当前位置:网站首页>[2206] An Improved One millisecond Mobile Backbone
[2206] An Improved One millisecond Mobile Backbone
2022-06-22 11:16:00 【koukouvagia】
Abstract
- propose MobileOne, achieving SOTA performance on classification, detection, and segmentation
- analyze performance bottlenecks in activations and branching that incur high latency on mobile
- introduce re-parameterization, weight decay annealing, and progressive learning curriculum in training
Method
metric correlations
Left: FLOPs vs Latency on iPhone12. Right: Parameter Count vs Latency on iPhone 12. We indicate some networks using numbers as shown in the table above.

models with higher FLOPs or parameter counts can have lower latency
CNN-models have lower latency for similar FLOPs and parameter counts than ViT-models
Spearman rank correlation coefficient between latency-flops.

latency is moderately correlated with FLOPs and weakly correlated with parameter counts on mobile devices, even lower on CPUs
key bottlenecks
construct a 30-layer CNN on iPhone12 with different activation functions or architecture blocks common in efficient networks
activation functions
Comparison of latency on mobile device of different activation functions in a 30-layer convolutional neural network.
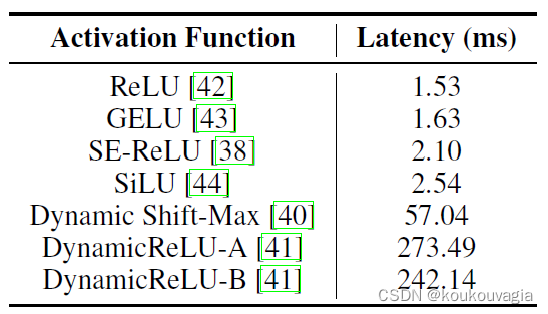
recently introduced activation functions have low FLOPs but high synchronization cost
* \implies *ReLU is used in MobileOne
architecture blocks
Ablation on latency of different architectural blocks in a 30-layer convolutional neural network.

2 key factors that affect runtime performance are memory access cost and degree of parallelism
global pooling in SE blocks * \implies *larger synchronization cost
skip connection bring in multi-branches * \implies *larger memory access cost
* \implies *no branches and limited SE blocks are used in MobileOne
MobileOne block
MobileOne block has two different structures at train time and test time. Left: Train time MobileOne block with re-parameterizable branches. Right: MobileOne block at inference where the branches are re-parameterized. Either ReLU or SE-ReLU is used as activation. The trivial over-parameterization factor k is a hyper-parameter which is tuned for every variant.

- base on MobileNet-V1 block of 3x3 depth-wise conv followed by 1x1 point-wise conv
- introduce re-parameterizable skip connection with BN along with branches
model scaling
scaling model dimensions like width, depth, and resolution can improve performance
do not explore scaling up of input resolution as both FLOPs and memory cost increase, detrimental to runtime on mobile devices
MobileOne Network Specifications.

Comparison of Top-1 Accuracy on ImageNet against recent train time over-parameterization works. Number of parameters listed above is at inference.

MobileOne have single-branched structure at inference * \implies *aggressively scale model parameters compared to competing multi-branched models
Experiment
measurement of latency
- Mobile: iOS App on iPhone12 with Core ML
- CPU: 2.3 GHz Intel Xeon Gold 5118 processor
image classification
datasets ImageNet
optimizer SGD-momentum: batch size 256, 300 epochs, weight decay 1e-4, cosine annealing to 1e-5
lr_schedule init 0.1, cosine annealing
label smoothing 0.1
Performance of various models on ImageNet-1k validation set. Note: All results are without distillation for a fair comparison. Results are grouped based on latency on mobile device.

