当前位置:网站首页>druid. io index_ Realtime real-time query
druid. io index_ Realtime real-time query
2022-07-29 02:00:00 【master-dragon】
Preface
Previous articles introduced the real-time task process and some stage details , It hasn't been said how to ensure real-time query . The first thing you can blurt out is :
- Real time tasks are responsible for persistence , Also respond to queries
- Real time tasks need both jvm Heap memory , Also use off heap memory
So this article will discuss how real-time tasks are done , Or to put it another way : How do you design a real-time data import and query thing ?
Let's have an overview
There is one druid.io Basics , Then experience the general process , Follow up on the source code 
The source code walkthrough
go back to druid.io Source code ,peon Process RealPlumber,io.druid.segment.realtime.plumber.RealtimePlumber#add Received every data , Source code is as follows
@Override
public int add(InputRow row, Supplier<Committer> committerSupplier) throws IndexSizeExceededException
{
log.info("add row:" + row.toString());
long messageTimestamp = row.getTimestampFromEpoch();
final Sink sink = getSink(messageTimestamp);
metrics.reportMessageMaxTimestamp(messageTimestamp);
if (sink == null) {
return -1;
}
final int numRows = sink.add(row, false);
// Persistence
if (!sink.canAppendRow() || System.currentTimeMillis() > nextFlush) {
persist(committerSupplier.get());
}
return numRows;
}
Here's the picture log, I added some of my own in the actual operation log
among Sink Object is more important ,io.druid.segment.realtime.plumber.RealtimePlumber#getSink as follows
private Sink getSink(long timestamp)
{
if (!rejectionPolicy.accept(timestamp)) {
return null;
}
final Granularity segmentGranularity = schema.getGranularitySpec().getSegmentGranularity();
final VersioningPolicy versioningPolicy = config.getVersioningPolicy();
DateTime truncatedDateTime = segmentGranularity.bucketStart(DateTimes.utc(timestamp));
final long truncatedTime = truncatedDateTime.getMillis();
Sink retVal = sinks.get(truncatedTime);
if (retVal == null) {
final Interval sinkInterval = new Interval(
truncatedDateTime,
segmentGranularity.increment(truncatedDateTime)
);
log.info("RealtimePlumber.getSink inteval:" + sinkInterval.toString());
retVal = new Sink(
sinkInterval,
schema,
config.getShardSpec(),
versioningPolicy.getVersion(sinkInterval),
config.getMaxRowsInMemory(),
config.isReportParseExceptions()
);
addSink(retVal);
}
return retVal;
}
- From a
Map<Long, Sink> sinksIn order to get , If not, construct and add map in , Not next time new Sink 了 - commonly tranquility It's an hourly task , therefore sinks Generally, there is only one key value pair
- For every data
sink.add(row, false);, And it is necessary to judge whether to perform persistence operation - meanwhile
io.druid.segment.realtime.plumber.RealtimePlumber#addSinkTemporary segment To zookeeper in
You can see that in fact Sink This class seems to be the core , Data processing and query are closely related to this class
Shun this persist Methods look down , Source code is as follows ( Comments are added to the code )
io.druid.segment.realtime.plumber.RealtimePlumber#persist
@Override
public void persist(final Committer committer)
{
final List<Pair<FireHydrant, Interval>> indexesToPersist = Lists.newArrayList();
for (Sink sink : sinks.values()) {
if (sink.swappable()) {
// currHydrant Add to indexesToPersist, And create a new FireHydrant Set to currHydrant
indexesToPersist.add(Pair.of(sink.swap(), sink.getInterval()));
}
}
log.info("Submitting persist runnable for dataSource[%s]", schema.getDataSource());
