当前位置:网站首页>理解整个网络模型的构建
理解整个网络模型的构建
2022-06-28 20:04:00 【seven_不是赛文】
# 准备数据集
# 数据集处理
# 进行数据集划分
# 利用DataLoader 加载数据集
eg:dataloder_train = DataLoader(train_data, batch_size=64, drop_last=False)
dataloder_test = DataLoader(test_data, batch_size=64, drop_last=False)
#搭建神经网络 可以单独放一个model.py文件(在model中测试我们模型的准确性。)
import torch
from torch import nn
# 搭建神经网络
# 注意model里面的Sequential引用了,外部就不要再import了,否则会报错:所以==》from model import *
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x
# 检查准确性
if __name__ == '__main__':
test = Test()
input = torch.ones((64, 3, 32, 32))
output = test(input)
print(output.shape)
# 创建网络模型
test = Test()
# 损失函数
loss_fc = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(test.parameters(), lr=learning_rate)
## 添加 tensorboard。把loss的变化图像表示出来
writer = SummaryWriter("logs")
# 一些参数的理解
step 训练的次数
epoch 训练的轮数
'-------------训练模型并测试模型训练好没有----------------------'
# 开始训练:
for i in range(epoch):
print("----------第{}轮训练开始:-------------".format(i+1))
# 训练步骤开始
for data in dataloder_train:
imgs, targets = data
output_train = test(imgs)
loss = loss_fc(output_train, targets) # 获得损失值 loss
# 使用优化器优化模型
optimizer.zero_grad() # 梯度清零
loss.backward() # 调用损失 loss,得到每一个参数的梯度
optimizer.step() #调用优化器 optimizer 对我们的参数进行优化
total_train_step = total_train_step + 1 #记录训练次数
if total_train_step % 100 == 0: #这样可以减少显示量
# loss.item()与loss时有区别的,loss.item()返回的是数字
print("训练次数:{}, 损失值:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step) # 逢100的整数记录
# 模型在训练的时候,为了知道模型是否训练好,我们在每一轮训练完之后都进行一个测试,用测试数据集的损失值来评估模型有没有训练好,测试的时候不需要优化器进行调优
# 测试步骤开始
# 损失值
total_test_loss = 0
# 正确值
total_accuracy = 0
with torch.no_grad(): # 表示在 with 里的代码,它的梯度就没有了,保证不会进行调优
for data in dataloder_test:
imgs, targets = data
output_test = test(imgs)v
# 这个loss它只是data的一部分数据,在网络模型中的损失
loss = loss_fc(output_test, targets)
# 我们要求整个数据集上的loss.所以下面有个total loss
total_test_loss = total_test_loss + loss
accuracy = (output_test.argmax(1) == targets).sum() # 计算预测与实际 一致的个数 ##(1)是指对每一行搜索最大
total_accuracy = total_accuracy + accuracy # 总的正确的个数
print("整体测试集的损失值:{}".format(total_test_loss.item()))
print("整体测试的正确率为:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 保存每一轮训练的模型
torch.save(test, "test_{}.pth".format(i)) #方法以保存
# 下面是方法二保存模型,将参数保存成字典型
# torch.save(test.state_dict(), "test_{}".format(i))
print("模型已保存")
#这里说明每一轮训练都保存了一次模型,我们之后可以把每次保存的模型拿去训练看看结果,其实是不一样的
writer.close()
# 画loss或者accuracy的图像变化:
可以用writer = SummaryWriter("logs")或者plt.figure的方法
'第一种:直接就是我们模型训练出来的数值'
writer = SummaryWriter("logs")
...
writer.add_scalar("train_loss", loss.item(), total_train_step)
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
'第二种,还要转换一下'
变成list?还是numpy那个啥
边栏推荐
- 2022茶艺师(中级)考试模拟100题及模拟考试
- 裁员真能拯救中国互联网?
- How to analyze the relationship between enterprise digital transformation and data asset management?
- Ali open source (easyexcel)
- Markdown mermaid种草(1)_ mermaid简介
- C # application interface development foundation - form control
- 2280.Cupboards
- rsync远程同步
- Comparisonchain file name sort
- April 10, 2022 -- take the first step with C -- use C from Net class library call method (not understood)
猜你喜欢
Markdown mermaid种草(1)_ mermaid简介

Lecture 30 linear algebra Lecture 4 linear equations
Markdown Mermaid planting grass (1)_ Introduction to Mermaid
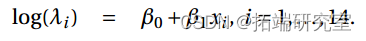
R language GLM generalized linear model: logistic regression, Poisson regression fitting mouse clinical trial data (dose and response) examples and self-test questions

28 rounds of interviews with 10 companies in two and a half years

C # connect to the database to complete the operation of adding, deleting, modifying and querying
Shell reads the value of the JSON file

ArrayList of collection
![[go language questions] go from 0 to entry 5: comprehensive review of map, conditional sentences and circular sentences](/img/7a/16b481753d7d57f50dc8787eec8a1a.png)
[go language questions] go from 0 to entry 5: comprehensive review of map, conditional sentences and circular sentences

Leetcode week 299
随机推荐
odoo15 Module operations are not possible at this time, please try again later or contact your syste
压缩与解压缩命令
Markdown mermaid種草(1)_ mermaid簡介
oracle delete误删除表数据后如何恢复
Analysis of all knowledge points of TCP protocol in network planning
Day88.七牛云: 房源图片、用户头像上传
Kaggle gastrointestinal image segmentation competition baseline
《数据安全法》出台一周年,看哪四大变化来袭?
Are you still paying for your thesis? Come and join me
2837. The total number of teams
easypoi
2022 welder (elementary) special operation certificate examination question bank and answers
1002_ twenty million one hundred and eighty-one thousand and nineteen
How to understand the usability of cloud native databases?
JSP to get the value in the session
2022 t elevator repair test question bank simulation test platform operation
电子科大(申恒涛团队)&京东AI(梅涛团队)提出用于视频问答的结构化双流注意网络,性能SOTA!优于基于双视频表示的方法!...
csdn涨薪技术-Selenium自动化测试全栈总结
Kaggle腸胃道圖像分割比賽baseline
2022 tea master (intermediate) examination simulated 100 questions and simulated examination