当前位置:网站首页>Technical exploration: 360 digital subjects won the first place in the world in ICDAR OCR competition
Technical exploration: 360 digital subjects won the first place in the world in ICDAR OCR competition
2022-06-22 02:23:00 【CSDN cloud computing】
ICDAR( International Conference on document analysis and recognition ) yes OCR Identify one of the most authoritative meetings in the field . In the near future ,360 Several branches in ICDAR2019-SROIE(Results - ICDAR 2019 Robust Reading Challenge on Scanned Receipts OCR and Information Extraction - Robust Reading Competition) Top of the list .
OCR(Optical Character Recognition, Optical character recognition ) Technology is an important branch of computer vision . It mainly includes three aspects , Text detection 、 Text recognition and visual information extraction . Text detection is through OCR The algorithm locates the text in the image , Generally, the position of text is indicated by four sides or rectangular boxes . Character recognition is through recognition algorithm or model , Transcribe the text in the image of a given text segment in the form of a string . Visual information extraction is to extract the key information defined by people from the image , Such as name , Gender , Phone number, etc .360 The Department hopes to share its exploration and summary in text recognition and language error correction , Can bring some help or inspiration to the industry .
- SROIE2019 Introduction to the event
stay ICDAR2019 Robust Reading Competitions Of 6 On a race track [1~6],SROIE2019 Pay more attention to the text line detection of commercial super small ticket 、 Identification and information extraction , This is also OCR The current difficulties in the field ,ICDAR Because of its high technical difficulty and strong practicability , It has always been a major scientific research institution 、 The competitive focus of technology companies , Attract many teams at home and abroad to participate .
1.1 Introduction to the event
SROIE2019 It is divided into three sub tasks : Text detection ( It is required to give the position coordinates of the text area in the original drawing )、 Text recognition ( Based on the given text region clipping graph , Correctly identify the text content )、 Visual information extraction ( Extract the key information in the recognized text line , Like the price 、 Date, etc. ). This time we focus on SROIE Text line recognition task in , The evaluation index is F1 score Evaluate model performance .F1 score It's the recall rate Recall And accuracy Precision The harmonic mean of , The calculation method of the three is as follows (1) (2) (3) Shown .

