当前位置:网站首页>【机器翻译】SCONES——用多标签任务做机器翻译
【机器翻译】SCONES——用多标签任务做机器翻译
2022-07-25 09:23:00 【Tobi_Obito】
《Jam or Cream First?Modeling Ambiguity in Neural MachineTranslation with SCONES》 https://arxiv.org/pdf/2205.00704.pdf
https://arxiv.org/pdf/2205.00704.pdf
前言
之前有负责过一个层级多标签分类的项目,所以对于由多分类到多标签的区别十分清楚,最近刷到这篇论文顿时来了兴趣,然后发现方法也十分简单,基本就是一个标准多标签任务的模式。尽管简单,但这样做并不是为花而花的“花板子”,其准确抓住当前机器翻译训练方式导致的问题——decoding过程中模型输出层的softmax抑制了“非ground truth但合理”词的生成可能性,而转化为多个二分类+sigmoid的常见多标签任务形式则正好避开了这一问题,所以重点就转移到了对如何拆分建模为多个二分类任务以及有效的多标签loss的设计。
从多分类到多标签
这里先快速介绍下多标签(multi-label)分类的一种典型模式。
抛开模型结构,常见的单标签多分类任务对于模型输出的处理是:对logit进行softmax激活完成归一化(概率化),然后以多分类交叉熵作为损失进行训练。
那么直接用上述模式做多标签分类任务可不可以?问题出在哪里?
1.多分类交叉熵(CE)不兼容
多分类交叉熵的计算要求ground truth必须是one-hot的,而多标签任务的ground truth显然是multi-hot的。那么直接照葫芦画瓢行不行?多分类交叉熵既然是选择one-hot中的1位置的概率进行计算,那么多标签就选multi-hot中的1位置的概率计算交叉熵再求和可不可以,但这里有2个问题:第一,求和带来的不确定性指导;第二,概率的归一性质。
对于第一个问题,设想如下情况:对于一个有两个正确标签的样本(不妨设label=[1,1]),其预测值为[0.3, 0.7]或[0.7, 0.3]在按上述求和方式计算交叉熵时计算结果完全相同,这意味着在多个正确标签的情形下对于各正确标签是无区分度的。读者可能会想:这也问题不大,只要知道哪些是正确标签就行,区分度不必要,但实际上由于多标签的组合多样性,会导致学习难度大幅增加。而第二个问题则是致命问题。
对于第二个问题,由于预测向量prob的计算是由logit通过softmax进行概率化后的,意味着预测向量内部所有的元素和为1,在上述计算方式下,label=[1,1]带来的“引导”是使预测向量趋于[0.5, 0.5],那么label=[1,1,1]则“引导”预测向量趋于[0.3, 0.3, 0.3],那么预测的阈值就无法设置(多标签显然要选取超过阈值的为预测结果,而不是单标签情形下直接选最大即可),从而导致无法进行预测。这个问题可以形象地描述为softmax导致的“正确标签相互抑制”问题。
解决上述问题的一个典型思路就是抛开概率化,将每个标签的分类视为二分类任务,模型输出的预测向量维度不变,但每个位置割裂、独立地看作为一个标签的1/0二分类问题,这样通过一个固定阈值就可以得到多标签预测结果:将预测值超过阈值的位置对应的标签为1。比如,阈值为0.5,预测向量[0.3, 0.9, 0.7]意味着预测结果为[0, 1, 1]。那么具体做法就是:在模型输出的每个位置过一个sigmoid将值限制在[0, 1]区间内,再使用二分类交叉熵(BCE)计算损失从而训练。
机器翻译中的“多标签”
定下多标签模式为logit->sigmoid->bce loss,那么翻译任务怎么建模为多标签任务?将每个翻译词的预测视为多标签分类,正确(或者说合理)的词视为正标签,vocab中的所有其它词视为负标签,于是建模为(论文公式5、6、7、8):
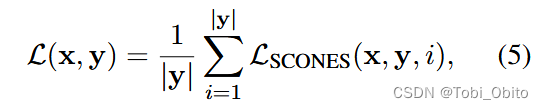

