train_data,train_target)
test_pred = clf.predict(test_data)
score = mean_squared_error(test_target,test_pred)
print(score) # 0.80547
last_pred = clf.predict(zuhe_test)
last_pred = np.array (last_pred, dtype = bool)
#Kaggle需要提交最终的csv文件,所以输出一个csv文件:
sample['Transported']=last_pred
sample.to_csv('submission.csv', index=False)
边栏推荐
- 来自 Qt 官网的呐喊
- [based] GO language. Why do I have to learn Golang and introduction to the language universal
- MySQL如何对SQL做prepare预处理(解决IN查询SQL预处理仅能查询出一条记录的问题)
- TiFlash 源码阅读(五) DeltaTree 存储引擎设计及实现分析 - Part 2
- torch使用总结
- 38.【string下章】
- JUC阻塞队列-ArrayBlockingQueue
- [WeChat applet] WXSS and global, page configuration
- TiCDC Migration - TiDB to MySQL Test
- js进阶四(map、reduce、filter、sort、箭头函数、class继承、yield)
猜你喜欢

Go - reading (7), CopySheet Excelize API source code (the from and to the int)
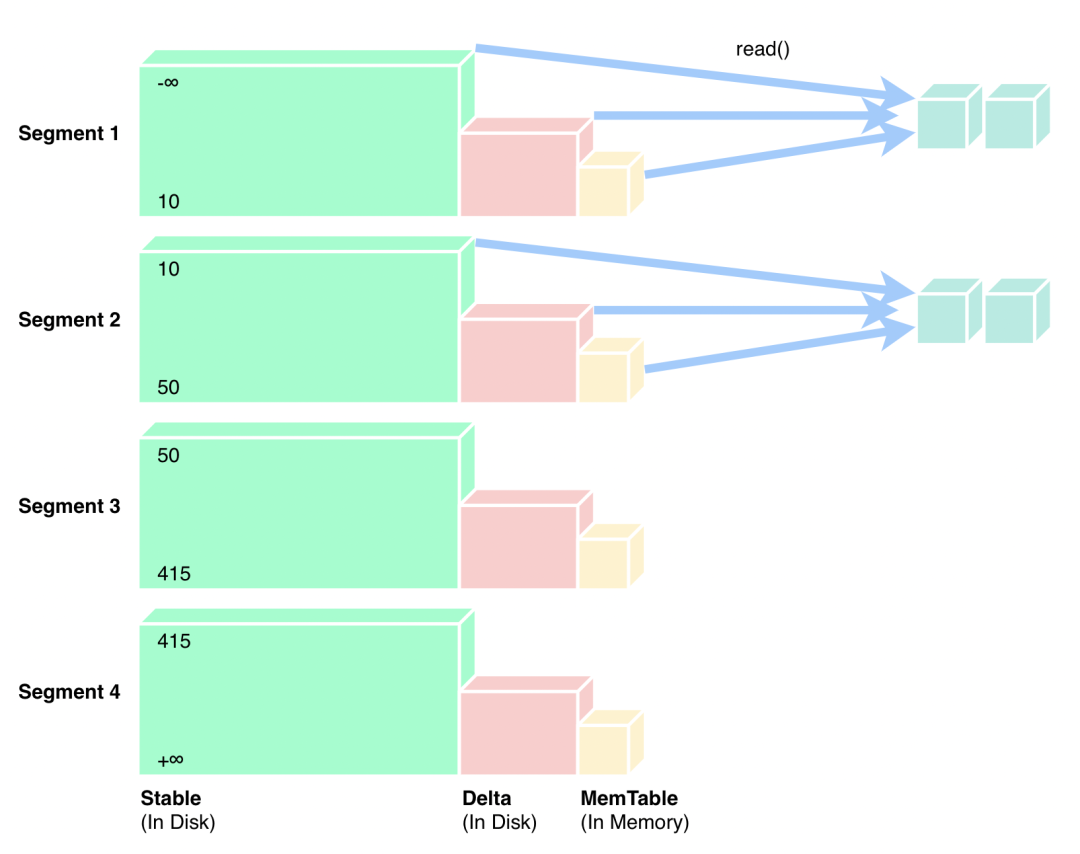
TiFlash 源码阅读(五) DeltaTree 存储引擎设计及实现分析 - Part 2

