当前位置:网站首页>[meta learning] classic work MAML and reply (Demo understands meta learning mechanism)
[meta learning] classic work MAML and reply (Demo understands meta learning mechanism)
2022-06-22 06:54:00 【chad_ lee】
Meta Learning
MAML ICML’17
MAML And model structure 、 Task independent , The only requirement is that the model has parameters .
MAML Generate an initialization of the weight , Other models can be based on a small number of samples fine-tuning. therefore MAML Input and function of and Pre-train It's the same .
Algorithm

MAML You can use this picture to make it clear , The left figure shows the algorithm flow ∣ T i ∣ = 1 |\mathcal{T}_{i}|=1 ∣Ti∣=1 The situation of .
First , The model has an initialization parameter θ \theta θ:

Take a tasks T i ∼ p ( T ) \mathcal{T}_{i} \sim p(\mathcal{T}) Ti∼p(T). In this task Of K K K Training data ( also called support set) Last training , Calculate the gradient ∇ θ L T i ( f θ ) \nabla_{\theta} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta}\right) ∇θLTi(fθ)【 The first 5 That's ok 】, Then update it with a gradient θ \theta θ( It can be many times ), obtain θ ′ \theta^{\prime} θ′.【 The first 6 That's ok 】:
If it's normal training , Then a batch of data will be sampled , And then to θ ′ \theta^{\prime} θ′ Continue training as a starting point ,MAML It is :

And then use θ ′ \theta^{\prime} θ′ stay task i Test data for ( also called query set) Last training , Calculate the gradient ∇ θ L T i ( f θ i ′ ) \nabla_{\theta} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta_{i}^{\prime}}\right) ∇θLTi(fθi′), to update θ \theta θ【 The first 8 That's ok 】:

Such a ( A group of )task It's done , Go on to the next ( Next batch )task.
The form is the same for classification or regression tasks , It's just that the loss function is different from how to deal with data :

experiment
Omniglot Data sets :1623 Letters , Each letter has 20 A picture .【 But this data set is relatively simple , The accuracy has 99+ 了 】
MiniImagenet Data sets : Training set 64 Classes , Verification set 12 Classes , Test set 24 Classes .【 current sota It's already MAML Twice as much 】
The Omniglot and MiniImagenet image recognition tasks are the most com- mon recently used few-shot learning benchmarks.
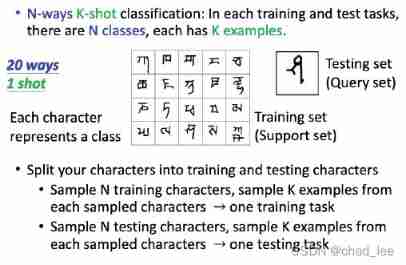
Training is “N-ways K-shot”, That is, in every training and test tasks in , Yes N individual class,K Samples :
Reptile:On First-Order Meta-Learning Algorithms Arxiv’18
OpenAI Articles produced ,follow And improve MAML, The number of citations has 700+
The core idea
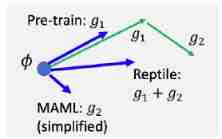
Above, MAML My thoughts are rather convoluted , Initial parameters of the model θ 0 \theta^{0} θ0 First in the dataset A On the training to get θ ′ \theta^{\prime} θ′; Then sample a data set B, Calculation θ ′ \theta^{\prime} θ′ stay B The gradient above , Then on θ 0 \theta^{0} θ0 updated , obtain θ 1 \theta^1 θ1:
θ 1 = θ 0 − ε ∇ θ ∑ T ⋅ ∈ P L T i ( f θ ′ ) \theta^{1}=\theta^{0}-\varepsilon \nabla_{\theta} \sum_{\mathcal{T} \cdot \in P} \mathcal{L}_{\mathcal{T}_{i}}\left(f_{\theta^{\prime}}\right) θ1=θ0−ε∇θT⋅∈P∑LTi(fθ′)
MAML A good initial parameter is obtained by training θ \theta θ( Better than pre training ), The calculation of the second derivative will be involved in the calculation of the gradient ,MAML Using the first derivative approximation (FOMAML) To deal with , simplified calculation .
What this article puts forward Reptile stay FOMAML To further simplify the parameter update method , There is no need to calculate the second loss gradient , Direct use θ 0 − θ ′ \theta^{0}-\theta^{\prime} θ0−θ′ As a gradient , Update the parameters :
θ 1 = θ 0 − ε ( θ 0 − θ ′ ) \theta^{1}=\theta^{0}-\varepsilon\left(\theta^{0}-\theta^{\prime}\right) θ1=θ0−ε(θ0−θ′)
Pictured above , Initial parameter θ 0 \theta^0 θ0 In the data set A Do more batch The calculation of reached the parameter θ ′ \theta^{\prime} θ′, And then back to θ 0 \theta^0 θ0, Calculation θ 0 − θ ′ \theta^{0}-\theta^{\prime} θ0−θ′, And update to get θ 1 \theta^1 θ1. If it's normal training , Will not return to θ 0 \theta^0 θ0, Will θ ′ \theta^{\prime} θ′ Continue updating for starting point .
Specially , If there is only one data in each data set / One batch data , that Reptile Will degenerate into ordinary training .
Pre-train、MAML and Reptile The difference between :
Task Divide
OpenAI Of Reptile The blog of There is one of them. demo, The image shows Reptile The wonder of , It also helps to understand task The definition of