final Stopwatch runExecStopwatch = Stopwatch.createStarted();
final Stopwatch persistStopwatch = Stopwatch.createStarted();
final Map<String, Object> metadataElems = committer.getMetadata() == null ? null :
ImmutableMap.of(
COMMIT_METADATA_KEY,
committer.getMetadata(),
COMMIT_METADATA_TIMESTAMP_KEY,
System.currentTimeMillis()
);
persistExecutor.execute(
new ThreadRenamingRunnable(StringUtils.format("%s-incremental-persist", schema.getDataSource()))
{
@Override
public void doRun()
{
/* Note: If plumber crashes after storing a subset of all the hydrants then we will lose data and next time we will start with the commitMetadata stored in those hydrants. option#1: maybe it makes sense to store the metadata outside the segments in a separate file. This is because the commit metadata isn't really associated with an individual segment-- it's associated with a set of segments that are persisted at the same time or maybe whole datasource. So storing it in the segments is asking for problems. Sort of like this: { "metadata" : {"foo": "bar"}, "segments": [ {"id": "datasource_2000_2001_2000_1", "hydrant": 10}, {"id": "datasource_2001_2002_2001_1", "hydrant": 12}, ] } When a realtime node crashes and starts back up, it would delete any hydrants numbered higher than the ones in the commit file. option#2 We could also just include the set of segments for the same chunk of metadata in more metadata on each of the segments. we might also have to think about the hand-off in terms of the full set of segments being handed off instead of individual segments being handed off (that is, if one of the set succeeds in handing off and the others fail, the real-time would believe that it needs to re-ingest the data). */
long persistThreadCpuTime = VMUtils.safeGetThreadCpuTime();
try {
// Traverse indexesToPersist And perform persistence operation , Return the number of persistent rows as an indicator to collect
for (Pair<FireHydrant, Interval> pair : indexesToPersist) {
metrics.incrementRowOutputCount(
persistHydrant(
pair.lhs, schema, pair.rhs, metadataElems
)
);
}
committer.run();
}
catch (Exception e) {
metrics.incrementFailedPersists();
throw e;
}
finally {
metrics.incrementPersistCpuTime(VMUtils.safeGetThreadCpuTime() - persistThreadCpuTime);
metrics.incrementNumPersists();
metrics.incrementPersistTimeMillis(persistStopwatch.elapsed(TimeUnit.MILLISECONDS));
persistStopwatch.stop();
}
}
}
);
final long startDelay = runExecStopwatch.elapsed(TimeUnit.MILLISECONDS);
metrics.incrementPersistBackPressureMillis(startDelay);
if (startDelay > WARN_DELAY) {
log.warn("Ingestion was throttled for [%,d] millis because persists were pending.", startDelay);
}
runExecStopwatch.stop();
// To reset nextFlush
resetNextFlush();
}
io.druid.segment.realtime.plumber.RealtimePlumber#persistHydrant
/** * Persists the given hydrant and returns the number of rows persisted * * @param indexToPersist hydrant to persist * @param schema datasource schema * @param interval interval to persist * * @return the number of rows persisted */
protected int persistHydrant(
FireHydrant indexToPersist,
DataSchema schema,
Interval interval,
Map<String, Object> metadataElems
)
{
synchronized (indexToPersist) {
if (indexToPersist.hasSwapped()) {
log.info(
"DataSource[%s], Interval[%s], Hydrant[%s] already swapped. Ignoring request to persist.",
schema.getDataSource(), interval, indexToPersist
);
return 0;
}
log.info(
"DataSource[%s], Interval[%s], Metadata [%s] persisting Hydrant[%s]",
schema.getDataSource(),
interval,
metadataElems,
indexToPersist
