当前位置:网站首页>playwright网络爬虫实战案例分享
playwright网络爬虫实战案例分享
2022-07-27 03:34:00 【Python进阶者】
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
不寝听金钥,因风想玉珂。
大家好,我是Python进阶者。
一、前言
前几天在Python白银交流群【HugoLB】分享了一个playwright网络爬虫利器,如下图所示。

感觉挺有意思,上手难度也不算太大,这里整理一份小教程分享给大家,后面遇到常规爬不动的网站,不妨试试看这个利器,兴许会事半功倍哦!
二、实现过程
这里使用新发地网站做一个简单的示例,新发地网站最开始的时候是get请求,去年的时候开始使用post请求方式,网页发生了变化,其实你正常使用网络爬虫的常规方式,也是可以获取到数据的,而且效率也很高,这里我是为了给大家做一个playwright网络爬虫示例,拿这个网站小试下牛刀。言归正传,一起来看看吧!
新发地网站的首页如下图所示:

进入网页之后,可以看到网页的url,然后点击右侧的查看更多,即可进入到详情页,如下图所示:

此时可以看得到更多的数据量了,这里只是用一两个页面做一个示例,更多的页面等大家自己去挖掘。
启动浏览器抓包,点击网页的下一页,可以看到响应数据如下图所示:

此时的请求参数如下图所示:

依次再点击下一页,可以看到Request URL是不变的,变化的是Payload里边的current参数。

此时的请求参数如下图所示:

那么到这里的话,网页变化的规律其实已经很明显了,接下来我们只需要上playwright代码就行了,代码框架是固定的,只需要更改两个url即可,第一个是主页的url,第二个就是响应数据的response.url,具体的代码如下所示:
from playwright.sync_api import Playwright, sync_playwright
import datetime
from pprint import pprint
import traceback
import logging
from tqdm import tqdm
import json
# pip install playwright,然后终端 playwright install
"""
先用playwright写一个普通的登入网站代码,然后page.goto前面加上
page.on("request", lambda request: handle(request=request, response=None))
page.on("response", lambda response: handle(response=response, request=None))
然后可以写一个handle自定义函数,args为response和request,然后后面想怎么处理数据都可以
"""
# setup logging
logging.basicConfig(format='%(asctime)s | %(levelname)s : %(message)s', level=logging.INFO)
def handle_json(json):
# process our json data
# print(json)
for i in range(20):
data_list = json['list'][i]
# print(data_list)
id = data_list['id']
prodName = data_list['prodName']
prodCat = data_list['prodCat']
place = data_list['place']
print(id, prodName, prodCat, place)
def handle(request, response):
if response is not None:
# response url 是网站请求数据的url
if response.url == 'http://www.xinfadi.com.cn/getPriceData.html':
handle_json(response.json())
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context(ignore_https_errors=True)
# Open new page
page = context.new_page()
page.on("request", lambda request: handle(request=request, response=None))
page.on("response", lambda response: handle(response=response, request=None))
# url是网页加载的URL
url = 'http://www.xinfadi.com.cn/index.html'
page.goto(url)
# 然后之前看到有说道网站动态加载,拖动的问题。playwright可以直接用page.mouse.wheel(0, 300)解决
page.wait_for_timeout(50000)
# ---------------------
context.close()
page.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)运行之后的结果如下所示:
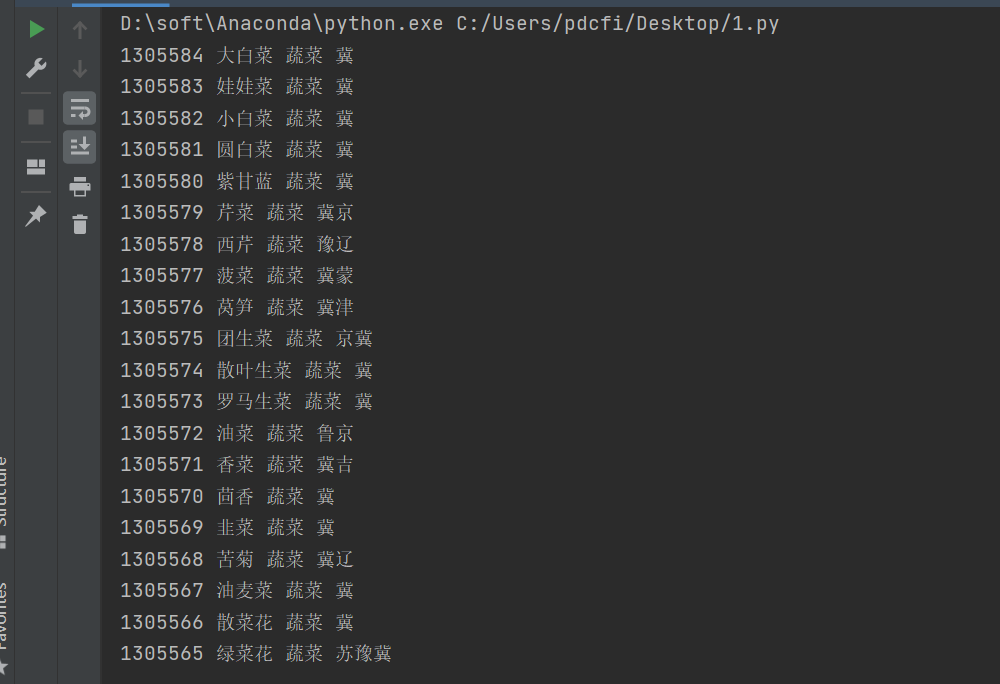
可以看到数据已经成功拿下了。在handle_json()这个函数里边,你可以针对获取到的数据做进一步的处理,如提取,保存等,也可以直接打印出来看效果,看你自己的需求了。
如果有遇到问题,随时联系我解决,欢迎加入我的Python学习交流群。

