当前位置:网站首页>[cache series] completely solve the problems of cache avalanche, breakdown and penetration
[cache series] completely solve the problems of cache avalanche, breakdown and penetration
2022-07-27 14:30:00 【Shi Junfeng is moving bricks】
Cache avalanche
Definition
Cache avalanche means that in a short time , A large number of caches expire at the same time , At this time, a large number of requests miss the cache , Thus, it directly queries the database and causes great pressure on the database , In severe cases, it may lead to database downtime , This situation is called cache avalanche .
Solution
Scheme 1 : Randomize expiration time
Introducing Cache Aside Pattern We set the cache uniformly 60s The expiration time of , And focus on hot spots key The cache of is initialized in advance when the service is released .
In doing so , After that 60s after , hotspot key The cache of will expire at a uniform time , Most of the traffic will be loaded DB Logic of data entering cache . therefore , We can try to set a range of random numbers for the cache expiration time , such as 60s ~ 120s, In this way, some caches expire later , Share some into DB Pressure to load data .
cacheService.set(key, data, 60 + new Random().nextInt(60));
Copy code The selection of random time range depends on the actual business , Generally, the probability of cache avalanche can be greatly reduced when the expiration time is set dispersedly .
Option two : Cached data never expires
Since the problem of cache avalanche is caused by cache unified expiration , The cache data can be updated without setting the expiration time , And then update DB The operation of cannot be deleted Cache, Change to update Cache. The whole update operation needs to focus on hot spots key Lock , Otherwise, the data inconsistency mentioned before will appear .
Some friends will ask , If it is updated sometimes DB succeed , But update Cache failed , What should we do if the subsequent query is not the latest data ?
Here you can design a Timing task , For example, query all data every hour DB Data brush cache , Ensure that the impact of previous update failures will not be great .
But this approach does not apply to all businesses , If there is too much cached data , It will take up a lot of cache resources . You can make some choices , Set a larger number of requests key Never expire .
Cache breakdown
Definition
Cache breakdown refers to a Hot cache , If there are a large number of concurrent requests when the cache expires , Because there is no concurrency control , They are likely to bypass at the same time if(data == null) Judge the condition , Enter load DB Logic of data entering cache , So as to give DB Cause great pressure and even downtime , Such a situation is called Cache breakdown .
Solution
Cache breakdown can actually be understood as a special cache avalanche , Therefore, the solution given can be further optimized on the basis of cache avalanche .
Scheme 1 : Line up with locks
Randomize expiration time Basically, it can significantly reduce different caches key Probability of expiration at the same time , On the basis of its programme , To one key Load after the read cache does not exist DB The logic of doing concurrency control , It can also better solve the problems of cache avalanche and cache breakdown .
The specific logic of concurrency control , Here's an example of .
Suppose there is a certain key The number of concurrent requests is 1000, There must be a request to get the lock first , Then go to DB The loading data will be updated to Cache. And the rest 999 Requests will be blocked by locks , But there will be no direct error reporting , Instead, set a waiting time , such as 2s.
When requested 1 to update Cache after , Release the lock . The remaining 999 Requests are queued to acquire locks in turn , When requested 2 After obtaining the lock and entering the loading logic , Because of the request 1 It has been updated Cache, So in fact, you can query here again Cache, The query directly returns , There is no need to load the data again .
but 2s Waiting time , May only deal with 199 A request , Now there are still 800 A request , It will enter the process of lock acquisition timeout failure . Actually request 1 It has been updated Cache 了 , Therefore, the process of obtaining lock failure is to query again Cache, With the return , Otherwise, the error reporting system is busy .
Take a look at the code :
public class DataCacheManager {
public Data query(Long id) {
String key = "keyPrefix:" + id;
// The query cache
Data data = cacheService.get(key);
if(data == null) {
try {
cacheService.lock(key, 2);
// First check Cache
Data data = cacheService.get(key);
if(data != null) {
return data;
}
// Inquire about DB
data = dataDao.get(id);
// Update cache
cacheService.set(key, data);
} catch (tryLockTimeoutException e) {
// Check the cache again after timeout , To be is to return , Otherwise, throw an exception
data = dataDao.get(id);
if (data != null) {
return data;
}
throw e;
} finally {
cacheService.unLock(key);
}
}
return data;
}
}
