当前位置:网站首页>AI zhetianchuan DL regression and classification
AI zhetianchuan DL regression and classification
2022-07-26 17:48:00 【Teacher, I forgot my homework】
This paper mainly introduces Logistic Return to and Softmax Return to
One 、 Regression and classified recall
Set of given data points  And the corresponding labels
And the corresponding labels  , For a new data point x, Predict its label ( The goal is to find a mapping
, For a new data point x, Predict its label ( The goal is to find a mapping  ):
):
If  Is a continuous set , Call it Return to (regression)
Is a continuous set , Call it Return to (regression)
If Is a discrete set , Call it classification (classfication)

Polynomial regression
Consider a regression problem , Input x And the output y All scalars . Find a function  To fit the data
To fit the data



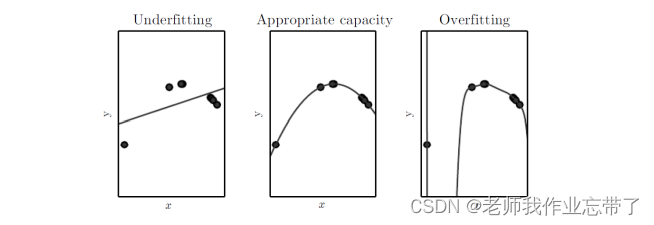
Whether linear regression or nonlinear regression , We usually pass some cost function Such as minimum mean square error (MSE), As Loss function , To make sure f Parameters of .
Linear regression
 Is linear
Is linear

among  ( bias / residual / Error term ) Can integrate
( bias / residual / Error term ) Can integrate  And get
And get 
- Set the mean square error (MSE) Is the cost function

- Find the best by minimizing the cost function w and b
Such as the least square method 、 The gradient descent method minimizes the loss function to solve the parameters .
AI Cover the sky ML- Introduction to regression analysis
Binary classification by regression
In feature space , A linear classifier corresponds to a hyperplane

Two typical linear classifiers :
- perceptron
- SVM(AI Cover the sky ML-SVM introduction )

- Return to - Forecast continuous

- classification - forecast



Binary classification using linear regression :
Assume  , Consider the case of one-dimensional features
, Consider the case of one-dimensional features

Assume , Consider the case of high-dimensional features

Binary classification using nonlinear regression
 It can be a nonlinear function , Such as :logisitic sigoid function
It can be a nonlinear function , Such as :logisitic sigoid function

Similarly, we can train nonlinear regression by training linear regression model , It's just the original
Turned into 
notes : there h Is a function such as logisitic sigoid function
Look at the problem from the perspective of probability
Suppose that the label obeys the mean Of Normal distribution , Then its maximum likelihood estimation is equivalent to minimization :

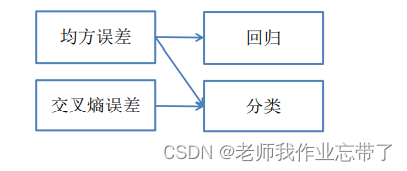
- For the return question (t yes continuity Of ), The assumption of normal distribution is natural .
- For the classification problem (t yes discrete Of ), The assumption of normal distribution would be strange .
- There are more suitable assumptions for the data distribution of the binary classification problem ----> Bernoulli distribution
Why is Bernoulli distribution more suitable for binary classification problems ?
Two 、Logistic Return to
For a binary task , One 0-1 The unit is enough to represent a label
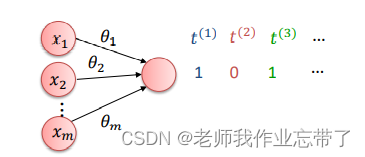
Try to learn conditional probability ( Have already put b integrate into ,x For input ,t Label )



Our goal is to find a Value makes probability 
When x Belong to the category 1 when , Take a large value, such as 0.99999.
When x Belong to the category 2 when , Take a small value such as 0.00001 ( therefore  Take a large value )
Take a large value )
We are essentially using another continuous function h Come on “ Return to ” A discrete function (x -> t)

Cross entropy error function (CSE)
For Bernoulli distribution , We maximize conditional data likelihood , Getting is equivalent to minimizing :

obtain New loss function (CSE) 
Let's take out one of them :
- so , If t=1, be E = -ln(h)

- If t=0, be E = -ln(1-h)
You can see the river .
Training and testing

II. Summary of classification problems

3、 ... and 、SoftMax Return to
We explained the one-dimensional and multi-dimensional classification above , In fact, for multi classification , Just add the number of functions as the dimension .

Pictured above , For example, for a x, The result of the three functions is 1.2、4.1、1.9, Then it can be regressed or classified according to subsequent operations . These three functions may be linear Of , It could be nonlinear Of , Such as logistic Return to .
choice Mean square error (MSE) As a loss function

Use the least square method / The gradient descent method is used to calculate the parameters .
Representation of label categories
For the classification problem , That is, through a mapping f The output is a discrete set , We have two ways to represent labels :

For the first method , There is a distance relationship between categories , So we usually use the second representation . Each dimension has only 0-1 Two results .