among ,TP,FP,FN respectively True Positive,False Positive as well as False Negative.TP,FP,FN The definition of is based on the recognized text line and the given GT Compare word by word , It is completely correct to judge that the recognition is correct .SROIR The text recognition task data set contains 33626 Zhang training set and 19385 Zhang test set , The annotation format of the training set is to give the given text line image and the corresponding text , Pictured 1 Shown [1].
![]()
chart 1 Training set data sample
1.2 Competition difficulties
- The font of the text line is blurry . Official game data set , All from the scanned images of small settlement receipts of supermarkets , Because the small tickets are machine printed and stored for a long time , As a result, the scanned text lines are severely worn and missing , Incomplete font strokes, etc , Here we are OCR Recognition algorithms pose great challenges .
- The image of the text line is bent . There is a large proportion of bending in the given text line image , The current mainstream text line recognition algorithms are more robust to horizontal text recognition , Curved text line recognition is OCR Identify industry challenges .
- Annotation ambiguity . The given text line does not exist in the corresponding text image 、 Space marking error and shape near word marking error , This brings a great impact on the generalization of the algorithm .
- Technical solution
Algorithm , Data and computing power are the three carriages that promote the evolution of deep learning , In this section, we will introduce the above three parts in detail , And aiming at 1.2 The difficulties mentioned above put forward our solutions . in the light of SROIE Text line recognition in , First, we use CRNN[7] Technical solution , Also on CRNN Medium Encoder and Decoder A lot of analysis and comparative experiments have been done in this part , Got a very good baseline Model . secondly , In view of the ambiguity of this text , We have generated nearly 5000W And train on the data set to get a pre training model , Based on the pre training model finetune, The model has been greatly improved 5.4%. Finally, aiming at the problem of text line bending, we propose a method based on tps+unet Self learning preprocessing module , The model further improves 2.6%. Through the optimization of the above technical scheme, we have finally submitted Recall,Precision and F1 Score Respectively reached 97.68%,97.79% and 97.74%, this 3 All the evaluation indicators are No. 1 . In addition, we also use the language error correction model 、loss And the choice of training strategies , It has brought certain improvement to the final model effect .
2.1 CRNN Model introduction
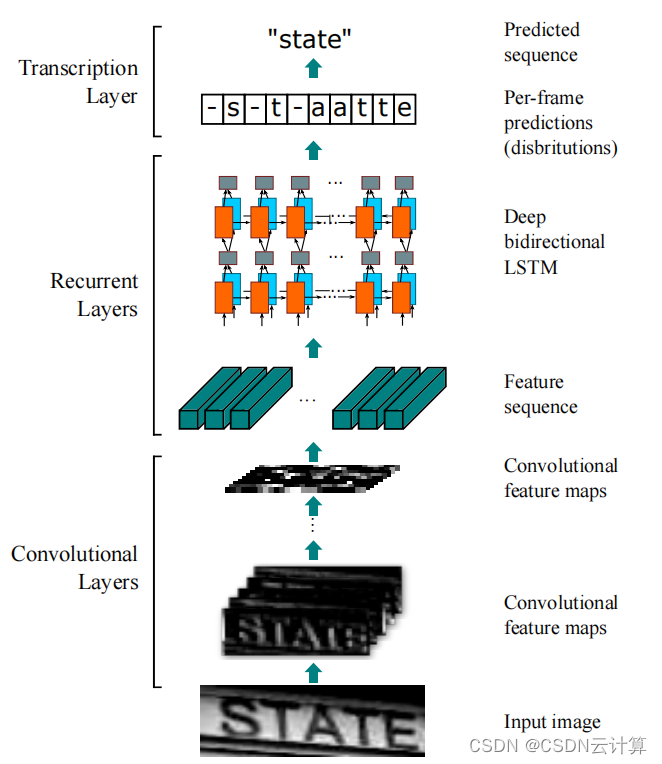
chart 2 CRNN Architecture diagram
For text recognition model , We refer to CRNN Divide the body of the model into two parts . They are the methods for feature coding of image data Encoder( Corresponding upper chart Medium CNN layer ) And decoding the text sequence Decoder( Corresponding to Recurrent Layers and Transcription Layers).
about Encoder, We tested the current OCR Mainstream technology MobileNet[8],EfficientNet[9],ResNet[10] etc. . Finally, we chose the one that is excellent in both performance and parameter quantity ResNet And for different layers ResNet Experiments were carried out .
about Decoder, It can be further divided into a part for converting an image slice sequence to a text sequence and a part for decoding and outputting a text sequence . For the first part , We tested the current mainstream sequence model , Such as Transformer[11],LSTM[12] etc. . Final , We chose the one that is better in performance and stability BiLSTM[13]. Different from ordinary LSTM,BiLSTM Can capture the sequence of two-way text information , This feature is consistent with the semantic features of the competition data .
about Decode Part two , We experimented with CTC[14] And popular nowadays Transformer And other models Attention[15] These two ways . Through the experimental results , We found out CTC It performs well in the case of long text , and Attention For short text processing performance is more excellent . In view of the large variance of the text length distribution of the competition data , We tried CTC And Attention Two models .
2.2 Model optimization
2.2.1 Data preprocessing
The data of this competition is text line image , Each of these data has a different size . So , We align the dimensions of all images to ensure the consistency of model input . By analyzing the size distribution of the overall data set , We experimented with different image widths and heights Resize and Padding Two different alignment operations . In the end Padding Alignment mode , Model F1 score promote 3.2%.
2.2.2 Model pre-processing module
The image data of this competition is fuzzy , Low contrast . So , We enhance the image to ensure the clarity of the network input image . We choose to use U-Net[16] The network automatically learns an image enhancement method suitable for the whole model . By comparing with the traditional methods of image saliency and super-resolution network , Adopted U-Net It can adaptively learn image enhancement methods suitable for network learning .

chart 3 U-Net Sketch Map
Besides , Some of the images of this competition show the characteristics of tilting at the text line . Compared to horizontal text , The recognition of slanted text is more challenging . In this case , We have adopted the method of processing slanted text TPS The Internet [17]. The network can predict TPS Necessary for correction K A benchmark , And based on the datum point TPS Transform to generate sampling mesh , Finally, the sampling grid is interpolated bilinear , Achieve the purpose of correcting the text .

