当前位置:网站首页>[Kevin's third play in a row] is rust really slower than C? Further analyze queen micro assessment
[Kevin's third play in a row] is rust really slower than C? Further analyze queen micro assessment
2022-06-27 07:19:00 【51CTO】
author :Kevin Wang
yesterday , In this article, I analyzed the unreliability of micro assessment , Left a little technical details that were not analyzed clearly . Comment area @ Wangmingzhe suggested that I could use VTune Tools , I'll continue to analyze it today .
Previous review
In yesterday's Micro assessment , I passed through queen.rs Add... At the beginning of the program NOP Instructions and queen.c Call the test function and perf analysis , It is proved that the difference is caused by the code tested in the compilation results layout( Address location of relevant code in memory ) Resulting noise .
Today, use the tools to further analyze layout What has been affected .
Or from Canada NOP Start
Write a script , Automatic separate test at queen.rs Add 1 individual 、2 individual ...N individual NOP, See if there is any regularity in the impact on the test results .
So I got the following results :

Draw it as a graph :
 queen.rs Test time and added NOP The number of relations
queen.rs Test time and added NOP The number of relations
Same method , We are queen.c Of main Add... At the beginning of the function NOP To get C Language version of the curve .
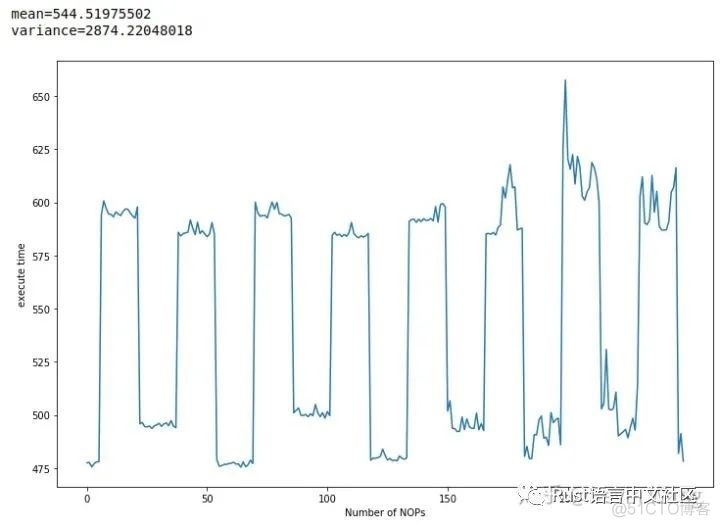 queen.c Test time and added NOP The number of relations
queen.c Test time and added NOP The number of relations
You can see Rust The average value of the edition 533 And variance 177 comparison C The version should be better !( Of course, this can not be used as a standard to judge language performance ,CPU The optimization of the microarchitecture layer is too complicated and subtle , Special cases cannot be used to illustrate the problem )
C and Rust The execution time of both versions is about inserting NOP Count 16 It is a half cycle and changes periodically , So this cycle 16 What the hell is it ? Looking at the assembly code, I found that the compiler will automatically align the loop body to 16byte:
 Add 9 individual nop A compilation of ,Block 2 Is the beginning of the first loop body
Add 9 individual nop A compilation of ,Block 2 Is the beginning of the first loop body  Add 10 individual NOP A compilation of ,Block 2 Is the alignment inserted by the compiler NOP, The original Block 2 Moved back 16byte become Block 3
Add 10 individual NOP A compilation of ,Block 2 Is the alignment inserted by the compiler NOP, The original Block 2 Moved back 16byte become Block 3
Get a clue : In this case , Align the beginning of the first loop body to an odd number 16byte You will get better performance .
use VTune To run the
Yesterday we analyzed and cache line Alignment independent .Intel Provides a tool VTune Used for analysis app Performance of , Than perf More accurate and detailed . Then we VTune Tools to run to see . take rust Compare the speed of the two versions of , They came out separately and got two Summary The report :
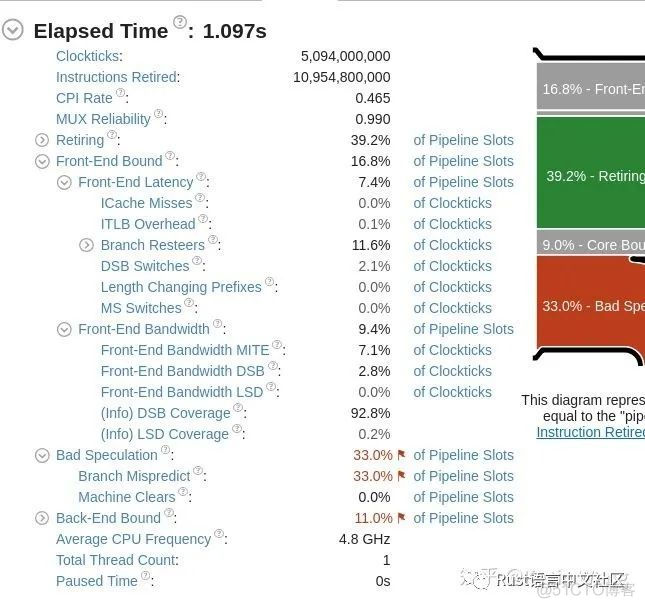 Faster reports
Faster reports  Reports of slower runs
Reports of slower runs
Comparing the two reports, we can see , Both have high branch prediction failure rates ( There is still room for optimization ), But the difference is caused by the three items circled in red . There are two things involved : DSB and MITE.
I have a general understanding of these two things :
- intel modern CPU Will convert the program's machine instructions into finer grained microinstructions (uops), The main purpose is to realize the out of order execution of instructions ,MITE Is the engine that performs this transformation , Like a compiler .
- because MITE It takes time and effort , A little bit new CPU And the introduction of DSB To cache the conversion results , Similar to compile cache , But the cache capacity may be very small .
Then let's combine the tools to understand , Some comments are given in the tool :
DSB Switches
Metric Description
Intel microarchitecture code name Sandy Bridge introduces a new decoded ICache. This cache, called the DSB (Decoded Stream Buffer), stores uOps that have already been decoded, avoiding many of the penalties of the legacy decode pipeline, called the MITE (Micro-instruction Translation Engine). However, when control flows out of the region cached in the DSB, the front-end incurs a penalty as uOp issue switches from the DSB to the MITE. This metric measures this penalty.
Possible Issues
A significant portion of cycles is spent switching from the DSB to the MITE. This may happen if a hot code region is too large to fit into the DSB.
Tips
Consider changing code layout (for example, via profile-guided optimization) to help your hot regions fit into the DSB.
Front-End Bandwidth
Metric Description
This metric represents a fraction of slots during which CPU was stalled due to front-end bandwidth issues, such as inefficiencies in the instruction decoders or code restrictions for caching in the DSB (decoded uOps cache). In such cases, the front-end typically delivers a non-optimal amount of uOps to the back-end.
front summay I can roughly understand the meaning of the three differences in :
DSB Switches: The slow one comes from DSB The hit rate of fetch instruction is low , More are switched to MITE Now we have compiled .
Front-End Bandwidth MITE: The slow spend on MITE There is more time on ,MITE Busy .
Front-End Bandwidth DSB: The slow ones spend from DSB It takes more time to fetch instructions ( This should echo the first one ?).
In summary, it is When it's slow DSB The hit rate is low , More time is spent on MITE On .
Why is there a difference in hit rate ? because DSB The cache is a block of code , therefore , It depends on whether our hot blocks are aligned to DSB The frame of .
Summary
So the conclusion is still : This micro evaluation result is wrong , Differences are related to instruction alignment , Belong to noise , Someone compiled C fast , Someone compiled Rust fast , It's all luck to see where the compiler aligns the instructions , Can not reflect the differences between languages .
The above analysis is based on i7 9700K Conduct , Other CPU It may be different , There may be a similar mechanism . About DSB, I can't find any more details , I don't know my CPU DSB How big is the , If there is any mistake, please tap .
边栏推荐
- 高薪程序员&面试题精讲系列116之Redis缓存如何实现?怎么发现热key?缓存时可能存在哪些问题?
- One person manages 1000 servers? This automatic operation and maintenance tool must be mastered
- pytorch Default process group is not initialized
- R 中的 RNA-Seq 数据分析 - 调查数据中的差异表达基因!
- JDBC参数化查询示例
- Easyexcel: read Excel data into the list set
- 请问如何在网页通过excel文件的形式向后段数据库添加数据
- 专业四第二周自测
- R 语言并行计算 spearman 相关系数,加快共现网络(co- occurrence network)构建速度
- Talk about Domain Driven Design
猜你喜欢