We only need to see which kind of point represents the closest point in a certain point of the output to classify .
From the perspective of probability :
We mentioned above , For binary tasks , Bernoulli distribution is more suitable , So we introduced logistic Return to .
When faced with multi classification tasks (K>2) when , We choose As a whole multinoulli/categorical Distribution
Review and overall planning multinoulli/categorical Distribution

Overall and distributed learning :
- Make
 Take the form of :
Take the form of :
 Take the form of :
Take the form of :
clearly , also
also 
- Given a test input x, For each k=1,2,...,K, It is estimated that


- When x Belong to the first K Class , Take a large value
- When x When it belongs to other classes , Take a small value
- because
 It's a ( Successive ) probability , We need to convert it into discrete values that match the classification .
It's a ( Successive ) probability , We need to convert it into discrete values that match the classification .
 It's a ( Successive ) probability , We need to convert it into discrete values that match the classification .
It's a ( Successive ) probability , We need to convert it into discrete values that match the classification .Softmax function
The following functions are called Softmax function :

- If
 For all
For all  All set up , Then for all Yes
All set up , Then for all Yes  But its value is less than 1.
But its value is less than 1. - If For all All set up , Then for all Yes
 .
.
 For all
For all  All set up , Then for all
All set up , Then for all  But its value is less than 1.
But its value is less than 1. .
.Again , We get the maximum conditional likelihood Cross entropy error function :

notes :
 For each K, There is only one non 0 term ( Because like (0,0,0,1,0,0))
For each K, There is only one non 0 term ( Because like (0,0,0,1,0,0))
Calculate the gradient

vector - Matrix form

Training and testing

Stochastic gradient descent

Throughout the training set , The computational cost of minimizing the hate function is very large , We usually divide the training set into smaller subsets or minibatches And then in a single minibatches (xi,yi) Optimize the cost function , And take the average .
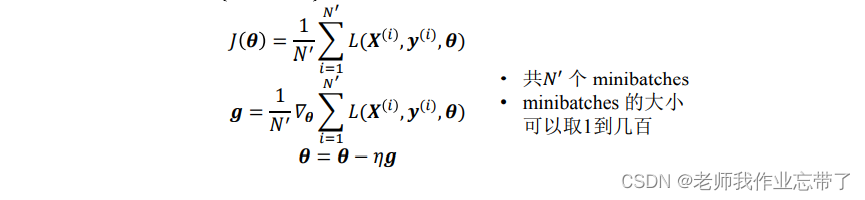
Introduce bias bias
up to now , We have assumed that 
among 
Sometimes the offset term can be introduced into  in , The parameter becomes {w,b}
in , The parameter becomes {w,b}

obtain

Regularization is usually applied only to w On

Softmax Over parameterization
There are assumptions 
New parameters  Will get the same prediction
Will get the same prediction
Minimizing the cross entropy function can have an infinite number of solutions , because :

among 
Four 、Softmax Review and logistic Review the relationship
Softmax In the regression , Make K=2


among h yes softmax function g yes logistic function
If you define a new variable  Well then logistic Regression is the same
Well then logistic Regression is the same

5、 ... and 、 summary


Cross entropy in the general sense

边栏推荐
- 天翼云Web应用防火墙(边缘云版)支持检测和拦截Apache Spark shell命令注入漏洞
- the loss outweighs the gain! Doctors cheated 2.1 million yuan and masters cheated 30000 yuan of talent subsidies, all of which were sentenced!
- uni-app
- 云渲染-体积云【理论基础与实现方案】
- Coscon'22 city / school / institution producer solicitation order
- (24) the top menu of blender source code analysis shows code analysis
- 使用 replace-regexp 在行首添加序号
- Diagram of seven connection modes of MySQL
- 【云原生】 iVX 低代码开发 引入腾讯地图并在线预览
- SQL中去去重的三种方式
猜你喜欢

(25) top level menu of blender source code analysis blender menu

RedisDesktopManager去除升级提示

第16周OJ实践1 计算该日在本年中是第几天
kudu设计-tablet

Performance tuning bugs emerge in endlessly? These three documents can easily handle JVM tuning

6-19 vulnerability exploitation -nsf to obtain the target password file

【集训Day2】Torchbearer

JS closure simulates private variable interview questions and immediately executes function Iife

AI遮天传 DL-多层感知机

即刻报名|飞桨黑客马拉松第三期盛夏登场,等你挑战
随机推荐
How to write plug-ins quickly with elisp
6-19漏洞利用-nsf获取目标密码文件
Summer Challenge openharmony greedy snake based on JS
CCS TM4C123新建工程
Hardware development and market industry
Good afternoon, everyone. Please ask a question: how to start a job submitted in SQL from the savepoint? Problem Description: using SQL in Cl
Kudu design tablet
Common super easy to use regular expressions!
Use replace regexp to add a sequence number at the beginning of a line
Environment setup mongodb
第17周自由入侵 指针练习--输出最大值
JS 函数作用域 变量声明提升 作用域链 不加var的变量,是全局变量
浅谈数据技术人员的成长之路
Heavy! The 2022 China open source development blue book was officially released
hosts该文件已设置为只读的解决方法
解决哈希冲突的几种方式
使用 replace-regexp 在行首添加序号
Sign up now | oar hacker marathon phase III midsummer debut, waiting for you to challenge
SQL injection (mind map)
Pytest(思维导图)