当前位置:网站首页>How to solve the problem of large distribution gap between training set and test set
How to solve the problem of large distribution gap between training set and test set
2022-07-24 05:57:00 【Didi'cv】
StratifiedKFold
You can borrow sklearn Medium StratifiedKFold Come to realize K Crossover verification , At the same time, split the data according to the proportion of different categories in the label , So as to solve the problem of sample imbalance .
#!/usr/bin/python3
# -*- coding:utf-8 -*-
""" @author: xcd @file: StratifiedKFold-test.py @time: 2021/1/26 10:14 @desc: """
import numpy as np
from sklearn.model_selection import KFold, StratifiedKFold
X = np.array([
[1, 2, 3, 4],
[11, 12, 13, 14],
[21, 22, 23, 24],
[31, 32, 33, 34],
[41, 42, 43, 44],
[51, 52, 53, 54],
[61, 62, 63, 64],
[71, 72, 73, 74]
])
y = np.array([1, 1, 1, 1, 1, 1, 0, 0])
sfolder = StratifiedKFold(n_splits=4, random_state=0, shuffle=True)
folder = KFold(n_splits=4, random_state=0, shuffle=False)
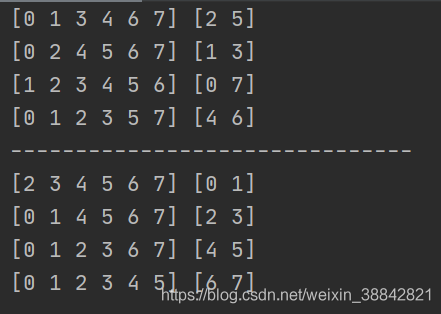
for train, test in sfolder.split(X, y):
print(train, test)
print("-------------------------------")
for train, test in folder.split(X, y):
print(train, test)
for fold, (train_idx, val_idx) in enumerate(sfolder.split(X, y)):
train_set, val_set = X[train_idx], X[val_idx]
Follow KFold There is a clear contrast ,StratifiedKFold Usage is similar. Kfold, But it is stratified sampling , Make sure the training set , The proportion of samples in the test set is the same as that in the original data set .
###
Parameters
n_splits : int, default=3
Number of folds. Must be at least 2.
shuffle : boolean, optional
Whether to shuffle each stratification of the data before splitting into batches.
random_state :
int, RandomState instance or None, optional, default=None
If int, random_state is the seed used by the random number generatorIf RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used
by `np.random`. Used when ``shuffle`` == True.
###
边栏推荐
猜你喜欢

Likeshop single merchant SaaS mall system opens unlimited

Chapter III summary of linear model
![[MYCAT] MYCAT sets up read-write separation](/img/7e/bc3488d3ca77104af101d45d723967.png)
[MYCAT] MYCAT sets up read-write separation

Delete the weight of the head part of the classification network pre training weight and modify the weight name

《机器学习》(周志华)第2章 模型选择与评估 笔记 学习心得

学习率优化策略

主成分分析计算步骤

《统计学习方法(第2版)》李航 第15章 奇异值分解 SVD 思维导图笔记 及 课后习题答案(步骤详细)SVD 矩阵奇异值 十五章

《统计学习方法(第2版)》李航 第十三章 无监督学习概论 思维导图笔记

STM32 DSP库MDK VC5\VC6编译错误: 256, (const float64_t *)twiddleCoefF64_256, armBitRevIndexTableF64_256,
随机推荐
【深度学习】手把手教你写“手写数字识别神经网络“,不使用任何框架,纯Numpy
Delete the weight of the head part of the classification network pre training weight and modify the weight name
Test whether the label and data set correspond after data enhancement
Multi merchant mall system function disassembly Lecture 14 - platform side member level
在网络中添加spp模块中的注意点
单播、组播、广播、工具开发、QT Udp通讯协议开发简介及开发工具源码
Jupyter notebook选择conda环境
vscode 多行注释总是会自动展开的问题
《机器学习》(周志华) 第3章 线性模型 学习心得 笔记
Machine learning (zhouzhihua) Chapter 1 Introduction notes learning experience
Positional argument after keyword argument
Machine learning (Zhou Zhihua) Chapter 3 Notes on learning linear models
STM32 DSP库MDK VC5\VC6编译错误: 256, (const float64_t *)twiddleCoefF64_256, armBitRevIndexTableF64_256,
绘制轮廓 cv2.findContours函数及参数解释
《统计学习方法(第2版)》李航 第22章 无监督学习方法总结 思维导图笔记
Numpy cheatsheet
js星星打分效果
Target detection tagged data enhancement code
Chapter III summary of linear model
Openwrt quick configuration Samba