chart 4 TPS Sketch Map
Final , Input image data after U-Net Adaptive enhancement and TPS After correction , Model F1 score promote 2.6%.
2.2.3 loss choice
In view of the problem that it is difficult to recognize the similar characters in the task of text recognition , Such as "0" and "O". We took Center Loss[18], The loss function can better distinguish the similar categories by reducing the distance between each classification code and the center of the category to which it belongs . Use Center Loss after , Model F1 score promote 0.6%.
2.2.4 Optimizer selection
As mentioned above , The text line recognition model consists of several parts , At the same time, each part of the learning task from the data field ( Images / Text ) To data format ( Single / Sequence ) There are big differences . So , We chose an adaptive optimizer Adadelta[19] To solve . Use... In the model Adadelta After training to convergence , In the frozen image processing Encoder In case of parameter , Use faster convergence Adam[20] Yes Decoder Some parameters are further trained . After using the above strategy, the model F1 score promote 0.3%.
2.3 Large scale data set pre training model training
In this competition, in addition to using the official 33626 Outside Zhang Training Center , Also through a variety of fonts , Each corpus category ( Numbers / name / sentence ) And various picture styles ( abrasion / tilt / Underline ) The simulation , Generated a data set 5000 Thousands of copies , Use 20 Zhang V100 Video card for distributed training , Based on the pre training model finetune, Model F1 score Has been greatly improved (5.4%), This is also the key for us to win the championship .
2.4 Language error correction model
First , We blend training attention Models and ctc Model . For results with low confidence , We believe that there is a high possibility of identifying errors , You need to use a language model to correct it . adopt 2.5 Of badcase Analysis shows that , Except for space recognition errors , And about 56% Other errors of . So we trained an extra one without spaces attention Identify the model , The recognition result of this model is used to replace the recognition result with low confidence of the original fusion model , Try to avoid the interference of spaces on recognition . then , We are right. soft-masked bert[21] Expanded , stay Bi-GRU[22] In the error detection network, in addition to predicting the probability that each character is a typo , In addition, the probability of adding characters after this character is added . If the prediction is wrong , We will classify the character according to probability embedding And <mask> Of embedding Make a linear combination . If the forecast is to add , Will be added directly after this character <mask> Of embedding. stay bert Error correction network , We added <null> Tags are used to identify characters that need to be deleted . Last , We are based on badcase The analysis of generated 100 Million training data , After using the above strategy ,F1 score Promoted 0.7%.

chart 5 soft-masked bert Sketch Map
2.5 badcase analysis
By adopting 2.1~2.4 The strategy of , Our model has been greatly improved . By verifying the badcase analysis , The main findings are as follows : Space recognition error 、 Equal length sample identification error and unequal length sample identification error . Proportion of each error Pictured 6, The percentage of space recognition errors reached 44%, The other two kinds of errors are equal length and unequal length errors . The following describes the above situations and gives our solutions .