Copy code Option two : Hot data never expires
alike , The cache breakdown problem is also due to Cache Due to expiration , As long as the hot data Cache Set to never expire to avoid .
Cache penetration
Definition
Cache breakdown refers to data that is not in the cache or database , But users still send a lot of requests , This causes every request to go to the database , To crush the database .
Usually, this situation will not occur if you follow the normal page operation , For example, the goods that you click in from the homepage or list page of e-commerce must exist . But someone may forge http request , And changed goodsId by 0 Then a large number of requests are made , The goal is to bring down your system ~ So we need to prevent the tragedy in advance .
Solution
Scheme 1 : Parameter checking
Request from client , Check the parameters , Directly intercept when the inspection conditions are not met . For example, commodities id Certainly not less than 0, Avoid requesting downstream .
Obviously , This scheme cannot completely prevent penetration , If a normal number is passed , such as goodsId = 666666, It happens that there is no such product , I can't stop it .
Option two : Cache null
Since it is because of the request DB No data , Such data is also stored Cache Just go to China , You can save a "null" It's worth , Just make sure it is not consistent with the normal structure , The following query identifies "null" And then you go back null that will do .
however , It's best to set a reasonable expiration time , because key The corresponding data may not always be null.
Option three : The bloon filter (Bloom Filter)
About the bloon filter , More on that later . Its principle is not difficult , It's a data structure , Using very little memory , You can judge a lot of data “ It must not exist or may exist ”.
For cache penetration , We can hash all the query data conditions into a sufficiently large bloom filter , The request will be intercepted by the bloom filter first , Data that must not exist will be intercepted and returned directly , So as to avoid the next step on DB The pressure of the , Possible data can go to DB Actual query , But the probability is small, so the impact is small .
Bottom line plan :DB Current limiting & Downgrade
Cache avalanche 、 breakdown 、 To penetrate the three problems is to gossip about the database , So the core problem is how to ensure that the database will not be gossip .
Consider from the database level , It can't control how many requests you make , I'm sure I won't completely believe those optimization guarantees you make , In case the code you write has bug Right ~ The safest way is to protect yourself , This protection is current limiting .
Suppose you set up 1s Can pass 1000 Current limit of requests , If this time comes 2000 A request , front 1000 Normal execution , after 1000 One triggered current limiting , You can use your configured degradation logic , For example, return some configured default values , Or give a friendly error prompt . The current limit here should be targeted , For example, the read request of a hotspot table has a separate current limiting configuration , Ensure that other normal requests are not affected by current limiting .
summary
I don't know if you noticed , There is a solution that can solve the problems of cache avalanche and cache penetration at the same time , That is to make the data never expire . But it only applies to caching key Not many scenes , But in fact, most of our students do business caching key Not too much , Even some larger e-commerce projects , There are also many scenarios that are applicable .
For example, the cache of goods , Generally, the maximum is hundreds of millions to billions ,Redis A single instance can store at most 2 Of 32 Subordinate key, At least you can save 2.5 Billions of key, Therefore, caching is usually acceptable in cluster scenarios key A great deal of , Only a single key Not too big .
even to the extent that , If the cache never expires , Take cached data as the main data source (Cache If you can't find it in, don't query DB 了 ), It can also solve the problem of penetration . In other words, I have specially encapsulated such a framework in my work , Products have been accessed , Activities and other systems , After writing the follow-up, share it ~
I am participating in the recruitment of nuggets technology community creator signing program , Click the link to sign up for submission .
边栏推荐
- codeforces 1708E - DFS Trees
- YOLOX改进之一:添加CBAM、SE、ECA注意力机制
- JS epidemic at home, learning can't stop, 7000 word long text to help you thoroughly understand the prototype and prototype chain
- Lesson 3: reverse word order
- Electronic bidding procurement mall system: optimize traditional procurement business and speed up enterprise digital upgrading
- 进程间通信
- GoPro access - control and preview GoPro according to GoPro official document /demo
- Hdu4496 d-city [concurrent search]
- [idea] set to extract serialVersionUID
- Is the security of online brokerage app account opening guaranteed?
猜你喜欢