There is already a built-in Reptile Well trained few shot learning Three classification model , The user can give three training samples ( One for each of the three categories ), The model will be fine tuned on three samples , This is it. 3-way 1-shot. Then draw a test sample on the right , The model will give the probability distribution of three classes .
here “ Chi Chi camel Chi ” The four pictures are one 3-way 1-shot Model task.
ProtoNet、MAML、Reptile、MetaOptNet、R2-D2 Data set partitioning 、 The task division is basically the same , They also mentioned in the article , To ensure the comparative effect of the experiment ,follow The experimental setup of the previous article , No new task. Just some training trick, among ProtoNet For model performance “Higher way”、R2-D2 use random shot Training models .
边栏推荐
- Dongjiao home development technical service
- 关于solidity的delegatecall的坑
- 5G-GUTI详解
- Single cell literature learning (Part3) -- dstg: deconvoluting spatial transcription data through graph based AI
- What exactly is the open source office of a large factory like?
- JS中如何阻止事件的传播
- Chrome 安装 driver
- 生成字符串方式
- Flink core features and principles
- iframe框架,,原生js路由
猜你喜欢

【5G NR】NG接口

QT connect to Alibaba cloud using mqtt protocol

On the pit of delegatecall of solidity

【Rust 日报】2022-01-23 WebAPI Benchmarking

【5G NR】NAS连接管理—CM状态

SQL injection vulnerability (XII) cookie injection
[5g NR] ng interface
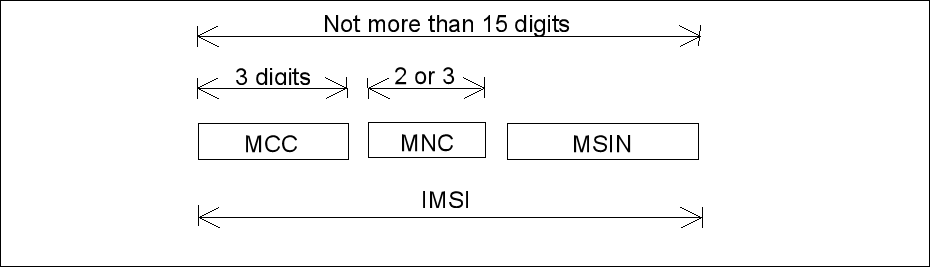
5g terminal identification Supi, suci and IMSI analysis

OpenGL - Draw Triangle

低代码开发一个合同应用
随机推荐
Generate string mode
【M32】单片机 svn 设置忽略文件
自然语言处理理论和应用
Languo technology helps the ecological prosperity of openharmony
Armadillo安装
JS中如何阻止事件的传播
[openairinterface5g] ITTI messaging mechanism
OpenGL - Draw Triangle
【Rust 日报】2022-01-23 WebAPI Benchmarking
首次用DBeaver连接mysql报错
Databricks from open source to commercialization
Xh_ CMS penetration test documentation
[php]tp6 cli mode to create tp6 and multi application configurations and common problems
(multithreaded: producer consumer mode) blocking queue
OpenGL - Textures
2021-05-12
[M32] SCM xxx Simple interpretation of map file
cookie的介绍和使用
Introduction to 51 Single Chip Microcomputer -- the use of Proteus 8 professional
SQL injection vulnerability (XII) cookie injection