当前位置:网站首页>Sequence model (III) - sequence model and attention mechanism
Sequence model (III) - sequence model and attention mechanism
2022-07-23 10:32:00 【997and】
This study note mainly records various records during in-depth study , Including teacher Wu Enda's video learning 、 Flower Book . The author's ability is limited , If there are errors, etc , Please contact us for modification , Thank you very much !
Sequence model ( 3、 ... and )- Sequence model and attention mechanism
- One 、 Various sequences of sequence structure (Various sequence to sequence architectures)
- Two 、 Choose the most likely sentence (Picking the most likely sentence)
- 3、 ... and 、 beam search (Beam Search)
- Four 、 Improved cluster search (Refinements to Beam Search)
- 5、 ... and 、 Error analysis of cluster search (Error analysis in Beam Search)
- 6、 ... and 、( choose )Bleu score (Bleu Score)
- 7、 ... and 、 The attention model is intuitive (Attention Model Intuition)
- 8、 ... and 、 Attention model (Attention Model)
- Nine 、 speech recognition (Speech recognition)
- Ten 、 Trigger word detection (Trigger Word Detection)
The first edition 2022-07-22 first draft
One 、 Various sequences of sequence structure (Various sequence to sequence architectures)

French as shown in the picture is translated into English , First, establish a coding network ( Bottom left ), It's a RNN structure ,RNN The unit can be GRU It can also be LSTM, Enter only one French word into the network at a time , After receiving the input sequence , A vector will be output to represent the input sequence of the decoder on the right .
The decoder outputs one translated word at a time , Until the end .
Give a picture of the cat , It can automatically output the description of the drawing change . Below is AlexNet structure , Remove the last softmax layer , The pre training network can be an image coding network .
obtain 4096 Dimension vector , Input to RNN in , Description of the generated image ,
Two 、 Choose the most likely sentence (Picking the most likely sentence)

1. Build a language model :
It allows you to estimate the possibility of a sentence .
2. Machine translation :
Green is the coding network , And purple is the decoding network , The decoding network is almost the same as the language model just now , The language model is almost Zero vector Start , The decoding network takes the green output as the input , It is called conditional language model . The probability depends on the French sentence entered .
Will be told the corresponding probability of different English translations , It's not random sampling from the resulting distribution , Instead, find an English sentence y, Maximize the conditional probability . Usually the algorithm is Beam Search.
Why not search greedily ?
Greedy search , After generating the distribution of the first word , According to the conditional language model, the most likely first word will be selected to enter the machine translation model , Then choose the second word and so on .
however , What we really need to do is to choose the whole word sequence at one time , from y1 To yTy Maximize the overall probability .
As shown in the figure, the first translation is obviously better than the second , But after selection Jane is after , If you choose each time going The probability will be high .
3、 ... and 、 beam search (Beam Search)

Cluster search algorithm , First select the first word in the English translation to be output , Lists 10000 A vocabulary of words ( Ignore case ), Green is the coding network , Purple is the decoding part , To evaluate the probability value of a word .
1. Cluster search will consider multiple options , There will be a parameter B, It is called bunching width , This example is set to 3, So cluster search will consider 3 A possible outcome , Then store it in the computer memory .
2. Consider what the second word is for each first word , Here's the picture Step1 To Step2 The process of .
3. To evaluate the probability of the second word , As shown in the top right of the figure, the first network , Suppose the first estimate in, Pass it on to the next , stay in What is the second word in the case . What we are looking for is the maximum probability of the first and second word pairs . Under the network mechanism is probability .
4. As shown in the second network diagram , If the first word is jane, Same operation .
5. If found "in September",“jane is”,"jane visits" Three possibilities , Get rid of setember As the choice of the first word , Reduce to two possibilities .
6. Cluster search will pick out the three most likely choices for the first three words .
7. Add another word and continue , Until the end sign
Four 、 Improved cluster search (Refinements to Beam Search)

Length Normalization It is a way to slightly adjust the clustering algorithm .
The probability is less than 1, Multiply it to get a very small number , Can cause Numeric underflow . Take... In practice log, Strictly monotonically increasing functions . Maximize logP.
It can also be normalized , Divided by the number of words in the translation result . A softer approach , Is in Ty Add the index a. Sometimes called “ Normalized log likelihood objective function ”
B It's big , Better results , But the algorithm runs slowly , Big memory footprint ;
B Very small , The result is not so good , But the running block .
differ Breadth first search and Depth-first search , Cluster search is faster , But there is no guarantee of finding argmax The exact maximum of .
5、 ... and 、 Error analysis of cluster search (Error analysis in Beam Search)

