当前位置:网站首页>技术干货|昇思MindSpore可变序列长度的动态Transformer已发布!
技术干货|昇思MindSpore可变序列长度的动态Transformer已发布!
2022-07-03 07:26:00 【昇思MindSpore】

从事AI算法研究的朋友们都知道,以Transformer为代表的基于自注意力机制的神经网络已经在大规模文本建模、文本情感理解、机器翻译等领域取得了显著的性能提升和广泛的实际应用。近年来,Transformer系列模型以有效增强CNN所欠缺的长距离依赖关系建模的能力,在视觉领域同样大获成功,应用特别广泛。实际应用中,随着数据集大小的增加,由于Transformer通常将所有输入样本表征为固定数目的tokens,开销也急剧增加。研究团队发现采用定长的token序列表征数据集中所有的图像是一种低效且次优的做法!
为此,清华大学黄高老师研究团队和华为中央媒体技术院联合研究的关于动态Transformer的最新工作Not All Images are Worth 16x16 Words: Dynamic Transformers for Efficient Image Recognition (https://arxiv.org/pdf/2105.15075.pdf,已被NeurIPS 2021接收),可针对每个样本自适应地使用最合适的token数目进行表征,并在Github上发布MindSpore实现的训练推理代码:
https://github.com/blackfeather-wang/Dynamic-Vision-Transformer-MindSpore,可使模型训练精度持平,平均推理加速1.6-3.6倍!动态Transformer模型未来会同步上线至MindSpore ModelZoo
(https://gitee.com/mindspore/models/tree/master)中,可直接获取使用。

图1 Dynamic Vision Transformer(DVT)示例
● 背景技术 ●
近年来,Google的工作Vision Transformer(ViT)系列视觉模型受到了广泛关注,这些模型通常将图像数据划分为固定数目的patch,并将每个patch对应的像素值采用线性映射等方式嵌入为一维的token,作为Transformer模型的输入,示意图如图2所示。

图2 Vision Transformer(ViT)对输入的表征方式
假设模型结构固定,即每个token的维度大小固定,将输入表征为更多的token可以实现对图片更为细粒度的建模,往往可以有效提升模型的测试准确率;然而与此相对,由于Transformer的计算开销随token数目成二次方增长,增多token将导致大量增长的计算开销。为了在精度和效率之间取得一个合适的平衡,现有的ViT模型一般将token数设置为14x14或16x16。
论文提出,一个更合适的方法应当是,根据每个输入的具体特征,对每张图片设置对其最合适的token数目。以图3为例,左侧的苹果图片构图简单且物体尺寸较大,右侧图片则包含复杂的人群、建筑、草坪等内容且物体尺寸均较小。显然,前者只需要少量token就可以有效表征其内容,后者则需要更多的token描述不同构图要素之间的复杂关系。

图3 根据具体输入确定token数目
这一问题对于网络的推理效率是非常关键的。从表1中可以看到,若将token数目设置为4x4,准确率仅仅下降了15.9%(76.7% v.s. 60.8%),但计算开销下降了8.5倍(1.78G v.s. 0.21G)。这一结果表明,正确识别占数据大多数的较“简单”的样本只需4x4或更少的token,相当多的计算浪费在了使用存在大量冗余的14x14 token表征他们!
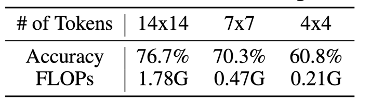
表1 T2T-ViT-12使用更少token时的测试精度和计算开销
● 算法原理 ●
动态ViT推理训练过程
受到上述现象的启发,论文提出了一个动态视觉Transformer框架(Dynamic Vision Transformer,DVT),意在针对每个样本选择一个合适数目的token来进行表征。
首先介绍DVT的推理过程,如图4所示,对于任意测试样本,首先将其粗略表征为最小数目的token,判断预测结果是否可信,若可信,则直接输出当前结果并终止推理;若不可信,则依次激活下一个Transformer将输入图片表征为更多的token,进行更细粒度、但计算开销更大的推理,得到结果之后再次判断是否可信,以此类推。值得注意的是,处于下游的Transformer可以复用上游模型已产生的深度特征(特征复用机制)和注意力图(关系复用机制),以尽可能避免进行冗余和重复的计算。

图4 Dynamic Vision Transformer(DVT)
训练网络在所有出口都取得正确的预测结果,训练目标如下式所示。其中

和分别代表数据和标签,代表第个出口的softmax预测概率,代表交叉熵损失。

特征复用机制
当一个处于下游位置的Transformer被激活时,应当训练其在先前Transformer的特征的基础上进行进一步提升,而非完全从0开始重新提取特征。基于此,论文提出特征复用机制使训练更为高效,如下图5所示。将上游Transformer最后一层输出的特征取出,经多层感知器变换和上采样后,作为上下文嵌入整合入下游模型每一层的多层感知器模块中。