chart 6 badcase Distribution map
First of all , Space recognition error means that the model does not recognize spaces correctly or we recognize spaces as other characters , Here's the picture . In view of this situation, we artificially give many blanks to the corpus . meanwhile , In order to solve the subjectivity of space distance , When we insert spaces into the corpus, we use variable length spaces to let the model learn to control the space distance . Besides , We counted the character distribution before and after the space in the error result of the model prediction , According to this distribution, we can control the insertion position of spaces in the corpus .
![]()
chart 7 Space recognition example
second , Isometric error is the result of model recognition and GT Equal length , But there are some character recognition errors , Accounting for the total recognition error 33%, This kind of error mainly focuses on the situation that it is difficult to correctly recognize the shape near words , Here's the picture .GT by “1 Small Cone”, Our model is identified as “1 Small C0ne”. In order to solve this kind of paired character prediction error , We count the common hard to distinguish character pairs in the character set and the wrong character pairs predicted by our model . In pairs , We replace some characters in a corpus with characters in its hard to distinguish character pairs , Such as "a0c" And "aOc", The corpus before and after replacement are added to our data set . By adding pairs of indistinguishable character corpora , The prediction results of our model greatly reduce the error of character segmentation . Besides , We found that there is less left and right white space in the text line of this data , This makes the model prediction result prone to errors at the beginning and end . So , When we select replacement characters, we will increase the weight of the beginning and end positions .
![]()
chart 8 Isometric recognition error
Third , Unequal length error is the result of model recognition and GT Not equal in length . This mainly focuses on marking errors 、 Text lines are too long and samples are extremely uneven . For the problem that the text line is too long , We select a small number of characters from part of the corpus for artificial repetition and input them into the model training , In this way, the model can obtain certain weight removal ability . For the problem of category imbalance , When we generate corpus to extract characters , Give more weight to low-frequency characters , The occurrence rate of high and low frequency characters has increased to 10:1, More in line with the actual situation of the corpus .
- Summary and prospect
The application of computer vision in the financial field mainly includes face recognition 、 In vivo detection 、OCR、AI Digital people and image tampering . This challenge has proved us to some extent OCR The effectiveness of the algorithm , As well as our existing algorithm for leak detection and filling . at present OCR stay 360 The business scenarios for the internal implementation of the Department mainly include academic certification 、 Practicing certificate certification 、 Note identification 、 Identification of driving license 、 Driver's license identification and business license, etc , In addition, we also developed a matching image anti fraud identification algorithm for the above business scenarios . Looking forward to the future , The computer vision team will keep up with the latest developments in the industry to maintain the progressiveness of technology , To better serve the company's business team .
- quote
[1] Huang Z, Chen K, He J, et al. Icdar2019 competition on scanned receipt ocr and information extraction[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1516-1520.
[2] Y. Sun, J. Liu, W. Liu, J. Han, E. Ding, “Chinese Street View Text: Large-scale Chinese Text Reading with Partially Supervised Learning”, in Proc. of ICCV 2019.
[3] Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusiñol, Ernest Valveny, C.V. Jawahar, Dimosthenis Karatzas, "Scene Text Visual Question Answering", ICCV 2019.
[4] C. Chng, Y. Liu, Y. Sun, et al, “ICDAR 2019 Robust Reading Challenge on Arbitrary-Shaped Text-RRC-ArT”, in Proc. of ICDAR 2019.
[5] Zhang R, Zhou Y, Jiang Q, et al. Icdar 2019 robust reading challenge on reading chinese text on signboard[C]//2019 international conference on document analysis and recognition (ICDAR). IEEE, 2019: 1577-1581.
[6] Nayef N, Patel Y, Busta M, et al. ICDAR2019 robust reading challenge on multi-lingual scene text detection and recognition—RRC-MLT-2019[C]//2019 International conference on document analysis and recognition (ICDAR). IEEE, 2019: 1582-1587.
[7] Shi, Baoguang, Xiang Bai, and Cong Yao. "An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition." IEEE transactions on pattern analysis and machine intelligence 39.11 (2016): 2298-2304.
[8] Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv:1704.04861, 2017.
[9] Tan M, Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks[C]//International conference on machine learning. PMLR, 2019: 6105-6114.
[10] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[11] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[12] Graves A. Long short-term memory[J]. Supervised sequence labelling with recurrent neural networks, 2012: 37-45.
[13] Zhang, Shu, et al. "Bidirectional long short-term memory networks for relation classification." Proceedings of the 29th Pacific Asia conference on language, information and computation. 2015.
[14] Graves A. Connectionist temporal classification[M]//Supervised sequence labelling with recurrent neural networks. Springer, Berlin, Heidelberg, 2012: 61-93.
[15] Sun, Chao, et al. "A convolutional recurrent neural network with attention framework for speech separation in monaural recordings." Scientific Reports 11.1 (2021): 1-14.
[16] Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
[17] Shi, Baoguang, et al. "Robust scene text recognition with automatic rectification." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[18] Wen, Yandong, et al. "A discriminative feature learning approach for deep face recognition." European conference on computer vision. Springer, Cham, 2016.
[19] Zeiler, Matthew D. "Adadelta: an adaptive learning rate method." arXiv preprint arXiv:1212.5701 (2012).
[20] Kingma D P, Ba J. Adam: A method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014.
[21] Zhang S, Huang H, Liu J, et al. Spelling error correction with soft-masked BERT[J]. arXiv preprint arXiv:2005.07421, 2020.
[22] Wang Q, Xu C, Zhou Y, et al. An attention-based Bi-GRU-CapsNet model for hypernymy detection between compound entities[C]//2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 2018: 1031-1035.
边栏推荐
- Software Test Engineer Interview interface test FAQ
- word文档转markdown文档?
- Input系统学习-----InputFilter
- Paper notes: multi label learning ackel
- What does the maturity and redemption time of financial products mean?
- 数组常用方法
- Mobile app test method
- LeetCode 513 找树左下角的值[BFS 二叉树] HERODING的LeetCode之路
- zap语法糖
- Common shortcut keys in Excel summary of shortcut keys in Excel
猜你喜欢
![[Chapter 20 video target detection based on inter frame difference method -- Application of MATLAB software in-depth learning]](/img/40/0d2d4c74b4b2cc2292450d9940e998.png)
[Chapter 20 video target detection based on inter frame difference method -- Application of MATLAB software in-depth learning]