三、总结
大家好,我是Python进阶者。这篇文章主要分享了一个playwright网络爬虫实战案例教程,文中针对该问题给出了具体的解析和代码实现。
最后感谢粉丝【HugoLB】分享,感谢【月神】、【瑜亮老师】、【此类生物】、【猫药师Kelly】、【冯诚】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~
边栏推荐
- php+swoole
- 【无标题】
- Restful fast request 2022.2.2 release, supporting batch export of documents
- 链表内指定区间反转
- Elastic开源社区:开发者招募
- [small sample segmentation] msanet: multi similarity and attention guidance for boosting few shot segmentation
- 面试题 16.05. 阶乘尾数
- 法解析的外部符号 “public: virtual __cdecl nvinfer1::YoloLayerPlugin::~YoloLayerPlugin(void)“ “public: virtua
- Navicat exports Mysql to table structure and field description
- 整理字符串
猜你喜欢

【小样本分割】MSANet: Multi-Similarity and Attention Guidance for Boosting Few-Shot Segmentation

【机器学习网络】BP神经网络与深度学习-6 深度神经网络(deep neural Networks DNN)

Stm32cubemx learning notes (41) -- eth interface +lwip protocol stack use (DHCP)

C how to set different text watermarks for each page of word
[small sample segmentation] msanet: multi similarity and attention guidance for boosting few shot segmentation

Analysis of three common kinematic models of mobile chassis

356页14万字高端商业办公综合楼弱电智能化系统2022版
Ant JD Sina 10 architects 424 page masterpiece in-depth distributed cache from principle to practice pdf

ArrayList与LinkedList区别

通信协议综述
随机推荐
2022危险化学品生产单位安全生产管理人员考试题模拟考试题库模拟考试平台操作
Ribbon负载均衡策略与配置、Ribbon的懒加载和饥饿加载
Manually build ABP framework from 0 -abp official complete solution and manually build simplified solution practice
The 100th of the commercial anti counterfeiting series - boring systems and management processes can really be thrown into the trash can - by the way, analyze a dozen useless unity game self-test proj
Learning route from junior programmer to architect + complete version of supporting learning resources
Nacos启动与登录
【比赛参考】PyTorch常用代码段以及操作合集
【OBS】circlebuf
第二轮Okaleido Tiger即将登录Binance NFT,或持续创造销售神绩
利用LCD1602显示超声波测距
Internet of things smart home project - Smart bedroom
搜索旋转排序数组
c# 获取uuid
Leetcode daily question: relative sorting of arrays
452 pages, 130000 words, the overall solution of modern smart Township Xueliang project 2022 Edition
H. 265 web player easyplayer's method of opening video to the public
面试题 16.05. 阶乘尾数
技术分享 | 需要小心配置的 gtid_mode
Towhee weekly model
Which securities company has the lowest handling charge? Is it safe to open an account on your mobile phone