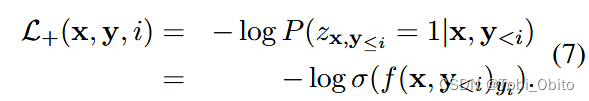
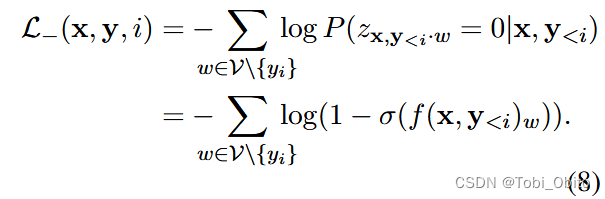
总结一下就是拆分成每个翻译step,ground truth word作为正标签,非ground truth word(in vocab)作为负标签,由α调节两个loss。
结语
这篇论文的方法到这里就结束了,论文后面特意强调了一下上述loss与特别相似的Noise-Contrastive Estimation(NCE)的区别,但个人认为区别更多的还是在于应用思想,技术性的区别仅是在翻译任务中负标签不再是噪声,而是vocab中的所有非ground truth词。回过头复盘发现方法上基本就是一个多标签分类方法,通过这个简单思路不错地解决了softmax带来的合理词翻译相互抑制的情况。最后通过实验证明确实该方法达成预期,有效缓解了softmax+ce形式带来的beam search curse问题,说白了就是合理词的翻译抑制情况得到缓解,从而在近义句的翻译实验结果上表现出了很好的效果,并且速度相对更有优势(小的beam size就能达到比传统方式大的beam size更好的效果),从而能够在达到相同水平的performance下翻译速度更快。
边栏推荐
- Customize the view to realize the background of redeeming lottery tickets [elementary]
- 【数据挖掘】第二章 认识数据
- [code source] add brackets to the daily question
- [dimension reduction strike] Hilbert curve
- *7-2 CCF 2015-09-2 date calculation
- 深度估计自监督模型monodepth2在自己数据集的实战——单卡/多卡训练、推理、Onnx转换和量化指标评估
- SurfaceView 闪屏(黑一下问题)
- 自定义Dialog 实现 仿网易云音乐的隐私条款声明弹框
- Kotlin 实现文件下载
- *6-2 CCF 2015-03-3 Festival
猜你喜欢

Evolution based on packnet -- review of depth estimation articles of Toyota Research Institute (TRI) (Part 1)

About C and OC

Get to know opencv4.x for the first time --- add salt and pepper noise to the image

yolov5实现小数据集的目标检测--kolektor缺陷数据集

Preliminary understanding and implementation of wechat applet bottom navigation bar

OC -- object replication
基于PackNet的演进——丰田研究院(TRI)深度估计文章盘点(上)

Voice chat app source code - produced by NASS network source code

初识Opencv4.X----图像卷积

In depth interpretation of C language random number function and how to realize random number
随机推荐
Some usages of Matlab's find() function (quickly find qualified values)
【数据挖掘】第四章 分类任务(决策树)
chmod和chown对挂载的分区的文件失效
[code source] daily one question non decreasing 01 sequence
括号匹配问题
【Android studio】批量数据导入到android 本地数据库
解决esp8266无法连接手机和电脑热点的问题
MySQL与Navicat安装和踩坑
单目深度估计自监督模型Featdepth解读(下)——openMMLab框架使用
About C and OC
Use kotlin use to simplify file reading and writing
Get to know opencv4.x for the first time --- add Gaussian noise to the image
[deep learning] self encoder
微信小程序实现轮播图(自动切换&手动切换)
OC -- object replication
MLOps专栏介绍
First knowledge of opencv4.x --- image histogram matching
Bracket matching problem
目标检测与分割之MaskRCNN代码结构流程全面梳理+总结
基于机智云平台的温湿度和光照强度获取