Centos7.9安装mysql 5.7,并设置开机启动

Fractional Order PID control

进程终止(你真的学会递归了吗?考验你的递归基础)

Vs how to configure opencv? 2022vs configuration opencv details (multiple pictures)

正斜杠反斜杠的由来
How to write controller layer code gracefully?
Solve the problem of win10 wsl2 IP change

Unsafe中的park和unpark

OPPO面试整理,真正的八股文,狂虐面试官

一线大厂面试官问:你真的懂电商订单开发吗?
随机推荐
Thesis reading skills
OpenCV怎么下载?OpenCV下载后怎么配置?
2022 cisp-pte (I) document contains
Self test in the second week of major 4
MPC control of aircraft wingtip acceleration and control surface
仙人掌之歌——投石问路(1)
hutool对称加密
云服务器配置ftp、企业官网、数据库等方法
Redis cache penetration, cache breakdown, cache avalanche
Goodbye, agile Scrum
OPPO面试整理,真正的八股文,狂虐面试官
【毕业季】毕业是人生旅途的新开始,你准备好了吗
【Kevin三连弹之三】Rust真的比C慢吗?进一步分析queen微测评
Park and unpark in unsafe
Winow10 installation nexus nexus-3.20.1-01
Machine learning
yarn create vite 报错 ‘D:\Program‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件
Tar: /usr/local: cannot find tar in the Archive: due to the previous error, it will exit in the last error state
R 语言并行计算 spearman 相关系数,加快共现网络(co- occurrence network)构建速度
Classical cryptosystem -- substitution and replacement