第十章 发现和记录 REST API
mysql数据库安装(详细)

Bika LIMS 开源LIMS集—— SENAITE的使用(用户、角色、部门)
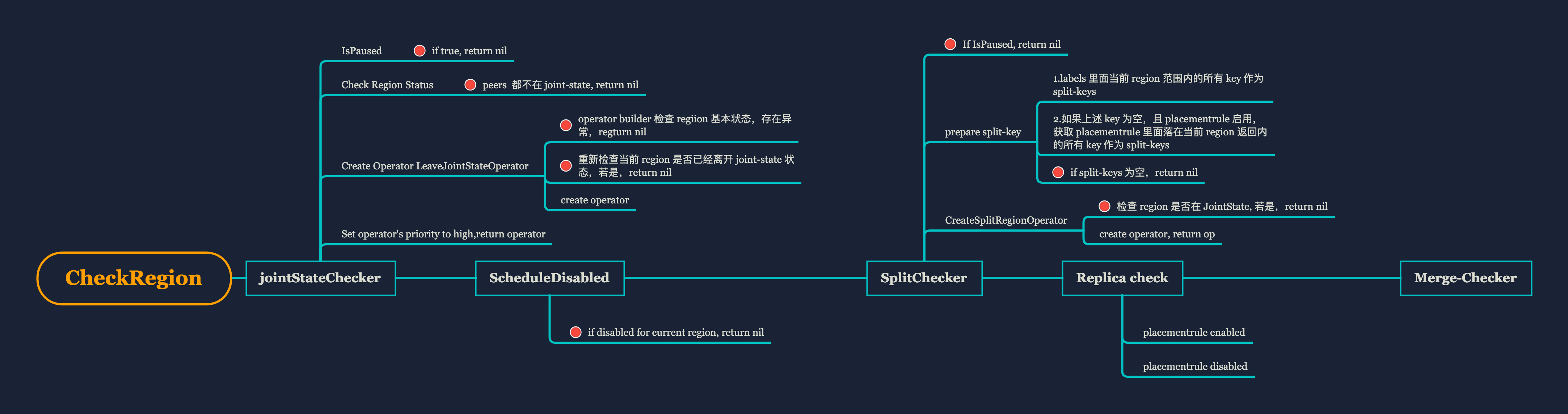
PD 源码分析- Checker: region 健康卫士

容器化 | 在 Rancher 中部署 MySQL 集群

微信H5网页分享只显示链接处理办法

IDEA 数据库插件Database Navigator 插件
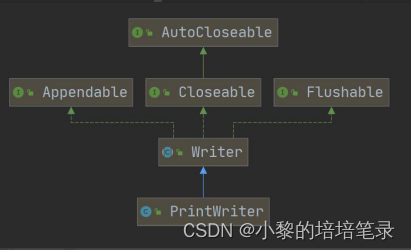
IO flow: node flow and process flow summarized in detail.
随机推荐
PHP 基础知识
2022 IDEA (学生邮箱认证)安装使用教程以及基础配置教程
The whole process of installing Oracle database on CentOS7
Sql file import database - nanny level tutorial
TiCDC Migration - TiDB to MySQL Test
【C语言】扫雷游戏实现(初阶)
TiDB升级与案例分享(TiDB v4.0.1 → v5.4.1)
【云原生】-Docker容器迁移Oracle到MySQL
2022年年中总结:行而不辍,未来可期
[GO语言基础] 一.为什么我要学习Golang以及GO语言入门普及
如何监控海外服务器性能
金仓数据库KingbaseES客户端编程接口指南-ODBC(6. KingbaseES ODBC 的扩展属性)
shell if else 使用
【云原生】微服务之Feign的介绍与使用
TiCDC synchronization delay problem
Chapter ten find and record the REST API
【微信小程序】一文解决button、input、image组件
Sql文件导入数据库-保姆级教程
[based] GO language. Why do I have to learn Golang and introduction to the language universal
Mysql各个大版本之间的区别