Recursive method to realize the greatest common divisor

Toward Fast, Flexible, and Robust Low-Light Image Enhancement(实现快速、灵活和稳健的弱光图像增强)CVPR2022
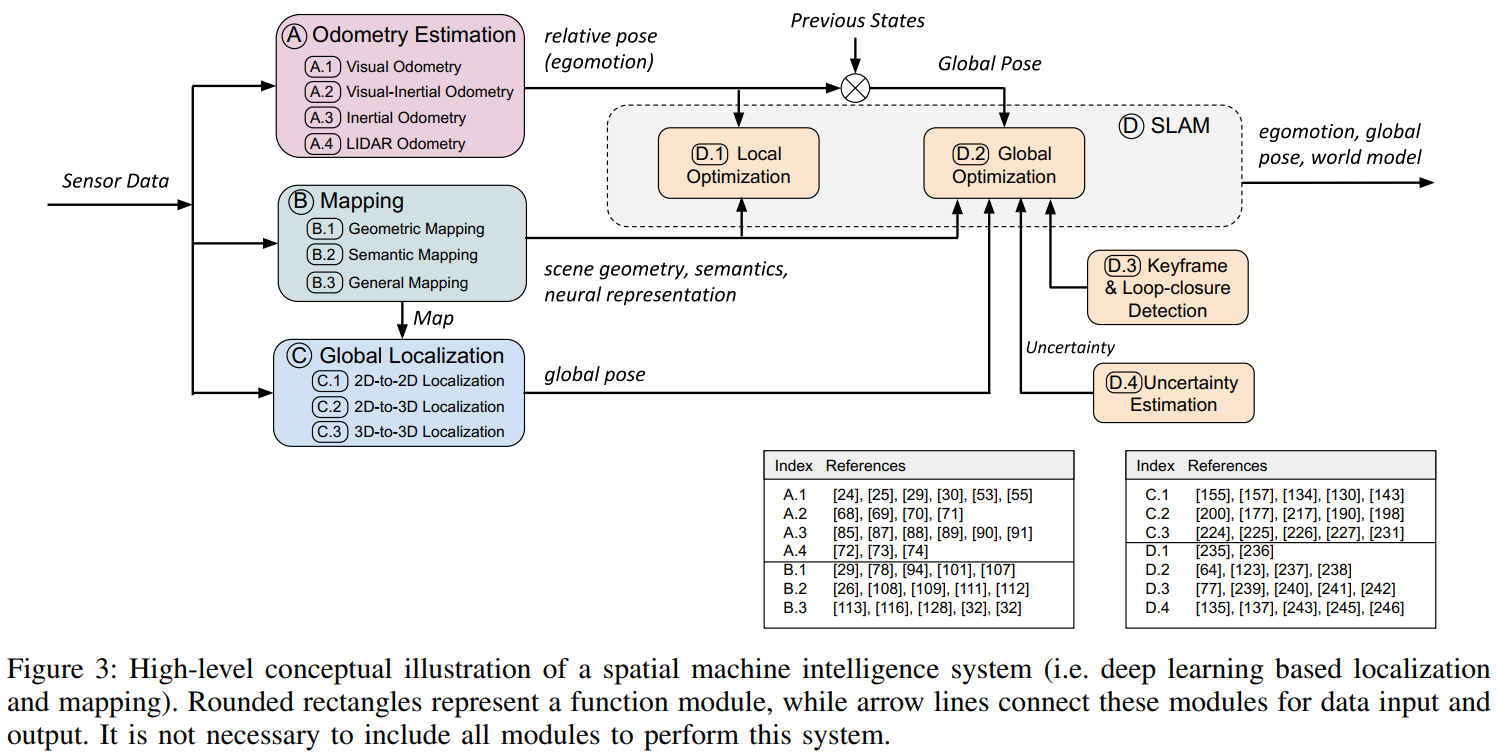
SLAM综述阅读笔记四:A Survey on Deep Learning for Localization and Mapping: Towards the Age of Spatial 2020

Lighting 5g in the lighthouse factory, Ningde era is the first to explore the way made in China

Architecture - the sublimation of MVC

Shell编程规范与变量

MySQL advanced II. Logical architecture analysis
Import the virtual machine officially made by Kali Linux into Oracle VirtualBox

Unity3d learning note 10 - texture array

Jing Xiandong and other senior executives of ant group no longer serve as Alibaba partners to ensure independent decision-making
随机推荐
文献翻译__tvreg v2:用于去噪、反卷积、修复和分割的变分成像方法(部分)
Flat die cutting machine
Recursive method to realize the greatest common divisor
第3章业务功能开发(添加线索备注,自动刷新添加内容)
Import the virtual machine officially made by Kali Linux into Oracle VirtualBox
codeforces 1708E - DFS Trees
【笔记】逻辑斯蒂回归
基于在线问诊记录的抑郁症病患群组划分与特征分析
this指向问题,闭包以及递归
Golang excellent open source project summary
次小生成树【模板】
[training day4] card game [greed]
NFT 的 10 种实际用途
Vscode -- create template file
MySQL advanced II. Logical architecture analysis
Good architecture is evolved, not designed
watch VS watchEffect
【多线程的相关内容】
Is the security of online brokerage app account opening guaranteed?
解气!哈工大被禁用MATLAB后,国产工业软件霸气回击