One part is neural network structure , It's actually an encoder - Decoder structure ; The other part is the cluster search algorithm .
The above model calculation P(y*|x),RNN Calculation P(yhat|x), Compare the two sizes , In fact, it is less than or equal to .
1.P(y*|x) Big , signify , Cluster search selected yhat, and y* Bigger .
2.P(y*|x) Less than or equal to , May be RNN The model is wrong .
If length normalization is used , It's not about comparing the two possibilities , Instead, the optimized objective function value after length normalization is compared .
As shown in the figure , That is, the error analysis process .
6、 ... and 、( choose )Bleu score (Bleu Score)

Bleu(bilingual evaluation understudy Bilingual evaluation substitute ) Do is , Given a machine generated translation , It can automatically calculate a score to measure the quality of machine translation .
The abbreviation of machine translation is MT, Observe whether each word of the output appears in the reference , It is called the accuracy of machine translation .
Improved evaluation : Limit the integral of each word to the maximum number of times it appears in the reference sentence . In the sentence 1 in ,the Twice , Comparative sentence 2 many .
Use binary phrases , Define intercept count Count_clip, Calculate the sum as 4, Divided by the total number of binary phrases .
A single phrase : P 1 = Σ u n i g r a m s ∈ y ^ C o u n t c l i p ( u n i g r a m ) Σ u n i g r a m s ∈ y ^ C o u n t ( u n i g r a m ) P_1=\frac{\underset{unigrams∈\hat{y}}{\varSigma}Countclip\left( unigram \right)}{\underset{unigrams∈\hat{y}}{\varSigma}Count\left( unigram \right)} P1=unigrams∈y^ΣCount(unigram)unigrams∈y^ΣCountclip(unigram)
n Metaphrase : P n = Σ u g r a m s ∈ y ^ C o u n t c l i p ( u g r a m ) Σ u g r a m s ∈ y ^ C o u n t ( u g r a m ) P_n=\frac{\underset{ugrams∈\hat{y}}{\varSigma}Countclip\left( ugram \right)}{\underset{ugrams∈\hat{y}}{\varSigma}Count\left( ugram \right)} Pn=ugrams∈y^ΣCount(ugram)ugrams∈y^ΣCountclip(ugram)
BP For the penalty factor .
7、 ... and 、 The attention model is intuitive (Attention Model Intuition)


Use two-way RNN, no need A Indicates the perceptron ,S Express RNN The hidden state of . The attention model calculates the attention weight , use a<1,1> It indicates how much attention you should pay to the first piece of information when you generate the first word . There will be a context c.

Attention model reference .
8、 ... and 、 Attention model (Attention Model)

Purple on the right ,a<1,t>' It's attention weight ,a<t’> From above .a<t,t’> Namely y<t> belong t’ Time spent in a The amount of attention .
s<t-1> Is the hidden state of the previous time step ,a<t’> The feature of the last time step is another input .
The disadvantage of this algorithm is that it takes three times .
Date standardization :
Nine 、 speech recognition (Speech recognition)

seq2seq Application in speech recognition :
The common preprocessing steps of audio data are , Run this raw audio clip , Then generate a spectrogram .
Attention mechanism is used in speech recognition .
Connection temporary classification :
Suppose you voice a paragraph ,_ It's white space .
The basic rule yes , Fold the repeated characters between white space characters
Ten 、 Trigger word detection (Trigger Word Detection)