);
try {
int numRows = indexToPersist.getIndex().size();
final IndexSpec indexSpec = config.getIndexSpec();
indexToPersist.getIndex().getMetadata().putAll(metadataElems);
/** * indexMerger:IndexMergerV9, Persistence will be configured in the task basePersistDirectory Lower generation segment file information * The previous index files will be merged here :io.druid.segment.IndexMergerV9#merge */
final File persistedFile = indexMerger.persist(
indexToPersist.getIndex(),
interval,
new File(computePersistDir(schema, interval), String.valueOf(indexToPersist.getCount())),
indexSpec,
config.getSegmentWriteOutMediumFactory()
);
/** * indexToPersist Be sure to check , Construct new queryable segment: namely QueryableIndexSegment( With the new persistedFile To construct ) */
indexToPersist.swapSegment(
new QueryableIndexSegment(
indexToPersist.getSegmentIdentifier(),
indexIO.loadIndex(persistedFile)
)
);
return numRows;
}
catch (IOException e) {
log.makeAlert("dataSource[%s] -- incremental persist failed", schema.getDataSource())
.addData("interval", interval)
.addData("count", indexToPersist.getCount())
.emit();
throw Throwables.propagate(e);
}
}
}
In fact, you can answer the query here jvm In pile / The use of external memory
- jvm There is a
currHydrantMaintaining data - Outside the pile is small segment file merge After persistedFile,mmap Loaded into off heap memory
obviously 1,2 Together again merge Processing can constitute the result return , The query is like this ; The core class here is FireHydrant 了 , and FireHydrant The core of must be IncrementalIndex(OnheapIncrementalIndex & OffheapIncrementalIndex)
stay druid.io Querying , Used QueryRunner This interface form deals with , Based on this, it encapsulates QuerySegmentWalker Interface is used to implement the given Query Object query
/** */
public interface QuerySegmentWalker
{
/** * Gets the Queryable for a given interval, the Queryable returned can be any version(s) or partitionNumber(s) * such that it represents the interval. * * @param <T> query result type * @param query the query to find a Queryable for * @param intervals the intervals to find a Queryable for * @return a Queryable object that represents the interval */
<T> QueryRunner<T> getQueryRunnerForIntervals(Query<T> query, Iterable<Interval> intervals);
/** * Gets the Queryable for a given list of SegmentSpecs. * * @param <T> the query result type * @param query the query to return a Queryable for * @param specs the list of SegmentSpecs to find a Queryable for * @return the Queryable object with the given SegmentSpecs */
<T> QueryRunner<T> getQueryRunnerForSegments(Query<T> query, Iterable<SegmentDescriptor> specs);
}
The implementation classes are as follows , It seems that there are related to real-time tasks

Actually added log, It is these , as follows
io.druid.segment.realtime.appenderator.SinkQuerySegmentWalker#getQueryRunnerForIntervals
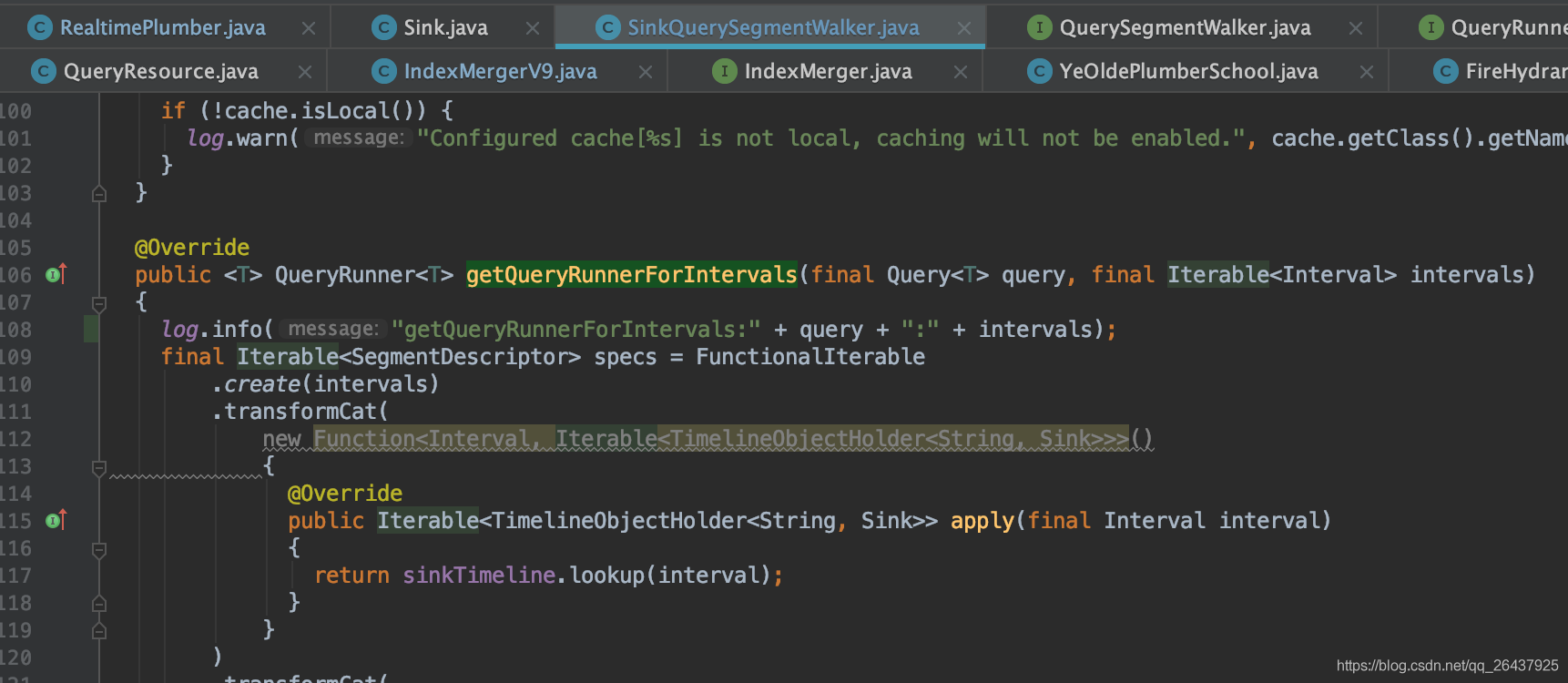
Inquire about log as follows 
Follow the code , You can see the following io.druid.segment.realtime.appenderator.SinkQuerySegmentWalker#getQueryRunnerForSegments
return new SpecificSegmentQueryRunner<>(
withPerSinkMetrics(
new BySegmentQueryRunner<>(
sinkSegmentIdentifier,
descriptor.getInterval().getStart(),
factory.mergeRunners(
MoreExecutors.sameThreadExecutor(),
Iterables.transform(
theSink,
new Function<FireHydrant, QueryRunner<T>>()
{
@Override
public QueryRunner<T> apply(final FireHydrant hydrant)
{
// Hydrant might swap at any point, but if it's swapped at the start
// then we know it's *definitely* swapped.