图5 特征复用(Feature Reuse)机制
关系复用机制
除特征复用机制外,位于下游的模型同样可以借助上游Transformer已经得到的注意力图来进行更准确的全局注意力关系建模,基于此,提出关系复用机制,示意图如下图6所示。将上游模型的全部注意力图以logits的形式进行整合,经MLP变换和上采样后,加入到下层每个注意力图的logits中。这样,下游模型每一层的attention模块都可灵活复用上游模型不同深度的全部attention信息,且这一复用信息的“强度”可以通过改变MLP的参数自动地调整。

图6 关系复用(Relationship Reuse)机制
MindSpore实验效果
MindSpore上仅需两行代码调用通用动态ViT(DVT)框架,如图7所示,输入两类token的ViT网络,并设置是否开启特征复用和关系复用,完成训练后,如图8所示,即可在ImageNet上获得1.6-3.6倍的推理加速!

图7 MindSpore DVT调用方法

图8 MindSpore+DVT(DeiT)在ImageNet上的计算效率
图9给出了简单和困难的可视化样本结果。

图9 可视化结果
● 总结 ●
下面总结该研究的价值:
(1)针对视觉Transformer提出了一个自然、通用、有效的自适应推理框架,理论和实际效果都比较显著。
(2)提出了一个颇具启发性的思路,对全部图片以固定方式划分patch的表征方式,是不够灵活和次优的,一个更合理的策略是,应当根据输入数据动态调整表征方式。这或为开发高效、可解释性强、迁移性好的通用视觉Transformer提供了新方向。
(3)这种按输入数据动态调整表征方式的动态性推理也为应用至动态性训练提供了一种很好的方向。
最后感谢清华大学黄高老师研究团队博士生王雨霖和中央媒体技术院专家的供稿,作者的主页链接:www.rainforest-wang.cool。
参考资料:
[1] Wang Y, Huang R, Song S, et al. Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length[J]. arXiv preprint arXiv:2105.15075, 2021.
[2] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[3] https://www.mindspore.cn/
[4] https://github.com/blackfeather-wang/Dynamic-Vision-Transformer-MindSpore

MindSpore官方资料
GitHub : https://github.com/mindspore-ai/mindspore
Gitee : https : //gitee.com/mindspore/mindspore
官方QQ群 : 871543426
边栏推荐
- The underlying mechanism of advertising on websites
- Margin left: -100% understanding in the Grail layout
- 【开发笔记】基于机智云4G转接板GC211的设备上云APP控制
- Summary of Arduino serial functions related to print read
- FileInputStream and fileoutputstream
- High concurrency memory pool
- pgAdmin 4 v6.11 发布,PostgreSQL 开源图形化管理工具
- Hash table, generic
- Jeecg menu path display problem
- 在 4EVERLAND 上存储 WordPress 媒体内容,完成去中心化存储
猜你喜欢

Store WordPress media content on 4everland to complete decentralized storage

Custom generic structure

TreeMap

Hnsw introduction and some reference articles in lucene9

Leetcode 213: looting II
7.2刷题两个

Leetcode 198: 打家劫舍

File operation serialization recursive copy

Analysis of the problems of the 10th Blue Bridge Cup single chip microcomputer provincial competition

《指環王:力量之戒》新劇照 力量之戒鑄造者亮相
随机推荐
docket
Es writing fragment process
Responsive MySQL of vertx
PgSQL converts string to double type (to_number())
The difference between typescript let and VaR
LeetCode
Some experiences of Arduino soft serial port communication
The underlying mechanism of advertising on websites
Analysis of the problems of the 10th Blue Bridge Cup single chip microcomputer provincial competition
HCIA notes
1. E-commerce tool cefsharp autojs MySQL Alibaba cloud react C RPA automated script, open source log
为什么说数据服务化是下一代数据中台的方向?
Leetcode 198: 打家劫舍
Why is data service the direction of the next generation data center?
Dora (discover offer request recognition) process of obtaining IP address
Lombok cooperates with @slf4j and logback to realize logging
2. E-commerce tool cefsharp autojs MySQL Alibaba cloud react C RPA automated script, open source log
What did the DFS phase do
[coppeliasim4.3] C calls UR5 in the remoteapi control scenario
twenty million two hundred and twenty thousand three hundred and nineteen