Trigger word system , Such as Apple Of Siri.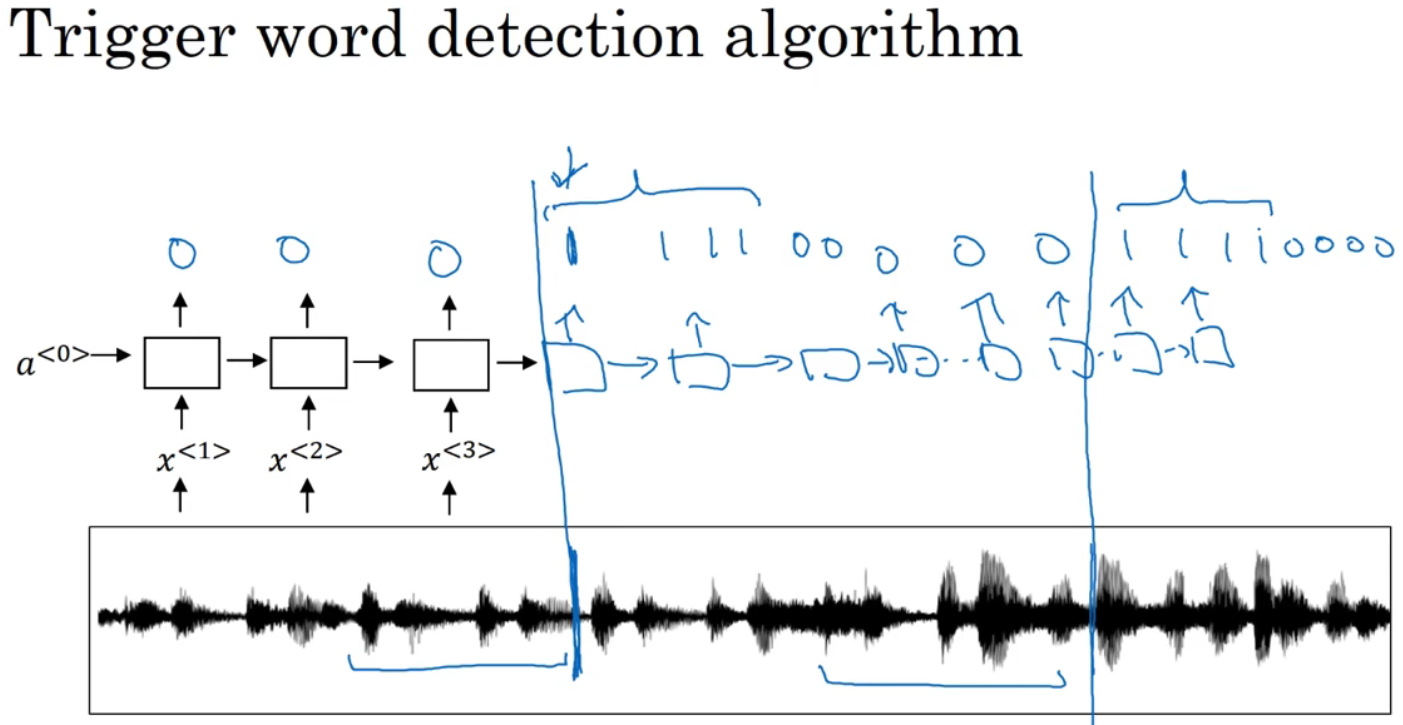
Pictured , What we need to do is , Calculate the spectrogram features of an audio segment to get the feature vector , Then distribute to RNN in , The last thing to do is , Define target tags y.
but 0 The quantity ratio of 1 Too many . There's another solution : In fact, the output can be changed back 0 Before , Multiple outputs 1.
边栏推荐
- Kingbasees SQL language reference manual of Jincang database (8. Function (9))
- Network communication principle and IP address allocation principle. The seven layers of the network are physical layer, data link layer, network layer, transmission layer, session layer, presentation
- Accessory mode
- Special training - linked list
- SeekTiger的Okaleido有大动作,生态通证STI会借此爆发?
- 网络数据泄露事件频发,个人隐私信息如何保护?
- How to query data differences between two isomorphic tables of massive data
- [MySQL] cursor
- Underlying mechanism of pointer
- "Lost wake up problem" in multithreading | why do wait() and notify() need to be used with the synchronized keyword?
猜你喜欢

浏览器怎么导入导出|删除书签,方法步骤来咯

Data middle office, Bi business interview (III): how to choose the right interviewees
Decompile the jar package / class file / modify the jar package using the decompile plug-in of idea

New file / filter / folder in VS
![[qt5.12] qt5.12 installation tutorial](/img/b2/c41a38ad6033da9adf64215f8f02a1.png)
[qt5.12] qt5.12 installation tutorial
![[C language foundation] 16 variable array (array length can be extended)](/img/01/24c6538d88bbecf7a1c21087ca239c.jpg)
[C language foundation] 16 variable array (array length can be extended)

MD5加密解密网站测试,MD5加密还安全吗?
![[MySQL] cursor](/img/60/19236cee3adafe27c431582ec053f8.png)
[MySQL] cursor
![[c #] IEnumerable enumerable type interface analysis yield](/img/08/8c346ce257b4adc0bea80bf05b6f52.png)
[c #] IEnumerable enumerable type interface analysis yield

redis 复制集群搭建
随机推荐
UE5 官方案例Lyra全特性详解 6.生成防御塔
performance介绍
浏览器怎么导入导出|删除书签,方法步骤来咯
[learning notes] agc022
UnityC#实现中文汉字转拼音-使用微软CHSPinYinConv库
SAP 批导模板(WBS批导为例)
AI性能拉满的“广和通AI智能模组SCA825-W”加速推进电商直播2.0时代
[c #] IEnumerable enumerable type interface analysis yield
redis伪集群一键部署脚本---亲测可用
Practice of online problem feedback module (11): realize image download function
Kingbasees SQL language reference manual of Jincang database (4. Pseudo column)
The world is being devoured by open source software
科技赋能新保险:中华财险的数字化转型
2022/7/20
How to improve browsing security? Teach you to set up a secure browser trust site
Kingbasees SQL language reference manual of Jincang database (8. Function (8))
赛尔运维:高校IT运维服务新样本
[MySQL] cursor
How does VirtualBox set up port forwarding?
EasyCVR平台CGO回放回调参数缺失导致设备录像无法播放,该如何解决?