final boolean hydrantDefinitelySwapped = hydrant.hasSwapped();
if (skipIncrementalSegment && !hydrantDefinitelySwapped) {
return new NoopQueryRunner<>();
}
// Prevent the underlying segment from swapping when its being iterated
final Pair<Segment, Closeable> segment = hydrant.getAndIncrementSegment();
log.info("hydrant.getAndIncrementSegment():" + hydrant);
try {
QueryRunner<T> baseRunner = QueryRunnerHelper.makeClosingQueryRunner(
factory.createRunner(segment.lhs),
segment.rhs
);
// 1) Only use caching if data is immutable
// 2) Hydrants are not the same between replicas, make sure cache is local
if (hydrantDefinitelySwapped && cache.isLocal()) {
return new CachingQueryRunner<>(
makeHydrantCacheIdentifier(hydrant),
descriptor,
objectMapper,
cache,
toolChest,
baseRunner,
MoreExecutors.sameThreadExecutor(),
cacheConfig
);
} else {
return baseRunner;
}
}
catch (RuntimeException e) {
CloseQuietly.close(segment.rhs);
throw e;
}
}
}
)
)
),
toolChest,
sinkSegmentIdentifier,
cpuTimeAccumulator
),
new SpecificSegmentSpec(descriptor)
);
With hydrant Can construct QueryRunner, Of course, you can finally query
summary
This paper introduces the core of real-time task query , Not too specific , follow-up TODO
边栏推荐
- Lxml web page capture the most complete strategy
- Thirty years of MPEG audio coding
- Event express | Apache Doris Performance Optimization Practice Series live broadcast course is open at the beginning. You are cordially invited to participate!
- Overview of Qualcomm 5g intelligent platform
- Code reading - ten C open source projects
- 【流放之路-第五章】
- Analyze OP based on autoware_ global_ Planner global path planning module re planning
- [网鼎杯 2020 朱雀组]Nmap
- [7.21-26] code source - [square count] [dictionary order minimum] [Z-type matrix]
- Large scale web crawling of e-commerce websites (Ultimate Guide)
猜你喜欢

Comprehensive explanation of "search engine crawl"
Data platform data access practice

Leetcode 112: path sum
![[the road of Exile - Chapter 2]](/img/98/0a0558dc385141dbb4f97bc0e68b70.png)
[the road of Exile - Chapter 2]

What are the common cyber threats faced by manufacturers and how do they protect themselves

Wonderful use of data analysis

LeetCode 113:路径总和 II
![[golang] use select {}](/img/30/fa593ec682a40c47689c1fd88f9b83.png)
[golang] use select {}
![[netding cup 2020 rosefinch group]nmap](/img/22/1fdf716a216ae26b9110b2e5f211f6.png)
[netding cup 2020 rosefinch group]nmap
![[the road of Exile - Chapter 8]](/img/df/a801da27f5064a1729be326c4167fe.png)
[the road of Exile - Chapter 8]
随机推荐
golang启动报错【已解决】
[public class preview]: application exploration of Kwai gpu/fpga/asic heterogeneous platform
规划数学期末考试模拟二
Talk about possible problems when using transactions (@transactional)
[7.21-26] code source - [square count] [dictionary order minimum] [Z-type matrix]
Comprehensive explanation of "search engine crawl"
Sigma-DSP-OUTPUT
数学建模——自来水管道铺设问题
Thirty years of MPEG audio coding
Make logic an optimization example in sigma DSP - data distributor
StoneDB 为何敢称业界唯一开源的 MySQL 原生 HTAP 数据库?
抓包工具Charles使用
The brutal rule of blackmail software continues, and attacks increase by 105%
FPGA实现10M多功能信号发生器
5g commercial third year: driverless "going up the mountain" and "going to the sea"
把逻辑做在Sigma-DSP中的优化实例-数据分配器
[the road of Exile - Chapter 8]
Random talk on distributed development
Use of packet capturing tool Charles
Minimalist thrift+consumer