key findings
- a lower latency on mobile, where the smallest transformer has a latency of 4ms
- MobileFormer attains top-1 accuracy of 79.3% with a latency of 70.76ms, while MobileOne-S4 attains 79.4% with a latency of only 1.86ms (38x faster)
- MobileOne-S3 has 1% better top-1 accuracy than EfficientNet-B0 and is faster by 11% on mobile
- a lower latency on CPU
- MobileOne-S4 has 2.3% better top-1 accuracy than EfficientNet-B0 while being faster by 7.3% on CPU
object detection and semantic segmentation
datasets MS-COCO
optimizer SGD-momentum: batch size 192, 200 epochs, momentum 0.9, weight decay 1e-4
lr_schedule init 0.05, linear warm-up 4500 iters, cosine annealing
datasets Pascal-VOC, ADE20k
optimizer AdamW: 50 epochs, weight decay 0.01
lr_schedule init 1e-4, warm-up 500 iters, cosine annealing to 1e-6
(a) Quantitative performance of object detection on MS-COCO. (b) Quantitative performance of semantic segmentation on Pascal-VOC and ADE20k datasets. † \dag †This model was trained without Squeeze-Excite layers.

key findings
- MobileOne-S4 outperforms MNASNet by 27.8% and best version of MobileViT by 6.1%
- MobileOne-S4 outperforms Mobile ViT by 1.3% and MobileNetV2 by 5.8%;
- MobileOne-S4 outperforms MobilenetV2 by 12%; With the smaller MobileOne-S1 backbone, we still outperform it by 2.9%
ablation studies
training settings
opposed to large models, small models need less regularization to combat overfitting
adopt weight decay regularization in early stages of training, instead of completely removing it
Ablation on various train settings for MobileOne-S2 showing Top-1 accuracy on ImageNet.

over-parameterization factor
Comparison of Top-1 on ImageNet for various values of trivial over-parameterization factor k k k.

effect re-parametrizable branches
Comparison of Top-1 on ImageNet for various values of trivial over-parameterization factor k k k.

边栏推荐
- Go microservice (I) - getting started with RPC
- IO之ByteArrayStream案例
- The R language dplyr package mutate function divides two numeric variables in the dataframe to create a new data column (create a new variable)
- In a word, several common methods of uploading Trojan horse
- General graph maximum matching (with flower tree) template
- GEE——Global Flood Database v1 (2000-2018)
- 6-10 global status management - Global store
- Realization of simple particle effect in canvas
- "Dare not doubt the code, but have to doubt the code" a network request timeout analysis
- 奋斗吧,程序员——第四十八章 千金纵买相如赋,脉脉此情谁诉
猜你喜欢

xlrd. biffh. XLRDError: Excel xlsx file; Not supported solution

The father of the college entrance examination student told himself at night that what he cared about most was not the child's performance, and the turning point was not false at all

PHP database mysql question

How many of the eight classic MySQL errors did you encounter?

“不敢去怀疑代码,又不得不怀疑代码”记一次网络请求超时分析

迪利克雷前缀和学习笔记

Flink status management

牛客挑战赛53C

Wechat applet project example - image processing gadget (self-made low configuration version of Meitu XiuXiu)

【软工】 设计模块
随机推荐
MATLAB中cellstr函数的使用
2022年度敏捷教练行业现状报告(2022 State of Agile Coaching Report)
【云图说】 第244期 三分钟了解容器镜像服务
Realization of simple particle effect in canvas
Bytestream case of IO
electron添加SQLite数据库
SAVE: 软件分析验证和测试平台
【软工】获取需求
Reader case of IO
xlrd. biffh. XLRDError: Excel xlsx file; Not supported solution
牛客练习赛94D题解
牛客练习赛94F题解
初识ElastricSearch
How to improve customer conversion rate on the official website
牛客挑战赛54F题解 & 李超树学习笔记
一般图最大匹配(带花树)模板
Two ways of traversing binary tree: preorder, inorder and postorder
Reader case of IO
克鲁斯卡尔重构树
Interpretation of basic requirements for classified protection of network security (GBT 22239-2019)