MATLAB 学习笔记(5)MATLAB 数据的导入和导出

微信小程序影视评论交流平台系统毕业设计毕设(8)毕业设计论文模板

FPGA-Xilinx 7系列FPGA DDR3硬件设计规则

微信小程序影视评论交流平台系统毕业设计毕设(7)中期检查报告
![LeetCode 513 找树左下角的值[BFS 二叉树] HERODING的LeetCode之路](/img/15/b406e7bf1b83cbdd685c8cde427786.png)
LeetCode 513 找树左下角的值[BFS 二叉树] HERODING的LeetCode之路
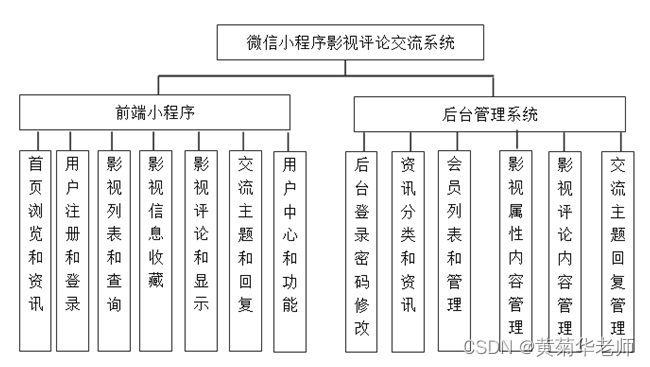
Wechat applet film and television review and exchange platform system graduation design (1) development outline

快速学会CAD绘制传输线路图纸

Introduction to excellent verilog/fpga open source project (XXVII) - small CPU
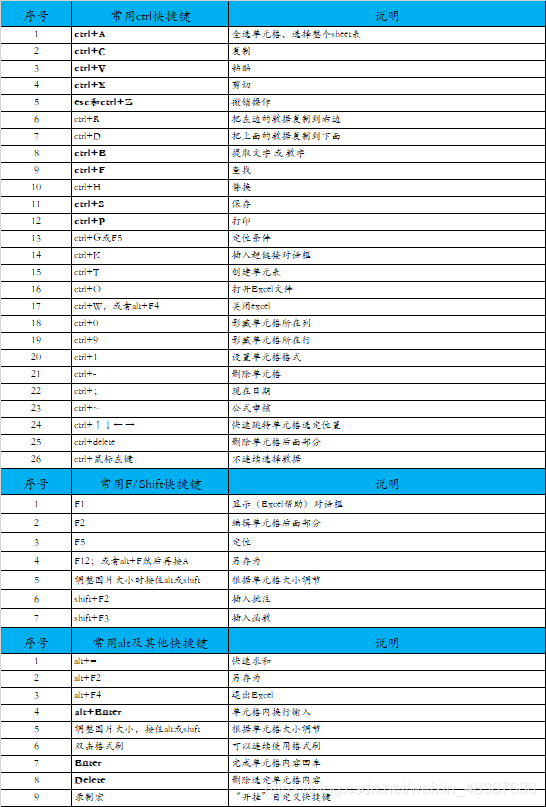
Common shortcut keys in Excel summary of shortcut keys in Excel
随机推荐
MATLAB 学习笔记(4)MATLAB 数组
MySQL 递归查找树形结构,这个方法太实用了!
基于xposed框架hook使用
微信小程序影视评论交流平台系统毕业设计毕设(3)后台功能
使用 OKR 進行 HR 數字化轉型
Learn to crawl steadily 08 - detailed explanation of the use method of selenium
Wechat applet film and television review and exchange platform system graduation design completion (7) Interim inspection report
Appium interview questions
C# 判断应用是否启动并展示
Games-101 personal summary transformation
回到成都开启我的软件测试职业生涯
word文档转markdown文档?
手机app测试方法
rt_ Message queue of thread
Rational Rose installation tutorial
Wechat applet Film & TV Review Exchange Platform System Graduation Design (4) Rapport d'ouverture
Create RT_ Thread thread
excel常用快捷键excel快捷键汇总
微信小程序影视评论交流平台系统毕业设计毕设(8)毕业设计论文模板
Atguigu---- list rendering